Meet Tune-A-Video: An AI Framework To Address The Text-To-Video Generation Problem Through Existing Text-To-Image Generation Models

Artificial intelligence (AI) technology has ushered in a new era in computer science where it can produce rich and lifelike imagery. Multimedia creation has significantly improved (for instance, text-to-text, text-to-image, image-to-image, and image-to-text generation). Recent generative models like OpenAI’s Stable Diffusion and Dall-E (text-to-image) have been well received, and as a result, these technologies are fast evolving and capturing people’s attention.
While the pictures produced by these models are stunning and incredibly detailed, almost resembling photorealistic, AI researchers are starting to wonder whether we could obtain similar results in a more challenging domain, such as the video domain.
The challenges come from the temporal complexity introduced by videos, which are nothing more than images (in this context, usually called frames) stuck to each other to simulate motion. The idea and illusion of motion is therefore given by a temporally-coherent sequence of frames put one after the other.
The other challenge is presented by the comparison between the dimension of text-image datasets and text-video datasets. Text-image datasets are much larger and various than text-video ones.
Furthermore, to reproduce the success of text-to-image (T2I) generation, recent works in text-to-video (T2V) generation employ large-scale text-video datasets for fine-tuning.
However, such a paradigm is computationally expensive. Humans have the amazing ability to learn new visual concepts from just one single example.
With this assumption, a new framework termed Tune-A-Video has been proposed.
The researchers aim to study a new T2V generation problem, referred to as One-Shot Video Generation, where only a single text-video pair is presented for training an open-domain T2V generator.
Intuitively, the T2I diffusion model pretrained on massive image data can be adapted for T2V generation.
Tune-A-Video is equipped with tailored Sparse-Causal Attention to learning continuous motion, which generates videos from text prompts via an efficient one-shot tuning of pretrained T2I diffusion models.
The reasons for adapting the T2I models to T2V are based on two key observations.

Firstly, T2I models can generate images that align well with the verb terms. For example, given the text prompt “a man is running on the beach,” the T2I models produce the snapshot where a man is running (not walking or jumping), but not continuously (the first row of Fig. 2). This serves as evidence that T2I models can properly attend to verbs via cross-modal attention for static motion generation.
Lastly, extending the self-attention in the T2I model from one image to multiple images maintains content consistency across frames. Taking the example cited before, the same man and beach can be observed in the resultant sequence when we generate consecutive frames in parallel with extended cross-frame attention to the 1st frame. However, the motion is still not continuous (the second row of Fig. 2).
This implies that spatial similarities rather than pixel positions only drive the self-attention layers in T2I models.
According to these observations and intermediate results, Tune-A-Video seems capable of producing temporally-coherent videos amongst various applications such as change of subject or background, attribute editing, and style transfer.
If you are interested in the final results, they are presented near the end of the article.
The overview of Tuna-A-Video is presented in the figure below.
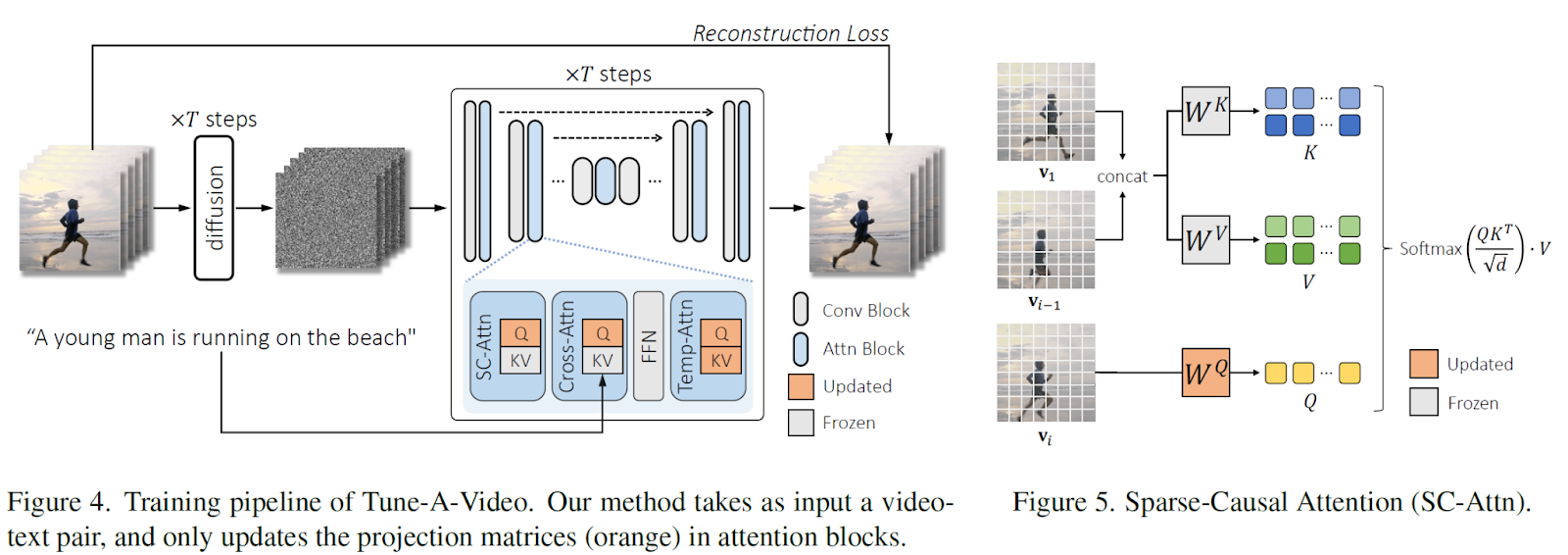
2D convolution on video inputs is used to extract temporal self-attention with a mask for temporal modeling. To achieve better temporal consistency without exponentially increasing the computational complexity, a sparse-causal attention (SC-Attn) layer is introduced.
Like causal attention, the first video frame is computed independently without attending to other frames, whereas the following frames are generated by visiting previous frames. The first frame relates to context coherence, while the former is used to learn the desired motion.
The SC-Attn layer models the one-way mapping from one frame to its previous ones, and due to the causality, key and value features derived from previous frames are independent of the output of the considered one.
Therefore, the authors fix the key and value projection matrix and only update the query matrix.
These matrixes are also fine-tuned in the temporal-attention (Temp-Attn) layers, as they are newly added and randomly initialized. Moreover, the query projection is updated in cross-attention (Cross-Attn) for better video-text alignment.
Fine-tuning the attention blocks is computationally efficient and keeps the property of diffusion-based T2I models unchanged.
Some sample results, shown as frame sequences, are depicted below as a comparison between Tune-A-Video and a state-of-the-art approach.

This was the summary of Tune-A-Video, a novel AI framework to address the text-to-video generation problem. If you are interested, you can find more information in the links below.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.