Meet GeoCode: An Artificial Intelligence Technique For 3D Shape Synthesis Using An Intuitively Editable Parameter Space
The rapid increase of computational power and accessibility of computations have enabled a wide range of applications in computer vision and graphics. As a result, it is now possible to perform complex tasks like object detection, facial recognition, and 3D reconstruction in a short amount of time. Especially in the 3D domain, advancements in computer vision and graphics have allowed for the development of computer-based games, proof-of-concept 3D movies and animation, and options for virtual and augmented reality experiences. Furthermore, many applications in computer vision and graphics are close to being or have already been addressed with the help of deep learning and artificial intelligence.
These methods are based on artificial neural networks, which are used to learn complex patterns in data. Deep learning networks are hierarchical, meaning they are composed of multiple layers, with each layer learning a certain pattern. The learning process can be either supervised, meaning that labeled data is used to train the model, or unsupervised, which means that no labeled data is given for the training process. Once trained, the model can make predictions about data it has not seen before. In this sense, prediction is not strictly limited to the definition of its term. It relates to a large number of operations like object detection, object/entity classification, multimedia generation, point cloud compression, and much more.
Using these neural networks to address problems in the 3D domain can be tricky, as it requires more computational power and attention than in the 2D domain. One important task is related to 3D editing and the human interpretability of geometric parameters.
Easing the 3D editing or customization process can be important for gaming or computer graphics applications. People interested in gaming probably know the detail of the customization that some editors can provide while creating a personalized avatar in games, from sport to action. Have you ever wondered how much time it takes to set up all these characteristics on the developer’s side? Defining all those characteristics can take weeks or, worst case, months.
Good news comes from research work presented in this article which shines a light on this problem and proposes a solution to automatize this process.
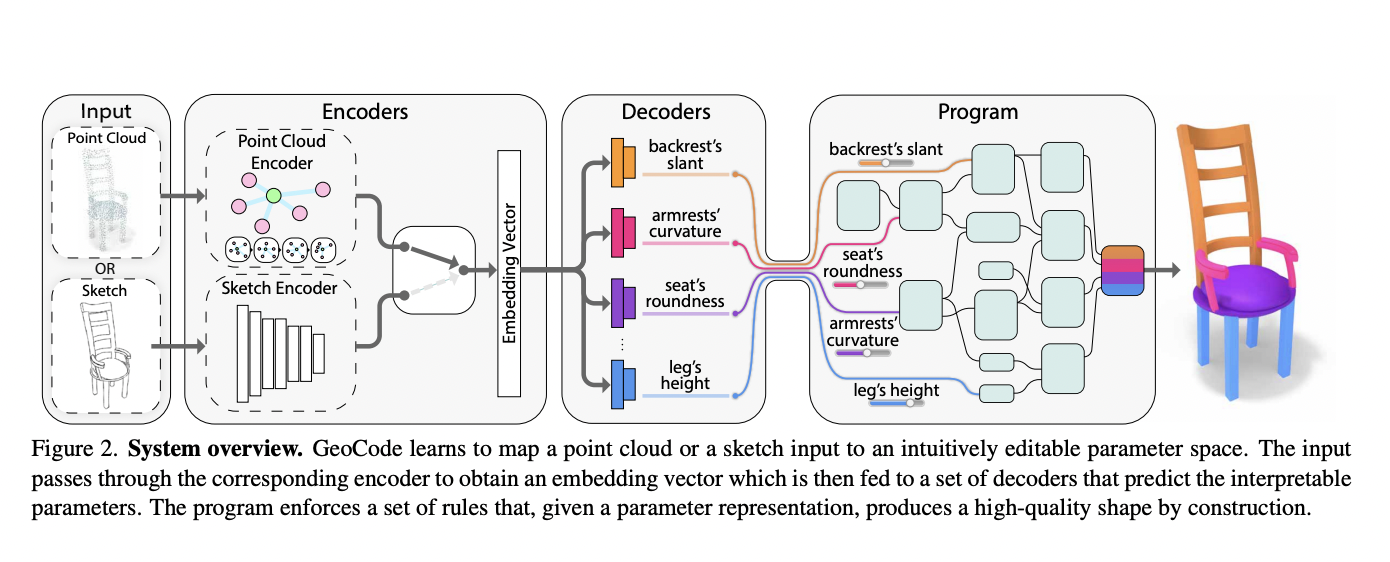
The proposed framework is depicted in the figure below.
