This Artificial Intelligence (AI) Research Explores The Expressivity Gap Between State Space Models And Transformer Language Model Attention Mechanisms
State-space models (SSMs) are models created to represent dynamic systems using state variables. These models primarily work with time-series data and use a collection of first-order differential equations to describe a system. With recent technological advancements, SSMs have achieved remarkable performance in domains like financial research and time series forecasting. However, one area where they fall short of expectations involves language modeling tasks, as they cannot match the performance of transformer systems. SSMs are also slower than Transformers, despite even scaling approximately linearly rather than quadratically for sequence length. Researchers believe that the primary cause behind this is hardware underutilization.
Researchers from Stanford University collaborated with the State University of New York at Buffalo in an effort to comprehend and close this gap between SSMs and transformer language model attention mechanisms. The team documented the results of their investigation in the recent paper, ‘Hungry Hungry Hippos: Towards Language Modeling using State Space Models.’ They also studied various methods to lower the hardware barrier between SSMs and attention and came up with a novel state-passing algorithm called FlashConv, which achieves 2x speedups on the Long Range Arena benchmark and enables 1.6x faster text generation than conventional transformer architectures.
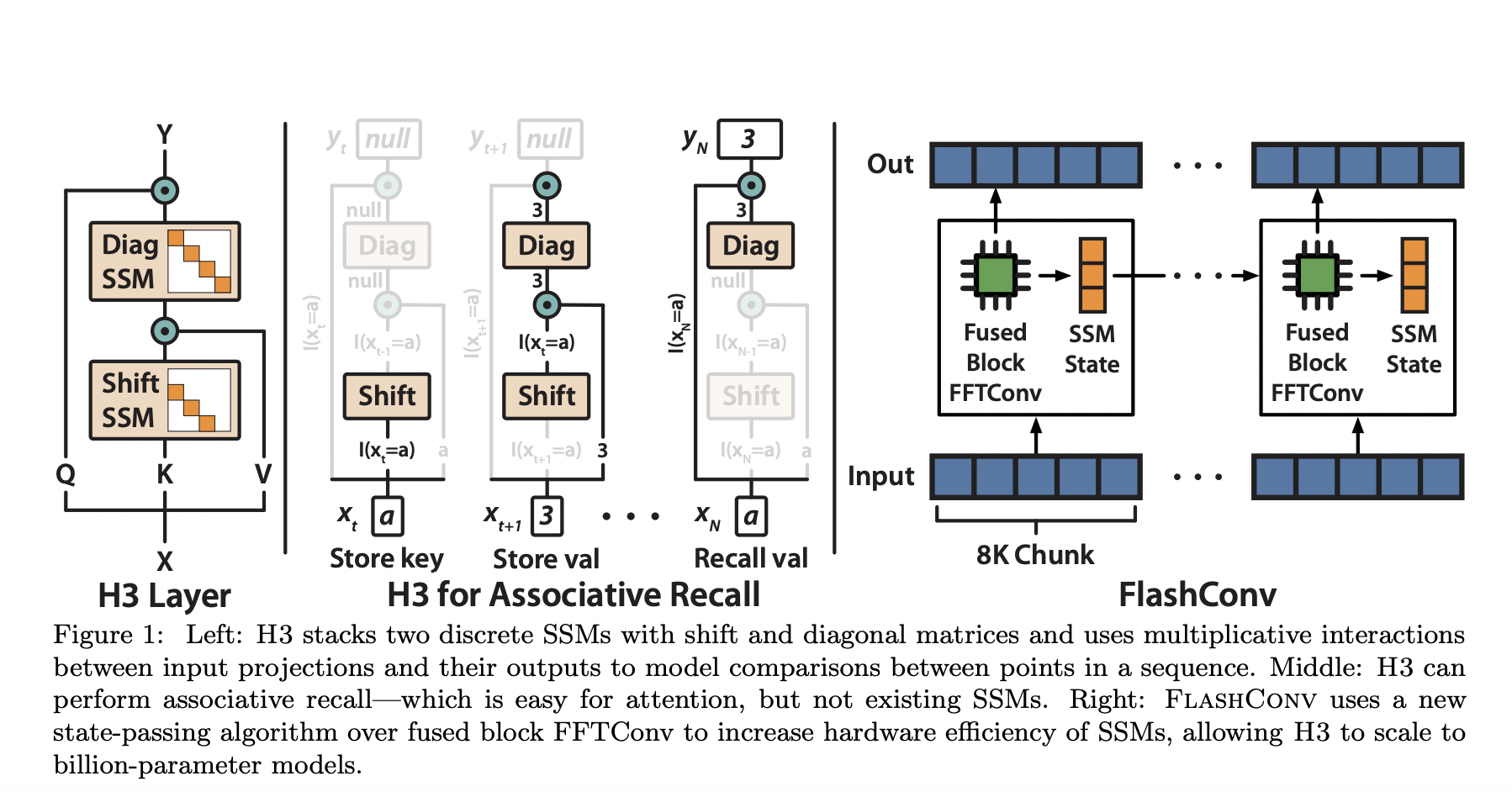
The two key features existing SSMs struggle with are remembering previously encountered tokens and comparing tokens between sequences. The team used synthetic language modeling tasks focused on text manipulation to identify these expressivity gaps between SSMs and attention. The team contributed significantly to creating a new SSM layer termed Hungry Hungry Hippo (H3) as an alternative to attention in language modeling. The proposed H3 layer stacks two discrete SSMs with multiplicative interactions between input projections and the corresponding outputs to simulate comparisons between different points in a sequence. H3 compares favorably to Transformers on OpenWebText in terms of perplexity and matches attention on synthetic languages. Additionally, on the OpenWebText benchmark, a hybrid H3-attention model outperforms transformers by 1.0 PPL (perplexity).
The researchers also suggested FlashConv, a hierarchical approach, as a superior hardware-aware technique for SSMs. The algorithm was designed to enable SSMs to utilize contemporary accelerators and function more quickly than attention. FlashConv uses the FFT (fast Fourier transform) algorithm to enhance efficiency on text sequences. Inputs can be divided into smaller pieces to fit into GPU SRAM for effective computation by taking advantage of the recurring qualities of SSMs to process the input in chunks. As a result, FlashConv can scale SSMs on GPU SRAM to any sequence length with nearly linear computational complexity.
After several experimental evaluations, the team concluded that FlashConv set a new state-of-the-art speed record on the long range arena benchmark by yielding a 2x speedup. Additionally, the team scaled hybrid H3-attention language models with up to 1.3B parameters using FlashConv. These models excelled on most SuperGLUE benchmark tasks using zero- and few-shot learning. The scaling of SSMs to larger sizes is a potential approach, the researchers concluded as a result. The researchers are eager to continue combining the complementing qualities of SSMs and attention in their future work. This was primarily due to their performance gains over the pure H3 model and Transformers by simply combining two attention layers to H3. The researchers are eager to investigate more sophisticated designs for combining SSMs.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.