Meet DiffusionDet: An Artificial Intelligence (AI) Model That Uses Diffusion for Object Detection
Object detection is a powerful technique for identifying objects in images and videos. Thanks to deep learning and computer vision advances, it has come a long way in recent years. It has the potential to revolutionize a wide range of industries, from transportation and security to healthcare and retail. As the technology continues to improve, we can expect to see even more exciting developments in the field of object detection.
One of the key challenges in object detection is the ability to accurately localize objects in an image. This involves identifying that an object is present and determining its precise location and size.
Most object detectors use a combination of regression and classification techniques to identify objects in images. This is typically done by looking at specific areas of the image, like sliding windows or region proposals, and using these as “guides” to help identify objects. Other methods, like anchor boxes or reference points, can also help with object detection.
Although these techniques for object detection are relatively straightforward and effective, they rely on a fixed set of predetermined search criteria. One needs to define a set of candidate objects most of the time. However, it can be cumbersome to define all these predetermined criteria. Is there a way to simplify the process even further without the need for these predetermined search guidelines?
The answer from researchers in Tencent was proposing the DiffusionDet, a diffusion model to be used in object detection.
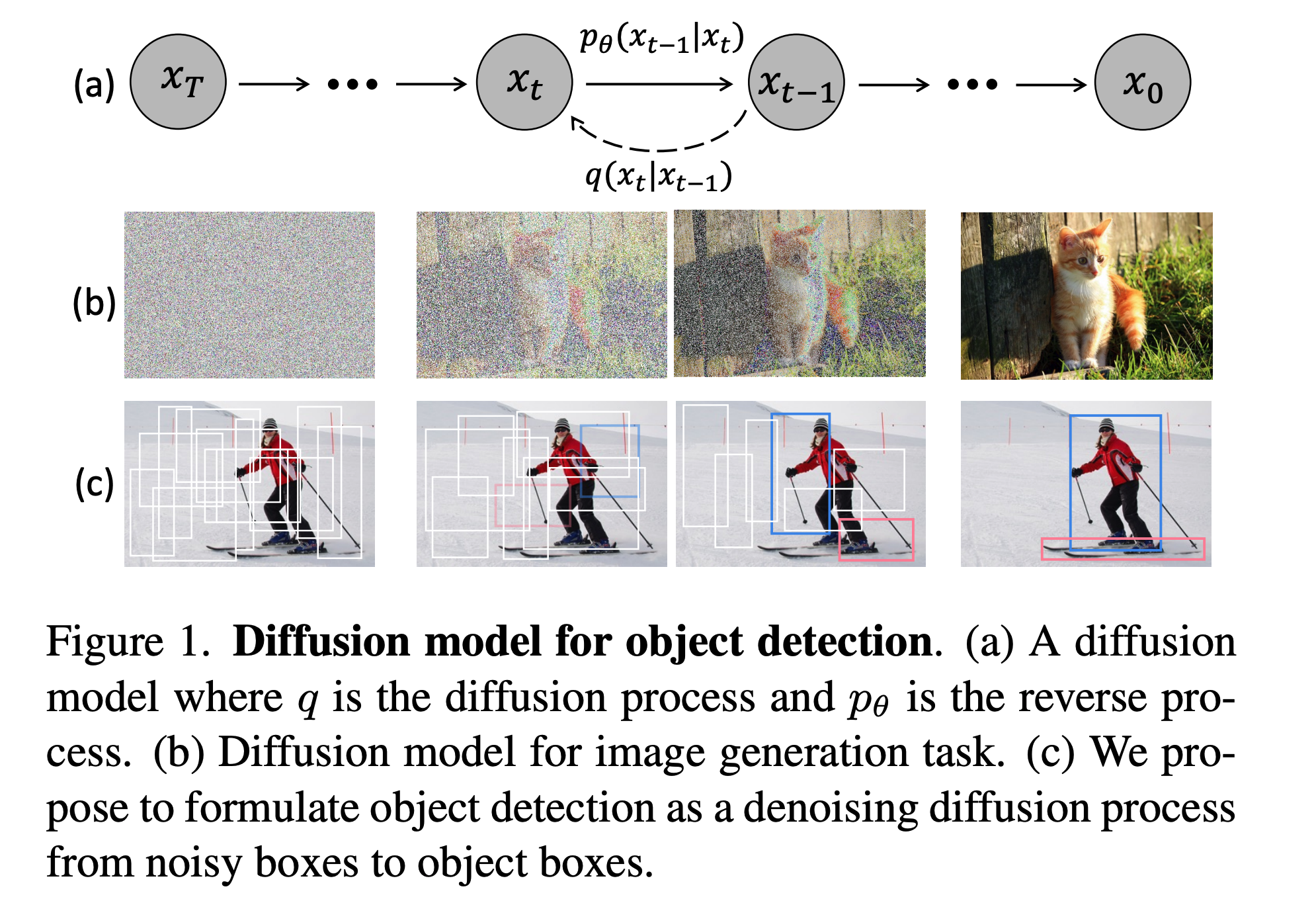
Diffusion models have been the attention center for the AI community in the last couple of months, mainly thanks to the public release of the Stable Diffusion model. To simply explain, diffusion models take input as noise and gradually denoise it, following certain rules until a desirable output is obtained. In the context of stable diffusion, the input was a noise image obtained by the text prompt, and it is denoised slowly until a similar image to the given text prompt is obtained.
So, how can the diffusion approach be used for object detection? We are not interested in generating something new; instead, we want to know the objects in a given image. How did they do it?
In DiffusionDet, a novel framework has been designed for detecting objects directly from a set of random boxes. These boxes, which do not contain learnable parameters that need to be optimized during training, are expected to have their positions and sizes gradually refined until they accurately cover the targeted objects through the noise-to-box approach.
Think of the boxes as the input noise, and the constraint here is they should contain an object. So, in the end, we want to get a set of boxes that contain different objects. The denoising step is gradually changing the boxes’ sizes and positions. Heuristic object priors and learnable queries are not required in this approach, which simplifies the identification of object candidates and advances the development of the detection pipeline.
DiffusionDet thinks of object detection as a generative task involving the positions and sizes of bounding boxes in an image. During training, noise controlled by a variance schedule is added to the ground truth boxes to create noisy boxes, which are then used to crop features from the output feature map of the backbone encoder. These features are then sent to the detection decoder, which is trained to predict the ground truth boxes without noise. This allows DiffusionDet to predict the ground truth boxes from random boxes. At inference time, DiffusionDet generates bounding boxes by reversing the learned diffusion process and adjusting a noisy prior distribution to the learned distribution over bounding boxes.
Check out the Paper and Code. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.