Salesforce Open-Sources ‘WarpDrive’, A Light Weight Reinforcement Learning (RL) Framework That Implements End-To-End Multi-Agent RL On A Single GPU

When it comes to AI research and applications, multi-agent systems are a frontier. They have been used for engineering challenges such as self-driving cars, economic policies, robotics, etc. In addition to this, they can be effectively trained using deep reinforcement learning (RL). Deep RL agents have mastered Starcraft successfully, which is an example of how powerful the technique is.
But multi-agent deep reinforcement learning (MADRL) experiments can take days or even weeks. This is especially true when a large number of agents are trained, as it requires repeatedly running multi-agent simulations and training agent models. MADRL implementations often combine CPU simulators with GPU deep learning models; for example, Foundation follows this pattern.
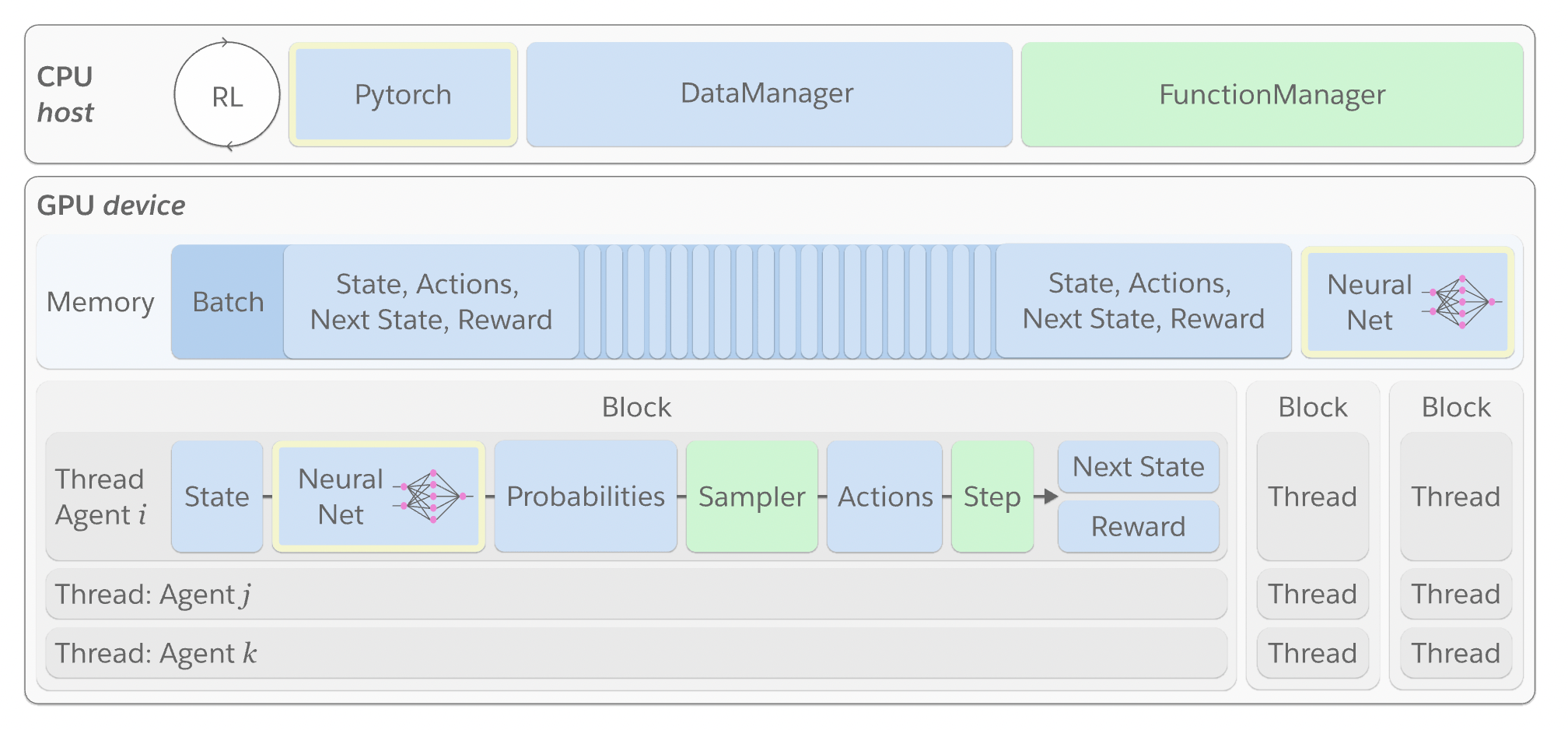
A number of issues limit the development of the field. For example, CPUs do not parallelize computations well across agents and environments, making data transfers between CPU and GPU inefficient. Therefore, Salesforce Research has built ‘WarpDrive’, an open-source framework to run MADRL on a GPU to accelerate it. WarpDrive is extremely fast and orders of magnitude faster than traditional training methods, which only use CPUs.

WarpDrive is an easy-to-use Python API that allows users to access low-level GPU data structures, like Pytorch Tensors and primitive GPUs. WarpDrive uses the well-known library PyCUDA for you to easily communicate between Python, CUDA C++ code, and your favorite deep learning framework (like PyTorch).
The research makes it possible for the RL agents and their respective models to undergo training on GPUs while still interacting with simulations running concurrently through shared Pytorch Tensors.

WarpDrive currently runs each environment in a CUDA block that uses the same simulation logic. Each CUDA thread simulates one agent. The agents can use different neural network models to interact with other agents within the shared memory space of all threads operating inside a single block.
Key points:
- WarpDrive is capable of simulating thousands of environments at once, using GPUs to parallelize the workload.
- WarpDrive eliminates communication between CPU and GPU.
- WarpDrive has eliminated copying of data within the GPU, meaning that Pytorch and CUDA C simulations can read and write to the same data structures.
- WarpDrive is compatible with Pytorch, a deep learning framework that allows you to create very flexible and fast models.
Benchmarking WarpDrive with the Tag environment, researchers compared performance when using CPU simulations and GPU agent models versus running purely on an NVIDIA Tesla V100 GPU.

WarpDrive allows you to run and train across many RL( reinforcement learning) environments at once. This approach speeds up MADRL training by orders of magnitude, making research more efficient. WarpDrive also provides tools for accelerating development with this framework.
Codes: https://github.com/salesforce/warp-drive
Paper: https://arxiv.org/pdf/2108.13976.pdf
Source: https://blog.einstein.ai/warpdrive-fast-rl-on-a-gpu/
Suggested
Credit: Source link
Comments are closed.