What are Transformers? Concept and Applications Explained
Transformers are neural network architectures that learn the context by tracking the relationships in sequential data, like the words in a sentence. They were developed to solve the issue of sequence transduction, i.e., transforming input sequences into output sequences, for example, translating one language to another.
Before Transformers, Recurrent Neural Network (RNN) was used to understand text using Deep Learning. Suppose we had to translate the following sentence into Japanese -“Linkin Park is an American rock band. The band was formed in 1996.” An RNN would take this sentence as input, process it word-by-word, and sequentially give the Japanese counterpart of each word as output. This would lead to grammatical errors, as in any language, the order of words is important.
Another issue with RNNs is that they are hard to train and cannot be parallelized since they process words sequentially. This is where Transformers came into the picture. The first model was developed by researchers at Google and the University of Toronto in 2017 for text translation. Transformers can be efficiently parallelized and trained on very large datasets (GPT-3 was trained on 45TB of data)
In the above figure, the left side represents the encoder block and the decoder block is represented on the right side.
Transformers consist of six similar encoders and six similar decoders. Each encoder has two layers – a self-attention layer and a feed-forward Neural Network. The decoder has both layers, but between them is an attention layer that helps it to focus on only the relevant parts of the input.
Let us understand the working of Transformers by considering the translation of a sentence from English to French.
Encoder Block

Before passing the words as input, input embeddings convert each word into the form of an n-dimensional vector, and positional encodings are added. Positional encodings help the model understand the word’s position in the sentence.
The self-attention part focuses on the relevance of a word with respect to the other words present in the sentence. We can create an attention vector for each word that brings out the relationship between each word in the sentence.
In the above figure, the lighter the color of the square, the more attention the model is paying to that word. Suppose the model has to translate the sentence – “The agreement on the European Economic Area was signed in August 1992” to French. When it is translating the word “agreement”, it is focusing on the French word “accord”. The model correctly paid attention when translating “European Economic Area”. In French, the order of these words is reversed (“européenne économique zone”) as compared to English.
The model, for every word, weighs its value much higher on itself in the sentence without considering its relationship with other words in the sentence. To address this, multiple attention vectors are used for each word, and then a weighted average is taken to calculate the final attention vector for each word. This process is known as the multi-head attention block, as it uses multiple attention vectors to understand the meaning of a sentence.
The next step is the feed-forward neural network. A feed-forward neural network is applied to each attention vector to transform it into a form acceptable to the next encoder or decoder layer. The feed-forward network accepts attention vectors independently. Unlike RNNs, each of these attention vectors is independent of the other. Parallelism can be applied here, making a huge difference.
Decoder Block

To train the model, we input the French translation into the decoder block. The embedding and the positional encoding layers transform each word into its respective vectors.
The input is then passed through the masked multi-head attention block, where attention vectors are generated for each word in the French sentence to determine the relevance of each word to the other words in the sentence. The model uses previously translated English words to match and compare with the French translation fed into the decoder. By comparing these two, the model updates its matrix values and continues to learn through multiple iterations.
To ensure that the model is learning effectively, the next French word is hidden. The model must predict it using previous results rather than knowing the correct translation. This is why it is called a “masked” multi-head attention block.
Now, the resultant vector from the first attention block and vectors from the encoder block are passed through another multi-head attention block. This block is where the actual mapping of English to French words happens. The output is the attention vector for every word in English and French sentences.
Now, each attention vector passes into a feed-forward unit. The model makes these vectors into a form easily acceptable by a linear layer or another decoder block. Then a linear layer expands the dimensions of the vector into numbers of words in the French language after translation.
The output is then passed through a softmax layer that transforms it into a probability distribution, which is human-interpretable. The word which has the highest probability is produced as output.
The input is run through the six layers of encoders, and the final output is then sent to the Multi-Head Attention layer of all the decoders. The Masked Multi-Head Attention layer takes in the output of the previous decoder blocks as input. This way, the decoders take into consideration the word from the previous time step and the context of the word from the encoding process.
All the decoders work together to create an output vector which is transformed into a logits vector using a linear transformation. The logits vector has a size equal to the number of words in the vocabulary. This vector is then passed through a softmax function, which tells us how likely a word will be the next word in the generated sentence. The softmax function basically tells us what the next word will be.
Transformers are primarily used in natural language processing (NLP)and computer vision (CV). In fact, any sequential text, image, or video data is a candidate for transformer models. Over the years, transformers have had great success in language translation, speech recognition, speech translation, and time series prediction. Pretrained models like GPT-3, BERT, and RoBERTa have demonstrated the potential of transformers to find real-world applications such as document summarization, document generation, biological sequence analysis, and video understanding.
In 2020, it was shown that GPT-2 could be tuned to play chess. Transformers have been applied to the field of image processing and have shown results competitive with convolutional neural networks (CNNs).
Due to their wide adoption in computer vision and language modeling, they have started being adopted in new domains like medical imaging and speech recognition.
Researchers are utilizing transformers to gain a deeper understanding of the relationships between genes and amino acids in DNA and proteins. This allows for faster drug design and development. Transformers are also employed in various fields to identify patterns and detect unusual activity to prevent fraud, optimize manufacturing processes, suggest personalized recommendations, and enhance healthcare. These powerful tools are also commonly used in everyday applications such as search engines like Google and Bing.
The following figure shows how different transformers relate to each other and what family they belong to.
