This Artificial Intelligence Research Introduces A Vision-Language-Commonsense Transformer Model That Incorporates Contextualized Commonsense For External Knowledge Visual Questioning Tasks
The field of “Visual Question Answering” (VQA) focuses on developing AI systems that can correctly respond to queries asked in a conversational tone and relate to a given image. If a system can accomplish this goal, it has shown to have a deeper understanding of images in general, as it must be able to respond to questions about various aspects of an image.
Large-scale annotated datasets for VQA have recently fueled progress in multimodal vision-language learning. Models need to analyze scenes and discover useful associations between the two modalities to provide appropriate responses to inquiries. Recently, vision and language (VL) models based on transformers have attained remarkable accuracy on benchmark VQA datasets by having been pre-trained on large-scale multimodal corpora. Visual quality assessment typically requires more than just a literal interpretation of an image (e.g., “A plate with meat, potatoes, and bread”) but also the ability to draw conclusions about the context of the image (e.g., “The dish is probably located at a restaurant”).
Inferences like these are made by humans based on their experience and common sense. Most current approaches rely on linguistic models’ implicitly embedded world knowledge, which frequently suffers from insufficient precision and breadth (assumed nature of common sense information). The overrepresentation of exceptional facts (like “people die in accidents”) in text corpora, at the expense of infrequently addressed minor truths understood by everyone (like “people eat”), is a problem for commonsense knowledge learned from texts.
These questions go beyond simple image recognition to involve knowledge of facts or common sense. As a result, neurosymbolic approaches fusing transformer-based representations with knowledge bases have emerged (KBs). However, it can be difficult to retrieve useful information straight from a KB due to gaps in coverage and the fact that KB facts are only applicable in specific scenarios.
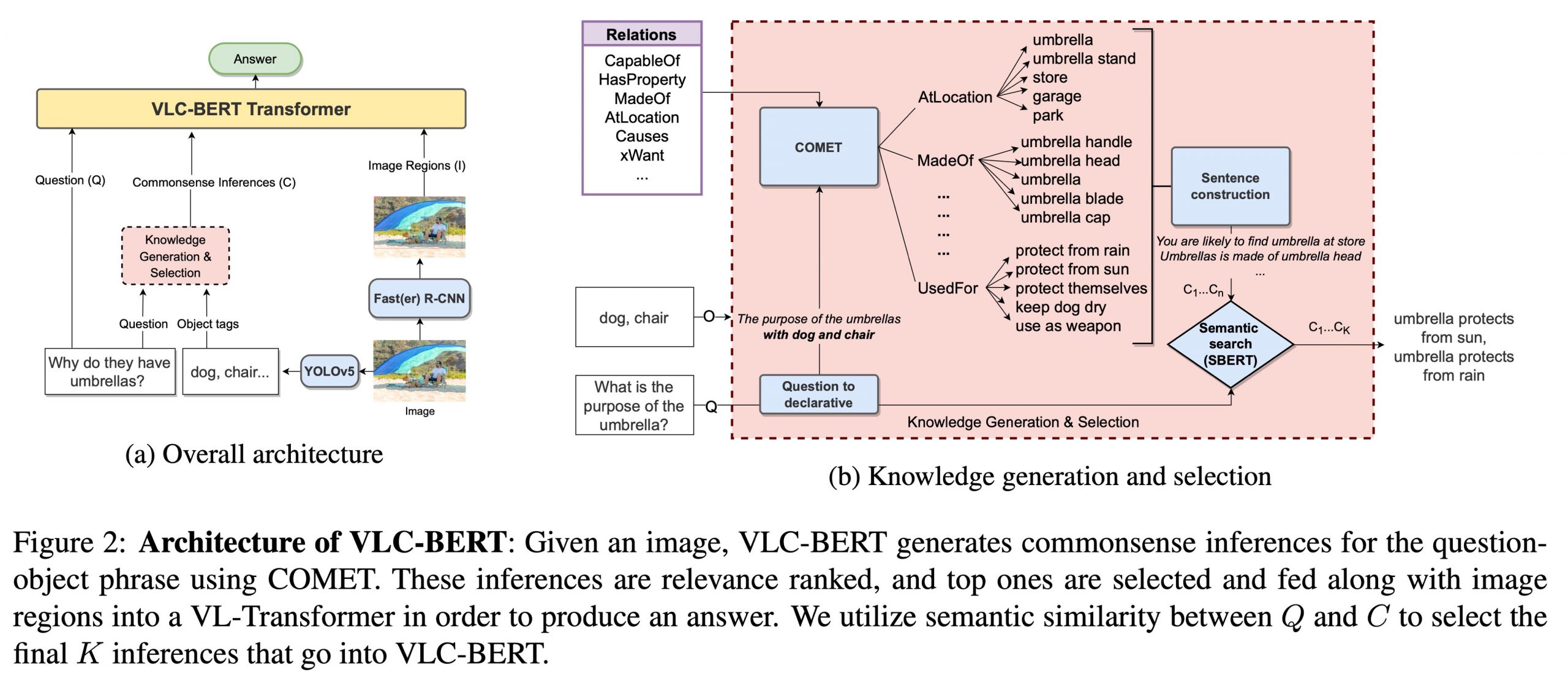
A new study by the Vector Institute for AI and the University of British Columbia presents VLC-BERT (Vision-LanguageCommonsense BERT), a paradigm to integrate VL-BERT-based VisionLanguage transformer with contextualized commonsense knowledge. Unlike most knowledge-based VQAs that typically use a retrieval paradigm, the proposed approach uses COMET, a language model trained on commonsense knowledge graphs. It creates contextualized commonsense inferences on the question phrase paired with image object tags.
The researchers enhance sentence transformers to prioritize, filter, and embed commonsense conclusions. To incorporate the filtered inferences into VLC-BERT, they utilize an attention-driven fusion mechanism trained to zero in on the most relevant inferences for each query. Some questions may only require visual, factual, or straightforward knowledge; therefore, common sense may not always be required.
The team used weak supervision to help determine whether or not common sense knowledge is useful, reducing the need for injecting noisy knowledge in these scenarios. Their tests on the tough OK-VQA and A-OKVQA datasets show that using common sense is always beneficial for visual question-answering tasks that require a lot of information. They also highlight in one of their tweets that pre-training their models VQA 2.0 helps overcome the challenge of training on smaller datasets like OK-VQA.
The team discovered the following caveats in the evaluation of VLC-BERT on their models and datasets:
- Object tags aren’t sufficient for answering some queries since they can’t recognize or make connections between many objects or events in a picture.
- The model may lose some information due to the compression introduced by SBERT and MHA while reducing the size of the commonsense inferences.
- Large-scale models like GPT-3 perform better than theirs, indicating that their model is constrained by COMET and the knowledge bases it was trained on.
The team believes this to be the first step in assessing the viability of including generative commonsense and investigating methods to determine when commonsense is required. They plan to have COMET take into account visual context regarding numerous items and occurrences in the future. They further aim to look at the viability of multi-hop reseasoning with COMET to connect the question and image-based extensions.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.