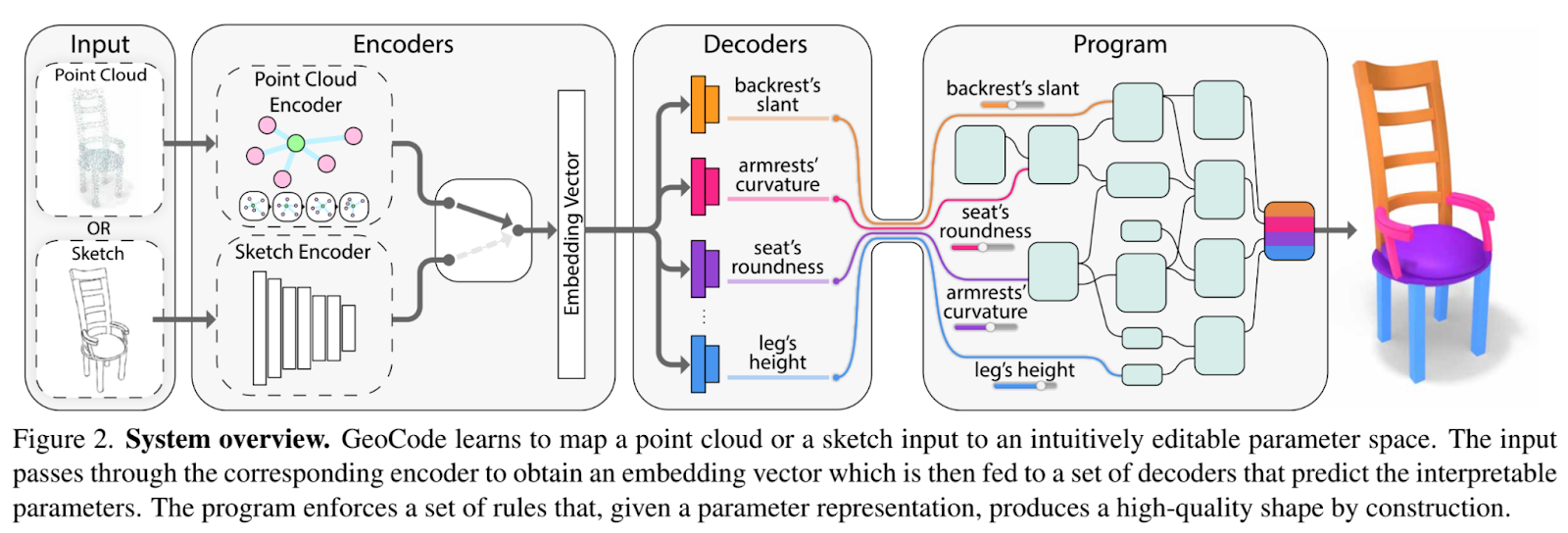
The objective is to recover an editable 3D mesh from an input item represented as a 3D point cloud or a 2D sketch picture. To do this, the authors create procedural software that enforces a set of form constraints and is parameterized by controls that are easy for humans to understand. After teaching a neural network to infer the program parameters, they can generate and recover an editable 3D shape by running the program. This application has straightforward controls in addition to structural data, leading to consistent semantic portion segmentation by building.
Specifically, the program supports three parameters: discrete, binary, and continuous. The disentanglement of the shape parameters guarantees accurate control over the object characteristics. For instance, we can isolate the seat’s shape from the other parts of a chair. Hence, modifying the seat will not impact the geometry of the remaining parameters, such as the backrest or the legs.
To obtain editing flexibility, mesh primitives such as spheres or planes are created and modified according to the user’s needs. Two curves guide the generation of the final shape: a one-dimensional curve describing a path in the 3D space, and a two-dimensional curve, representing the profile of the shape.
Defining curves in this way enables a rich variety of combinations, specified not only by the curves themselves but also by the attachment points, which are the points at which two curves are connected to each other. These points can be defined by a scalar floating value from 0 to 1, where 0 represents the beginning, and 1 is the end of the curve.
Before feeding the parameters to the program for the final 3D shape recovery, an encoder-decoder network architecture is exploited to map a point cloud or sketch input to the parameter representation.
The encoder embeds the input into a global feature vector. Then, the vector embeddings are fed to a set of decoders, each with the scope of translating the input into a single parameter (disentanglement).
GeoCode can be used for various editing tasks, such as interpolation between shapes. An example is shown in the figure below.

This was the summary of GeoCode, a novel AI framework to address the 3D shape synthesis problem. If you are interested, you can find more information in the links below.
Check out the Paper, Github, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.