Latest Artificial Intelligence (AI) Research Suggests Few-Shot Prompting LLMs May Be More Similar To Fine-Tuning Than Realized

Since the release of OpenAI’s ChatGPT, large language models (LLM), neural networks trained on enormous text corpora, and other sorts of data have gained much attention in the artificial intelligence industry. On the one hand, huge language models are capable of amazing feats, producing lengthy texts that are mostly coherent and giving the appearance that they have mastered both human language and its fundamental abilities. On the other hand, several experiments demonstrate that LLMs are simply repeating their training data and only displaying impressive results due to their extensive text exposure. They fail as soon as they are given tasks or problems that call for reasoning, common sense, or implicitly learned skills. ChatGPT frequently needs help to figure out straightforward math issues.
However, more and more people realize that if you give the LLMs well-crafted cues, you can direct them toward responding to inquiries requiring reasoning and sequential thought. This type of prompting, known as “zero-shot chain-of-thought” prompting, employs a specific trigger word to compel the LLM to follow the steps necessary to solve an issue. And even though it’s straightforward, the approach usually appears to succeed. Zero-shot CoT shows that if you know how to interrogate LLMs, they will be better positioned to deliver an acceptable answer, even though other researchers dispute that LLMs can reason.

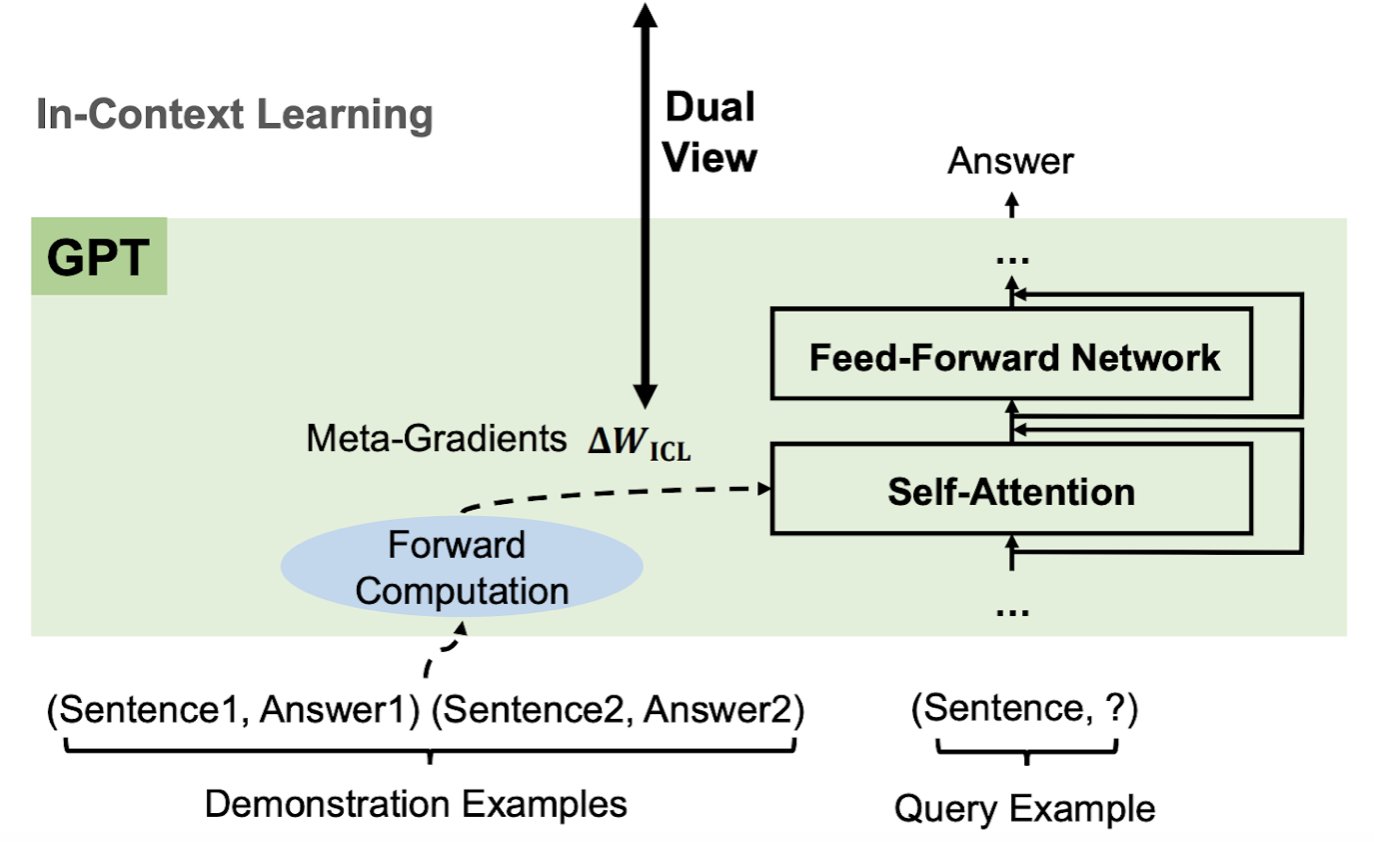
Large pretrained language models have recently demonstrated strong emergent In-Context Learning (ICL) capability, particularly in Transformer-based architectures. ICL requires a few demonstration instances to be prepended before the first input; unlike finetuning, which requires extra parameter updates, the model can then predict the label for even unknown inputs. A big GPT model can do pretty well on many downstream tasks, even outperforming certain smaller models with supervised fine-tuning. ICL has excelled in performance, but there is still room for improvement in understanding how it operates. Researchers seek to establish links between GPT-based ICL and finetuning and attempt to explain ICL as a meta-optimization process.
They discover that the Transformer attention has a secondary type of gradient descent-based optimization by focusing on the attention modules. Additionally, they offer a fresh viewpoint to understand ICL: To create an ICL model, a pretrained GPT functions as a meta-optimizer, develops meta-gradients based on demonstration examples through forward computation and then applies the meta-gradients to the original language model through attention. ICL and explicit finetuning share a dual perspective of optimization based on gradient descent. The sole distinction between the two is that whereas finetuning computes gradients via back-propagation, ICL constructs meta-gradients by forward computing.
It seems sensible to think of ICL as a type of implicit tuning. They conduct extensive experiments based on actual tasks to offer empirical data to support their view. They contrast pretrained GPT models in the ICL and finetuning settings on six categorization tasks regarding model predictions, attention outputs, and attention scores. At every prediction level, representation level, and attention behavior level, ICL behaves in a manner that is very close to explicit finetuning. These findings support their rationale for believing that ICL engages in unconscious finetuning.
Additionally, they make an effort to develop models by utilizing their knowledge of meta-optimization. To be more precise, they create momentum-based attention that treats the attention values as meta-gradients and incorporates the momentum mechanism into it. Their momentum-based attention regularly beats vanilla attention, according to experiments on both language modeling and in-context learning, which supports their knowledge of meta-optimization from yet another angle. Their knowledge of meta-optimization may be more useful for model creation than just this first application, which is worth further research.
👉 Check out Paper 1 and Paper 2. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join 🔥 our Reddit Page, Discord Channel, and 🚀 Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.