Chronological timeline of transformers:
Timeline of transformers with y-axis representing their size (in millions of parameters):
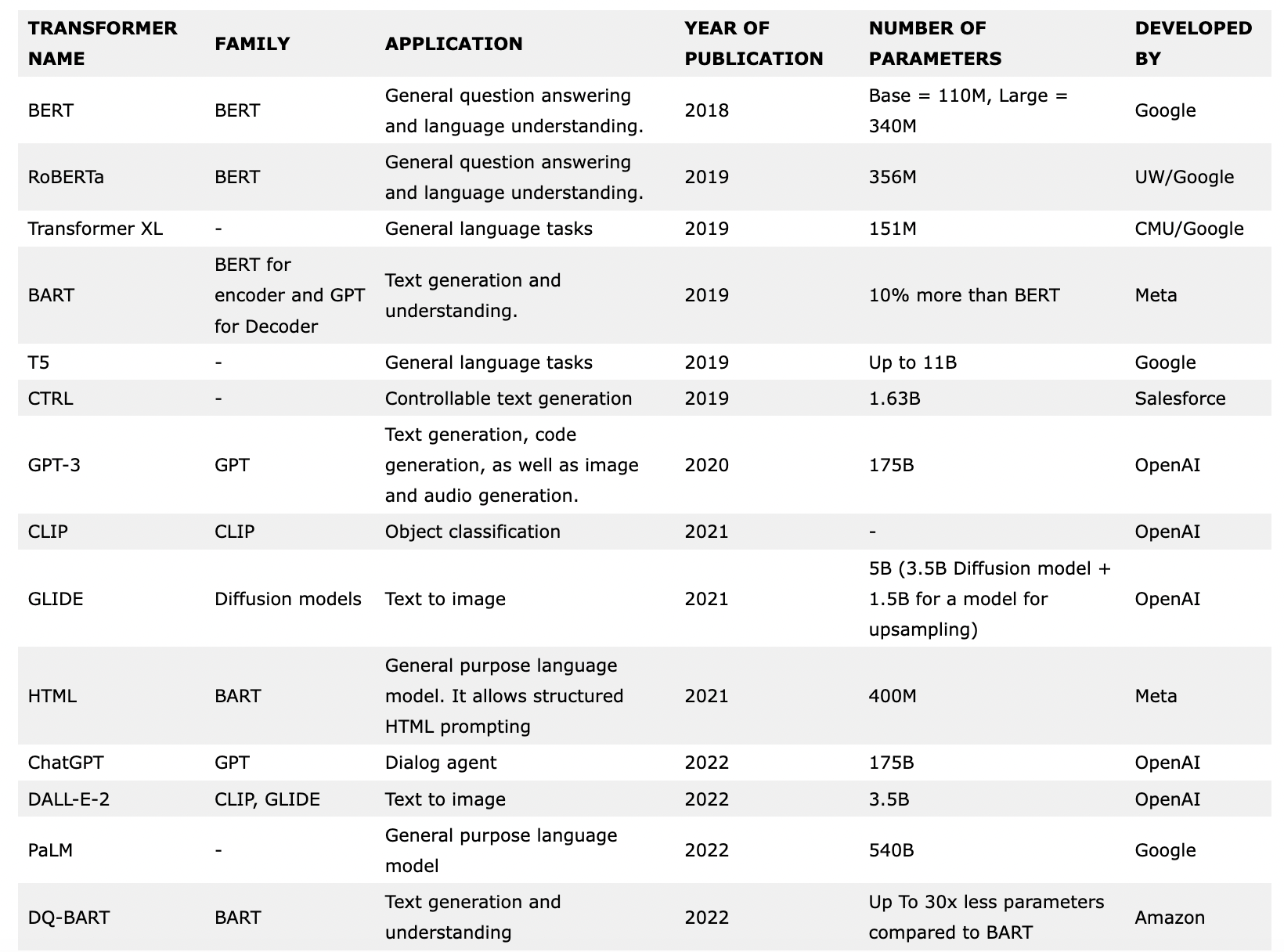
Following are some of the most common transformers:
| TRANSFORMER NAME | FAMILY | APPLICATION | YEAR OF PUBLICATION | NUMBER OF PARAMETERS | DEVELOPED BY |
| BERT | BERT | General question answering and language understanding. | 2018 | Base = 110M, Large = 340M | |
| RoBERTa | BERT | General question answering and language understanding. | 2019 | 356M | UW/Google |
| Transformer XL | – | General language tasks | 2019 | 151M | CMU/Google |
| BART | BERT for encoder and GPT for Decoder | Text generation and understanding. | 2019 | 10% more than BERT | Meta |
| T5 | – | General language tasks | 2019 | Up to 11B | |
| CTRL | – | Controllable text generation | 2019 | 1.63B | Salesforce |
| GPT-3 | GPT | Text generation, code generation, as well as image and audio generation. | 2020 | 175B | OpenAI |
| CLIP | CLIP | Object classification | 2021 | – | OpenAI |
| GLIDE | Diffusion models | Text to image | 2021 | 5B (3.5B Diffusion model + 1.5B for a model for upsampling) | OpenAI |
| HTML | BART | General purpose language model. It allows structured HTML prompting | 2021 | 400M | Meta |
| ChatGPT | GPT | Dialog agent | 2022 | 175B | OpenAI |
| DALL-E-2 | CLIP, GLIDE | Text to image | 2022 | 3.5B | OpenAI |
| PaLM | – | General purpose language model | 2022 | 540B | |
| DQ-BART | BART | Text generation and understanding | 2022 | Up To 30x less parameters compared to BART | Amazon |
![]()
I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.
Credit: Source link
Comments are closed.