Researchers From Allen Institute for AI Introduce TeachMe: A Framework To Understand And Correct AI Models
Until recently, the results of AI models were kept secret. Even if researchers know the dataset a model was trained on, they may still have questions regarding the data the model used to respond to a query or provide an output. But what if a model could demonstrate its efforts by clearly explaining the steps it took to arrive at a certain result, and the user could then provide feedback on whether or not the model’s logic was sound?
At AI2, a group of scientists working on the Aristo project wanted to create a trainable reasoning system with two specific features.
TeachMe is the suggested system, which consists of two key parts:
(1) Entailer, a T5-based machine reasoning model that can generate valid lines of reasoning
(2) a dynamic database of previous comments
Entailer
Include Previously Taught Words and Phrases. In this way, models are a kind of knowledge source from which to draw. In this case, however, the researchers’ method articulates this tacit knowledge in a goal-directed fashion by generating a logically sound argument based on evidence it verifies as true to arrive at a certain conclusion. Entailer, the proposed model, builds multi-stage reasoning chains by combining generation and verification. Entailer produces many more possible entailments than it needs for each step. It then eliminates those that don’t satisfy its internal knowledge by questioning whether each created premise is true and whether each entailment step is valid. The proof then backtracks through its premises until the confidence in the proof as a whole can no longer increase. When all else fails, the candidate’s response backed by the strongest argument chain is returned. Therefore, the system has actualized some of its latent information, ultimately leading to the chosen reaction. Most importantly, the ensuing evidence is both reliable and honest, giving insight into the model’s worldview and its consequences that we wouldn’t have had otherwise.
TeachMe
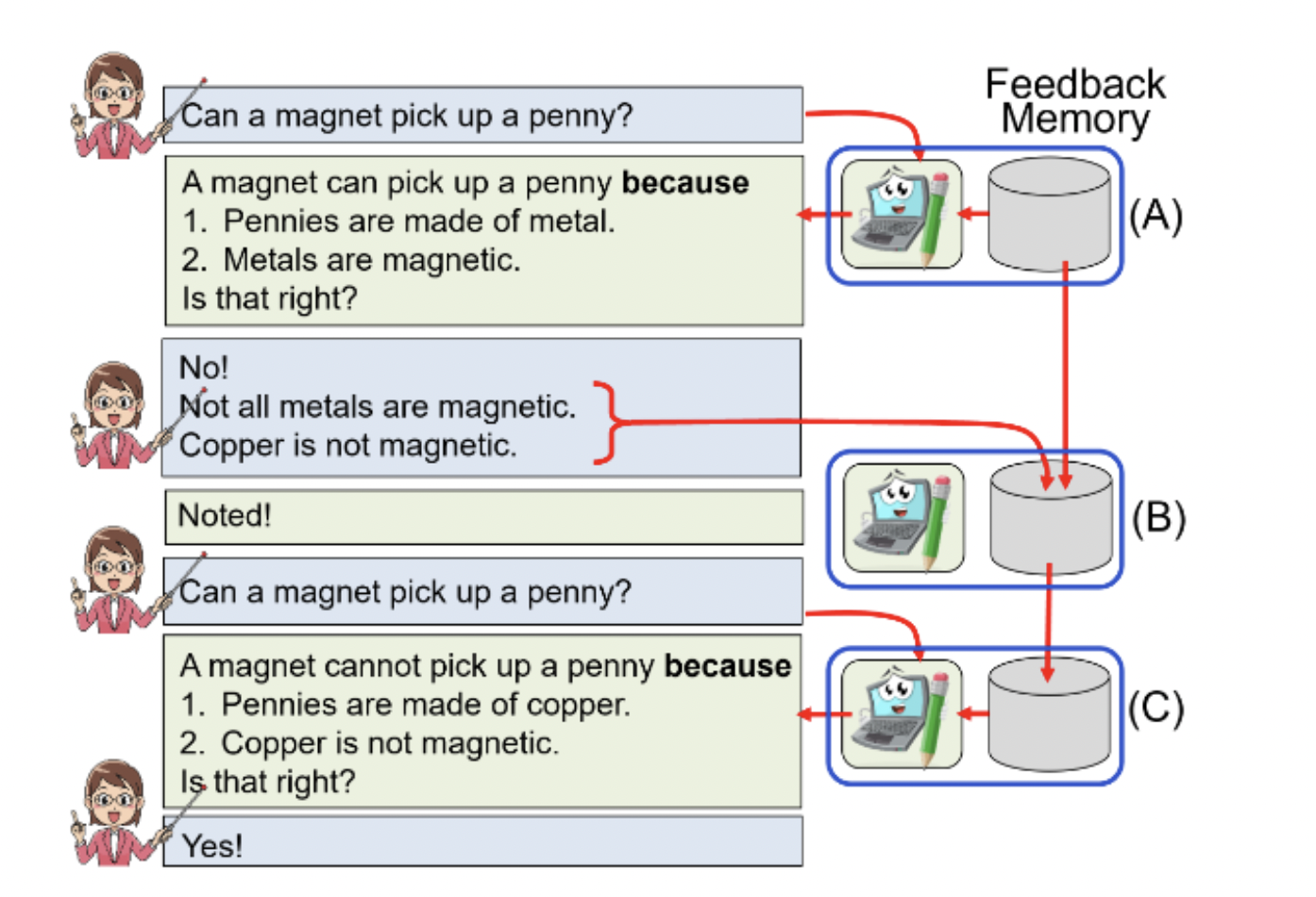
Whenever pressed, most people can articulate a coherent line of thought leading up to their conclusions, and they are open to revising those conclusions in light of new information or evidence. Similarly, researchers aim to have robots deliver reasoned replies to queries, elaborating on how the answer derives from its internal knowledge and indicating where it might modify its solution if flaws in that information are detected. There are three parts to the strategy. The system first generates answers backed up by a logical chain of entailment that demonstrates how the answer follows from the system’s presuppositions. Second, if