A New AI Framework Called Text2Poster Automatically Generates Visually-Effective Posters From The Textual Information

Posters have been widely utilized in numerous commercial and nonprofit contexts to promote and disseminate information as a type of media with artistic and practical elements. For instance, e-commerce companies use eye-catching banners for advertising their products. Social event websites, like those for conferences, are frequently embellished with opulent and educational posters. These high-quality posters are created by integrating styled lettering into appropriate backdrop imagery, which requires much manual editing and non-quantitative aesthetic intuition. However, such a time-consuming and subjective approach cannot satisfy the enormous and quickly growing demand for well-designed signs in real-world applications, which decreases the effectiveness of information spread and results in less-than-ideal marketing effects.
In this work, they offer Text2Poster, a unique data-driven framework that produces an effective automatic poster generator. The Text2Poster initially uses a sizable pretrained visual, textual model to recover appropriate backdrop pictures from input texts, as seen in the figure below. The framework then samples from the predicted layout distribution to establish the layout of the texts, then repeatedly refines the layout using cascaded auto-encoders. Finally, it obtains the text’s color and font from a collection of colors and typefaces that include semantic tags. They acquire the framework’s modules through the use of weakly- and self-supervised learning techniques. Experiments show that their Text2Poster system can automatically produce high-quality posters, outperforming its academic and commercial rivals on objective and subjective metrics.
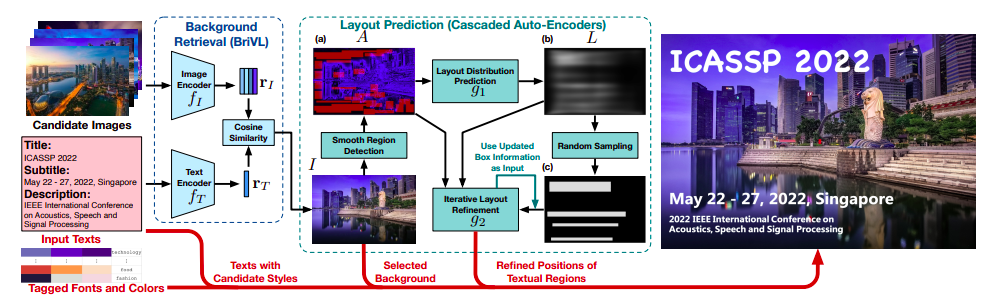
The stages that the backend takes are as follows:
- Using a trained visual-textual model to retrieve images: They are interested in investigating the photos that are “weakly associated” with the sentences while collecting backdrop images for poster development. For instance, they like to discover pictures with love metaphors when collecting photos for the term “The Wedding of Bob and Alice,” such as a picture of a white church against a blue sky. They use the BriVL, one of the SOTA pretrained visual-textual models, to accomplish this goal by retrieving background pictures from texts.
- Utilizing cascaded auto-encoders for layout prediction, The image’s smooth sections are first found. Once the smooth zones are found, the smooth region is colored on the saliency map. An estimated amp Layout Distribution is now presented.
- Text stylization: The text is combined with the original image based on the anticipated arrangement.
They have a GitHub page where you can access the inference code for utilizing Text2Poster. Download the source code files to get the program running. Another way to use the program is using their Quickstart APIs. All the details of usage are written on their GitHub page.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.