Latest AI Research From China Introduces ‘OMMO’: A Large-Scale Outdoor Multi-Modal Dataset and Benchmark for Novel View Synthesis and Implicit Scene Reconstruction
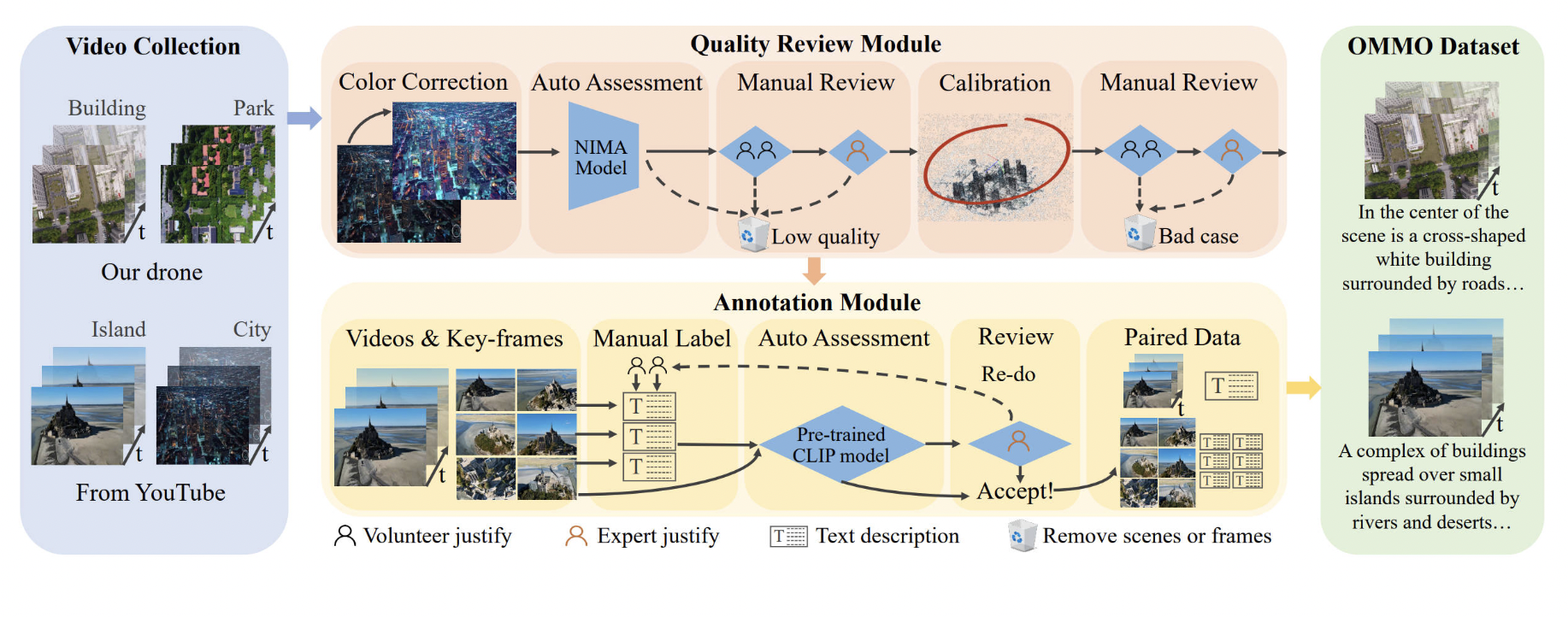
Photo-realistic novel view synthesis and high-fidelity surface reconstruction have been made possible by recent developments in implicit brain representations. Unfortunately, most of the approaches now in use are centered on a single item or an interior scene, and when used in outside situations, their synthesis performance could be better. The current outdoor scene datasets are created at a modest geographic scale by rendering virtual scenes or collecting basic scenes with few items. The absence of standard benchmarks and large-scale outdoor scene datasets makes it impossible to assess the performance of certain fairly modern approaches, even though they are well-designed for big scenes and attempt to tackle this problem.
Scene photos from rebuilt or virtual scenes, which differ from the genuine scene in texture and appearance elements, are included in the BlendedMVS and UrbanScene3D collections. Gathering pictures from the Internet may create incredibly efficient datasets like ImageNet and COCO. Still, these techniques are unsuitable for NeRF-based job evaluation because of the scene’s constantly changing objects and lighting conditions. The standard for realistic outdoor sceneries taken by a high-precision industrial laser scanner, for instance, is provided by Tanks and Temples. However, its scene scale is still too tiny (463m2 on average) and only concentrates on a single outside object or structure.

An illustration of a city scene from our dataset, taken using a circle-shaped camera trajectory at low illumination. We display the camera track, written explanations of the scene, and multiview-calibrated photos. Our dataset can deliver realistic, high-fidelity texture details; some features in colored boxes are zoomed in to show this.
Their approach to gathering data is comparable to Mega-use NeRFs of drones to record expansive real-world sceneries. However, Mega-NeRF only offers two repetitive scenarios, preventing it from serving as a generally accepted baseline. Therefore, large-scale NeRF research for outdoor environments needs to catch up for single items or interior scenes since, to their knowledge, no standard and well-recognized large-scale scene dataset has been developed for NeRF benchmarking. They present a carefully chosen fly-view multimodal dataset to address the dearth of large-scale real-world outdoor scene datasets. As seen in the figure above, the dataset consists of 33 scenes with prompt annotations, tags, and 14K calibrated photos. Unlike the above-mentioned existing approaches, their scenes come from various sources, including those we’ve acquired from the Internet and ourselves.
As well as being thorough and representative, the collection indications include a range of scene kinds, scene sizes, camera trajectories, lighting conditions, and multimodal data that need to be contained in previous datasets. They also provide all-encompassing benchmarks based on the dataset for innovative view synthesis, scene representations, and multimodal synthesis to assess the suitability and performance of the generated dataset for assessing standard NeRF approaches. More significantly, they offer a general process to produce real-world NeRF-based data from online videos of drones, which makes it simple for the community to expand their dataset. To offer a fine-grained evaluation of each approach, they also include several specific sub-benchmarks for each of the aforementioned tasks according to various scene kinds, scene sizes, camera trajectories, and lighting conditions.
To sum up, their key contributions are as follows:
• To promote large-scale NeRF research, they present an outdoor scene dataset with multimodal data that is more plentiful and diverse than any comparable outdoor dataset currently available.
• They provide several benchmark assignments for popular outdoor NeRF approaches to establish a unified benchmarking standard. Numerous tests demonstrate that their dataset can support typical NeRF-based tasks and give rapid annotations for the next research.
• To make their dataset easily scalable, they offer a low-cost pipeline for turning films that can be freely downloaded from the Internet into NeRF-purpose training data.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.