a response is incorrect, the user can check the logic to figure out why. And finally, we add a dynamic memory to the model so that it can remember and act upon the user’s input. TeachMe uses this memory to look up information its users have previously provided when a new question or a related topic is rephrased. These are then considered while an entailment-based response to the query is constructed. This is a novel application of memory-based continuous learning to belief maintenance, in which the model remains constant (frozen), and retraining is unnecessary. It aids TeachMe in overriding previous, erroneous model beliefs, thus biassing it to avoid similar mistakes in the future.
Until now, no system has been able to construct multi-step chains that are honest and faithful, meaning that the response follows logically from the reasoning. The outcomes entailer is the first to do so. Users judge that more than 70% of created chains, relative to a high-performance baseline, effectively demonstrate how an answer flows from a set of facts, all while maintaining response accuracy, in an evaluation utilizing two different datasets. The ability to interact with a model in which users can grasp its ideas and correct misunderstandings when a response is inaccurate is greatly facilitated by the materialization of the model’s beliefs to justify an answer systematically.
To get within 1% of the upper bound, TeachMe needs input on 25% of training samples, and it gets better over time without needing to retrain the model (feedback on all examples). The same pattern is seen in user experiments, with results showing a 15% improvement in performance following instructions on a secret test set. These findings point to promising new avenues for employing frozen language models in an interactive situation. Users may analyze, debug, and modify the model’s beliefs, leading to better system performance.
Context and Conclusion
Embedding an entailment-based QA model into a broader system with a dynamic, persistent memory allows users to correct and override model beliefs, leading to an overall system that can improve over time without retraining, as demonstrated by the research team. This is the first system to demonstrate the feasibility of combining user-provided and model-internal beliefs for systematic inference. This is a big deal because it shows promise for creating systems that can communicate with people and adapt to their needs over time.
It also provides a potential solution to the mystery of neural networks: seeing models as part of a more comprehensive system that stores information indefinitely and uses it to reason systematically.
Check out the Paper and Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.