Box2Mask: A Unique Method for Single-Shot Instance Segmentation that Combines Deep Learning with the Level-Set Evolution Model to Provide Accurate Mask Predictions with only Bounding Box Supervision
Instance segmentation, useful in applications like autonomous driving, robotic manipulation, picture editing, cell segmentation, etc., tries to extract the pixel-wise mask labels of the interested objects. Instance segmentation has made significant strides in recent years because of the powerful learning capabilities of sophisticated CNN and transformer systems. However, many of the available instance segmentation models are trained using a fully supervised approach, which strongly relies on the pixel-level annotations of the instance mask and results in high and time-consuming labeling costs. Box-supervised instance segmentation, which uses simple and label-efficient box annotations rather than pixel-wise mask labels, has been offered as a solution to the abovementioned issue. Box annotation has recently gained a lot of academic interest and makes instance segmentation more accessible for new categories or scene types. Some techniques have been developed that use additional auxiliary salient data or post-processing techniques like MCG and CRF to produce pseudo labels to enable pixel-wise supervision with box annotation. These approaches, however, require several independent stages, complicating the training pipeline and adding more hyper-parameters to adjust. On COCO, generating an object’s polygon-based mask typically takes 79.2 seconds, yet annotating an object’s bounding box only takes 7 seconds.
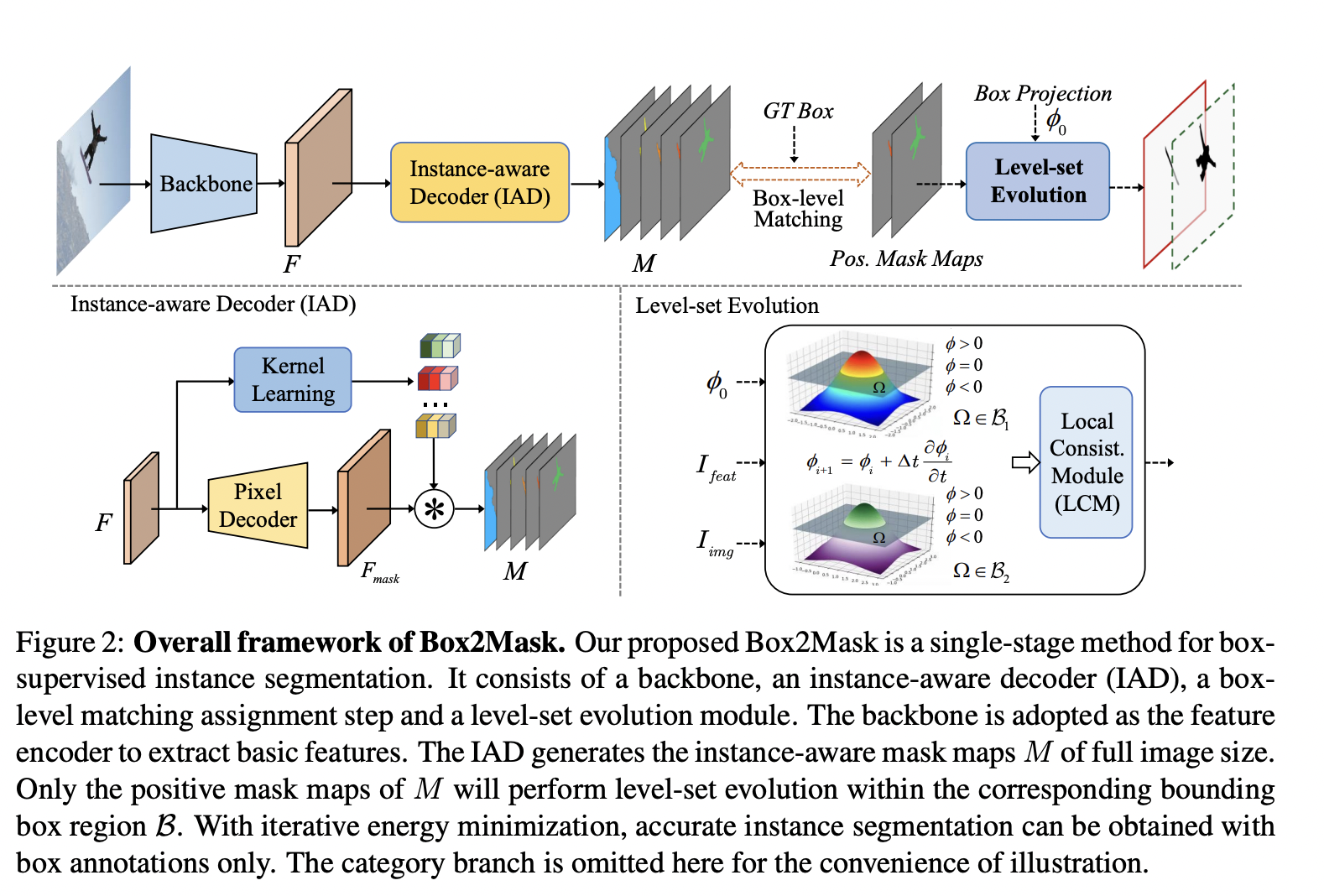
The standard level-set model, which implicitly uses an energy function to represent the object boundary curves, is used in this study to investigate more reliable affinity modeling techniques for efficient box-supervised instance segmentation. The level-set-based energy function has shown promising picture segmentation results by utilizing rich context information such as pixel intensity, color, appearance, and shape. However, the network is trained to forecast the object boundaries with pixel-wise supervision in these approaches, which carry out level-set evolution in a completely mask-supervised way. In contrast to previous methods, the goal of this study is to monitor level-set evolution training using simply bounding box annotations. They specifically suggest a brand-new box-supervised instance segmentation method called Box2Mask that gently combines deep neural networks with the level-set model to train several level-set functions for implicit curve development repeatedly. Their approach makes use of the conventional continuous Chan-Vese energy function. They use low-level and high-level information to develop the level-set curves toward the object’s boundary reliably. An automated box projection function that offers an approximate estimate of the desired boundary initializes the level set at each stage of the evolution. To assure the level-set development with local affinity consistency, a local consistency module is created based on an affinity kernel function that mines the local context and spatial connections.
