Amazon AI Research Studies Private Aggregation Of Teacher Ensemble Learning For End-To-End Speech Recognition
Data is crucial for training modern AI models. While public-domain data sets can be used to train such models, the volume and close match between training and test conditions required for state-of-the-art performance require user data obtained from live operational systems.
This raises concerns about safeguarding user data being used for training. Recently differential privacy has been widely used as it introduces random changes (noise) into the training process and thereby prevents inferences about the composition of a model’s training data.
In their latest study, Amazon researchers try a new method for end-to-end speech recognition: private aggregation of instructor ensemble learning. This work is one of the earliest attempts to compare different DP algorithms in state-of-the-art, fully neural automated speech recognition (ASR) systems.
Studies suggest that this kind of privacy attack by adversarial actors gleaning information about the training data for speech recognition systems could involve guessing either the speakers’ identities or the training data needed to create the system.
DP’s solution is to introduce random variability into the training process, making it more difficult to conclude the link between inputs and outputs and their corresponding training instances. While adding noise typically lowers model accuracy, there is a direct relationship between the amount of noise injected and the acquired privacy assurances.
It is common to practice to train neural networks using stochastic gradient descent (SGD), wherein gradients are iteratively applied tweaks to model parameters meant to boost accuracy on a subset of training examples.
Adding noise to the gradients is a common and understandable method of implementing DP for neural models. This variant of SGD (DP-SGD) can improve performance in some contexts, but it has been shown to have severe drawbacks when applied to automatic speech recognition (ASR). Based on this research, the number of misspelled words increases by more than three times for the most private of budgets.
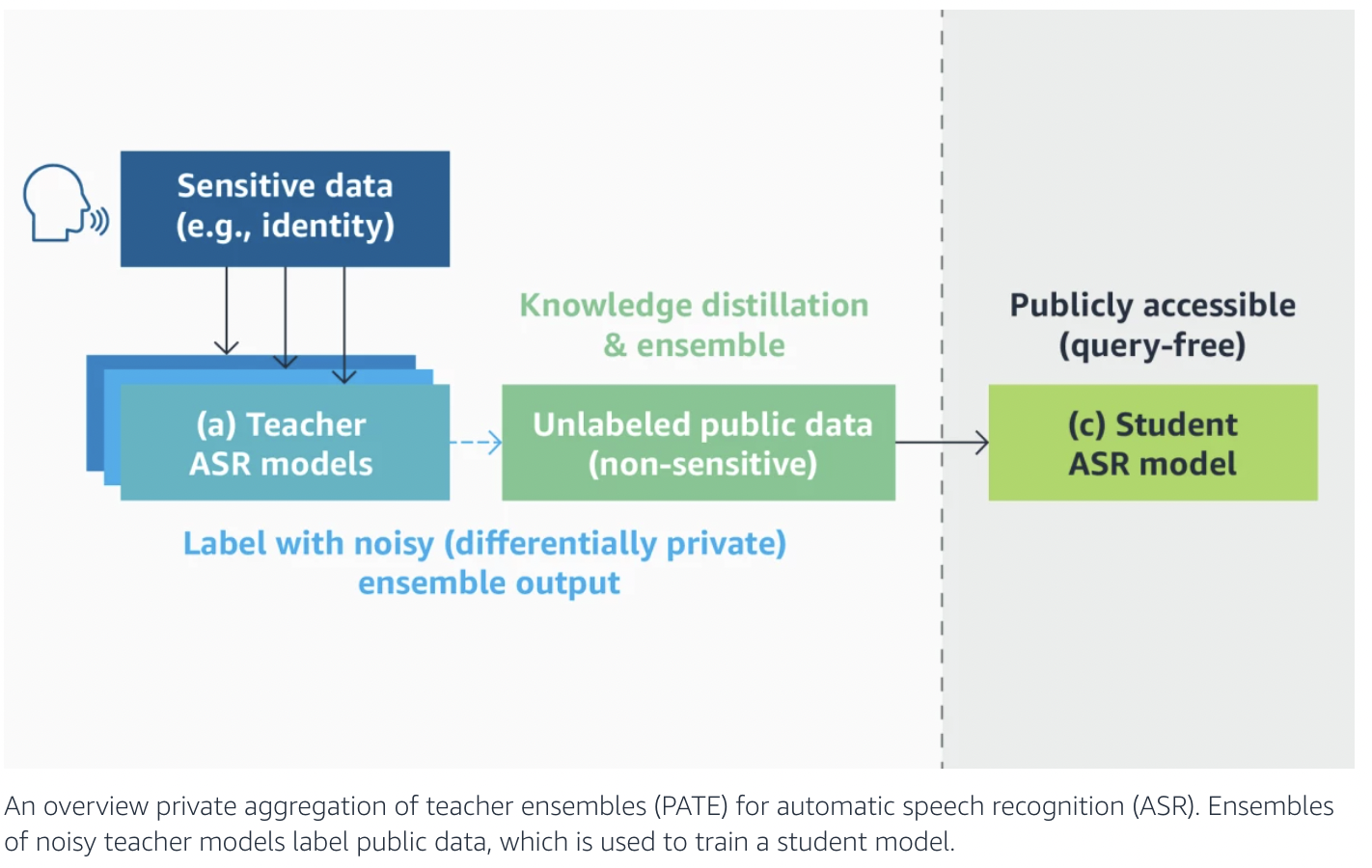
To counteract this drop in performance, the team used a private aggregation of teacher ensembles (PATE), which has already proven successful for picture classification. The goal is to untie the training data from the working model through student-teacher training, also known as knowledge distillation.
Partitioning the private data allows for training individual teacher models on the various subsets. Weighted averaging combines all individual instructor models into one that may be used to identify a public training set for the purpose of teaching the operational (student) model.
To achieve DP, the researchers introduce random noise, either Laplacian or Gaussian, into the instructor models’ predictions before averaging. After averaging, the student model can still apply the correct label. Still, an attacker cannot use it to detect training data features, mitigating the performance loss caused by noisy relabeling.
They consider training scenarios where sensitive and nonsensitive data share similar properties or are obtained from multiple types of speech sources. They analyzed several well-known neural end-to-end ASR designs.
The team adopted the RNN transducer (RNN-T) design as it provides the optimal privacy trade-offs for ASR tasks. The proposed PATE-based model outperforms the DP-SGD model by a margin of 26.2% to 27.5% on the benchmark LibriSpeech test compared to a baseline RNN-T model immune to DP noise.
They further show that PATE-ASR blocks model inversion attacks, which are used to recreate training data (MIA). This type of privacy attack takes a trained model and a target output and determines the input that maximizes the posterior probability of the target output. When applied to speech recognition, MIA can uncover speaker-specific traits by reconstructing the auditory inputs corresponding to a string of putatively spoken words.
ASR models trained with PATE-DP are clearly able to conceal such auditory information from MIAs, in contrast to models trained without DP. These findings highlight the potential of privacy-preserving ASR models as a means toward the development of more trustworthy voice services.
Check out the Paper and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.