This Artificial Intelligence (AI) Research Examines the Differences Between Transformers and ConvNets Using Counterfactual Simulation Testing

In the last decade, convolutional neural networks (CNNs) have been the backbone of computer vision applications. Traditionally, computer vision tasks have been tackled using CNNs, designed to process data with a grid-like structure, such as an image. CNNs apply a series of filters to the input data, extracting features such as edges, corners, and textures. Subsequent layers then process these features in the network, which combine them to form more complex features and eventually make a prediction.
The success saga of CNNs started around 2012 with the release of AlexNet and its extremely impressive performance in object detection. After that, people put lots of effort into making them even better and applied them in multiple domains.
The dominance of CNNs has been rivaled recently with the introduction of the vision transformer (ViT) structure. ViT has shown impressive results in object detection performance, even surpassing state-of-the-art CNNs. Though, the competition between CNNs and ViTs is still ongoing. Depending on the task and the dataset, one outperforms the other, and if we change the test environment, the results change.
ViT brings the power of transformers to the field of computer vision by treating images as a sequence of patches rather than a grid of pixels. These patches are then processed using the same self-attention mechanisms as in NLP transformers, allowing the model to weigh the importance of different patches based on their relationship to other patches in the image.

One of the key advantages of ViT is that it is much more efficient than CNNs, as it does not require the computation of convolutional filters. This makes training easier and allows for larger models, which can improve performance. Another advantage of ViT is that it is much more flexible than CNNs. Since it processes data as a sequence rather than a grid, it can handle data of any size and aspect ratio without requiring any additional preprocessing. This is in contrast to CNNs, which require the input data to be resized and padded to fit a fixed-size grid.
Of course, people wanted to understand the real advantages of ViTs over CNNs, and there have been many studies about it recently. However, there is a common issue in all those comparisons, more or less. They try to compare ViTs and CNNs using ImageNet accuracy as the metric. However, they do not consider that the ConvNets being compared may be using slightly outdated design and training techniques.
So, how can we make sure we make a fair comparison between ViTs and CNNs? We need to be sure we only compare structural differences. Well, researchers of this paper have identified how the comparison should be, and they describe it as follows: “We believe that studying the differences that arise in learned representations between Transformers and ConvNets to natural variations such as lighting, occlusions, object scale, object pose, and others is important.”
This is the main idea behind this paper. But how could one achieve the environment to make this comparison? There were two main obstacles that prevented this comparison. First, Transformer and ConvNet architectures were not comparable in terms of overall design techniques and training convolutional layer differences. Second, the scarcity of datasets that include fine-grained naturalistic variations of object scale, object pose, scene lighting, and 3D occlusions, among others.
The first problem was solved by comparing ConvNext CNN with a Swin transformer architecture; the only difference between these networks is the usage of convolutions and transformers.
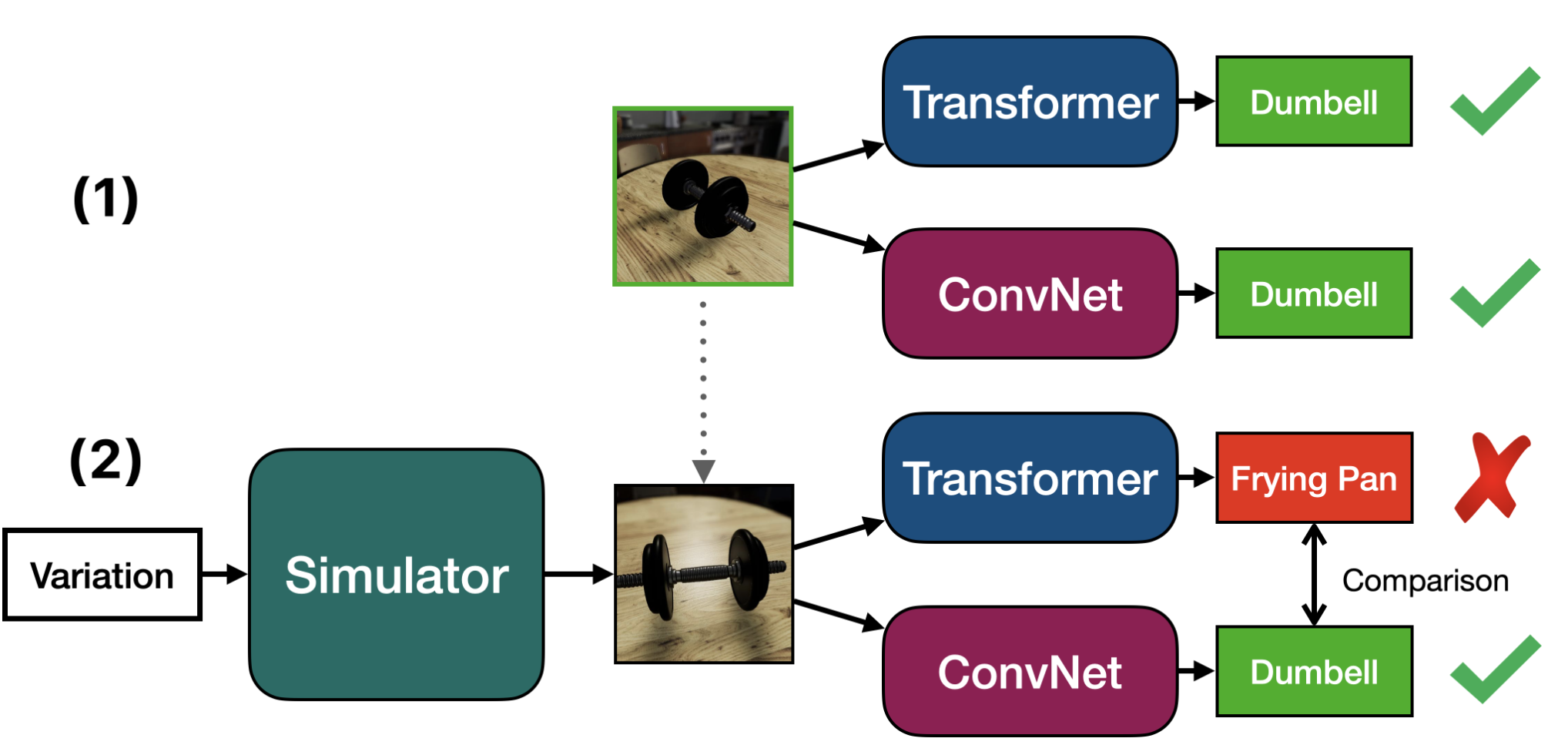
The main contribution of this paper is about solving the second problem. They devise a solution to test the architectures in a counterfactual manner using simulated images. They constructed a synthetic dataset, named Naturalistic Variation Object Dataset (NVD), that includes different modifications to the scene.
Counterfactual simulation is a method of reasoning about what might have happened in the past or what might happen in the future under different conditions. It involves considering how the outcome of an event or sequence of events might have been different if one or more of the factors that contributed to the outcome had been different. So, in our context, it explores the outcome of the network if we change the object pose, scene lighting, 3D occlusions, etc. Would the network still predict the correct label for the object?
The results showed that ConvNext was consistently more robust than Swin regarding handling variations in object pose and camera rotations. Moreover, they also found that ConvNext tended to perform better than Swin in recognizing small-scale objects. However, when it came to handling occlusion, the two architectures were roughly equivalent, with Swin slightly outperforming ConvNext in cases of severe occlusion. On the other hand, both architectures struggled with naturalistic variations in the test data. It was observed that increasing the network size or the diversity and quantity of the training data led to improved robustness.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.