They provide two single-stage framework types—a CNN-based framework and a transformer-based framework—to support the level-set evolution. Each framework also includes two more crucial elements, instance-aware decoders (IADs) and box-level matching assignments, which are outfitted with various methodologies in addition to the level-set evolution section. The IAD learns to embed the instance-wise characteristics to construct a full-image instance-aware mask map as the level-set prediction based on the input target instance. Using ground truth bounding boxes, the box-based matching assignment learns to identify the high-quality mask map samples as the positives. Their conference paper detailed the initial findings of their research. They begin by converting their approach in this expanded journal edition from the CNN-based framework to the transformer-based framework. They implement a box-level bipartite matching method for label assignment and integrate instance-wise features for dynamic kernel learning using the transformer decoder. By minimizing the differentiable level-set energy function, the mask map of each instance may be iteratively optimized inside its corresponding bounding box annotation.
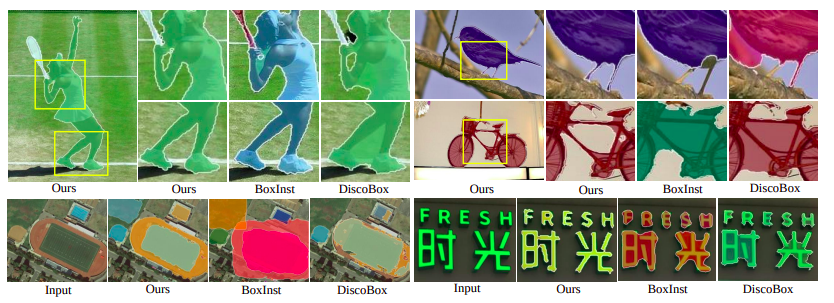
Additionally, they create a local consistency module based on an affinity kernel function, which mines the pixel similarities and spatial linkages inside the neighborhood to relieve the region-based intensity inhomogeneity of level-set evolution. On five difficult testbeds, extensive tests are carried out, for example, segmentation under several circumstances, such as general scenes (such as COCO and Pascal VOC), remote sensing, medical, and scene text pictures. The best quantitative and qualitative outcomes show how successful their suggested Box2Mask approach is. In particular, it enhances the prior state-of-the-art 33.4% AP to 38.3% AP on COCO with ResNet-101 backbone and 38.3% AP to 43.2% AP on Pascal VOC. It outperforms certain common, completely mask-supervised techniques using the same basic framework, such as Mask R-CNN, SOLO, and PolarMask. Their Box2Mask can get 42.4% mask AP on COCO with the stronger Swin-Transformer large (Swin-L) backbone, comparable to the previously well-established fully mask-supervised algorithms. Several visual comparisons are displayed in the figure below. One can observe that their method’s mask predictions often have a greater quality and detail than the more modern BoxInst and DiscoBox techniques. The code repository is open-sourced on GitHub.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.