Can Reinforcement Learning Learn Everything?
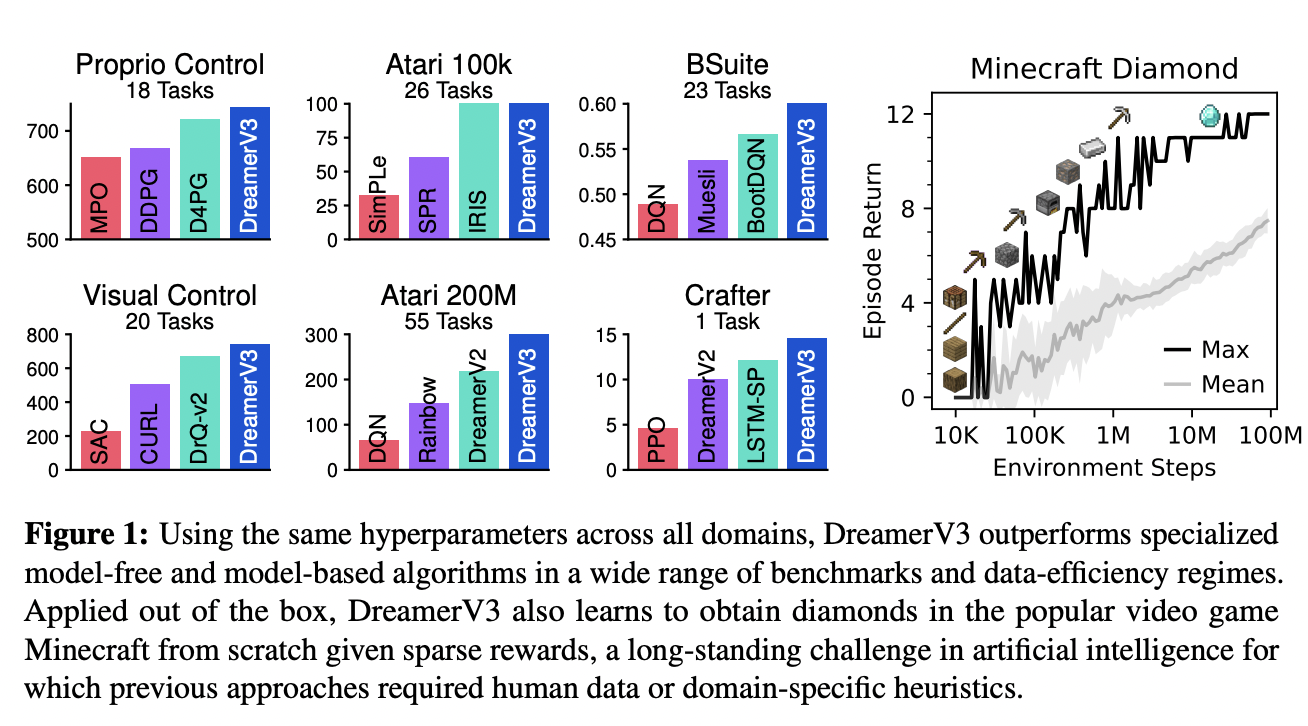
The latest paper (“Mastering Diverse Domains through World Models”) from Deepmind talks about an RL agent that can master diverse domains through World Models with the need for any human data and hyperparameter tuning for each task.
Reinforcement learning has performed well on specific tasks like playing Chess, Go, Starcraft, etc. But making an RL agent learn these specific tasks requires a lot of expert knowledge and human input. However, there has been a lot of work going on for designing more generalizable RL agents, which means we can give the model any new domain, and it still performs well.
One most recent works in this field are Deepmind’s “DreamerV3”, a single model that outperforms bespoke approaches on many specific tasks, and it does that with any domain-specific heuristic or human inputs. This means we do not need to change the representations for each particular task. Isn’t it amazing?
As the title of the paper suggests, learning “World Models” plays a crucial role. The world model is trained to learn a compact representation of sensory inputs by autoencoding and enables predicting future states and rewards based on the current state and actions. Another advantage of learning a world model is that learning becomes much faster. Suppose we want to find diamonds in Minecraft, then breaking a block in Minecraft takes some time, but by learning a world model of Minecraft, we can directly sample the future outcomes of the performed actions. The world model is implemented as a Recurrent State-Space Model (RSSM), as shown in Figure 3.
Apart from the world model, it also learns two other models:
- Critic: It judges a situation’s value and predicts each state’s expected reward under the current actor’s behavior.
- Actor: It learns to take action, which leads to valuable situations from the current state.
The actor and Critic perform their learning and prediction on representations from this world model.
The authors claimed that their methods surpass previous attempts at RL in certain domains. And it is shown to be the first algorithm to find diamonds in Minecraft without any human intervention. Moreover, the agent’s performance improves monotonically as a function of model size. This means improving the performance is more of a scaling challenge than a scientific one for now.
To conclude, The paper presents DreamerV3, a general and scalable reinforcement learning algorithm that performs well across various domains with fixed hyperparameters. It establishes a new state-of-the-art on several benchmarks and is successful in 3D environments that require spatial and temporal reasoning. Limitations of the work include that DreamerV3 does not consistently collect diamonds in Minecraft and that block-breaking speed was increased to allow for learning. The final performance and data efficiency of DreamerV3 improve as a function of model size. The authors suggest that training larger models to solve multiple tasks across overlapping domains is a promising direction for future investigations.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.