Artificial Intelligence (AI) Researchers From The Shanghai Jiao Tong University and Microsoft Propose A Framework To Alleviate The Talking Face Generation Problem Using Memories
Making talking faces is one of the most remarkable recent advances in artificial intelligence (AI), which has made tremendous improvements. Artificial intelligence (AI) algorithms are used to create realistic talking faces that may be utilized in various applications, including virtual assistants, video games, and social media. Talking face production is a challenging process that calls for advanced algorithms to represent the nuances of human speech and facial emotions accurately.
Researchers originally started experimenting with computer images to make realistic human features in the early days of computer animation, where the history of talking face creation can be traced. However, the development of deep learning and neural networks is when the technology started to take off. Today, scientists are developing more expressive and realistic talking faces by combining several methods, such as machine learning, computer vision, and natural language processing.
The talking face generation technology is now in its infancy, with numerous restrictions and difficulties that still need to be resolved.
Some related challenges concern recent developments in AI research, which led to a manifold of deep learning techniques producing rich and expressive talking faces.
The most adopted AI architecture comprises two stages. In the first stage, an intermediate representation is predicted from the input audio, such as 2D landmarks or blendshape coefficients, which are numbers used in computer graphics to influence the shape and expression of 3D face models. Based on the expected representation, the video portraits are then synthesized using a renderer.
The majority of techniques are designed to develop a deterministic one-to-one mapping from the provided audio to a video, even though talking face creation is essentially a one-to-many mapping problem. Due to the many context variables, such as phonetic contexts, emotions, and lighting settings, there are several possible visual representations of the target individual for an input audio clip. This makes it more difficult to provide realistic visual results when learning deterministic mapping since ambiguity is introduced during training.
Addressing the talking face generation issue by accounting for these context variables is the aim of the work presented in this article.
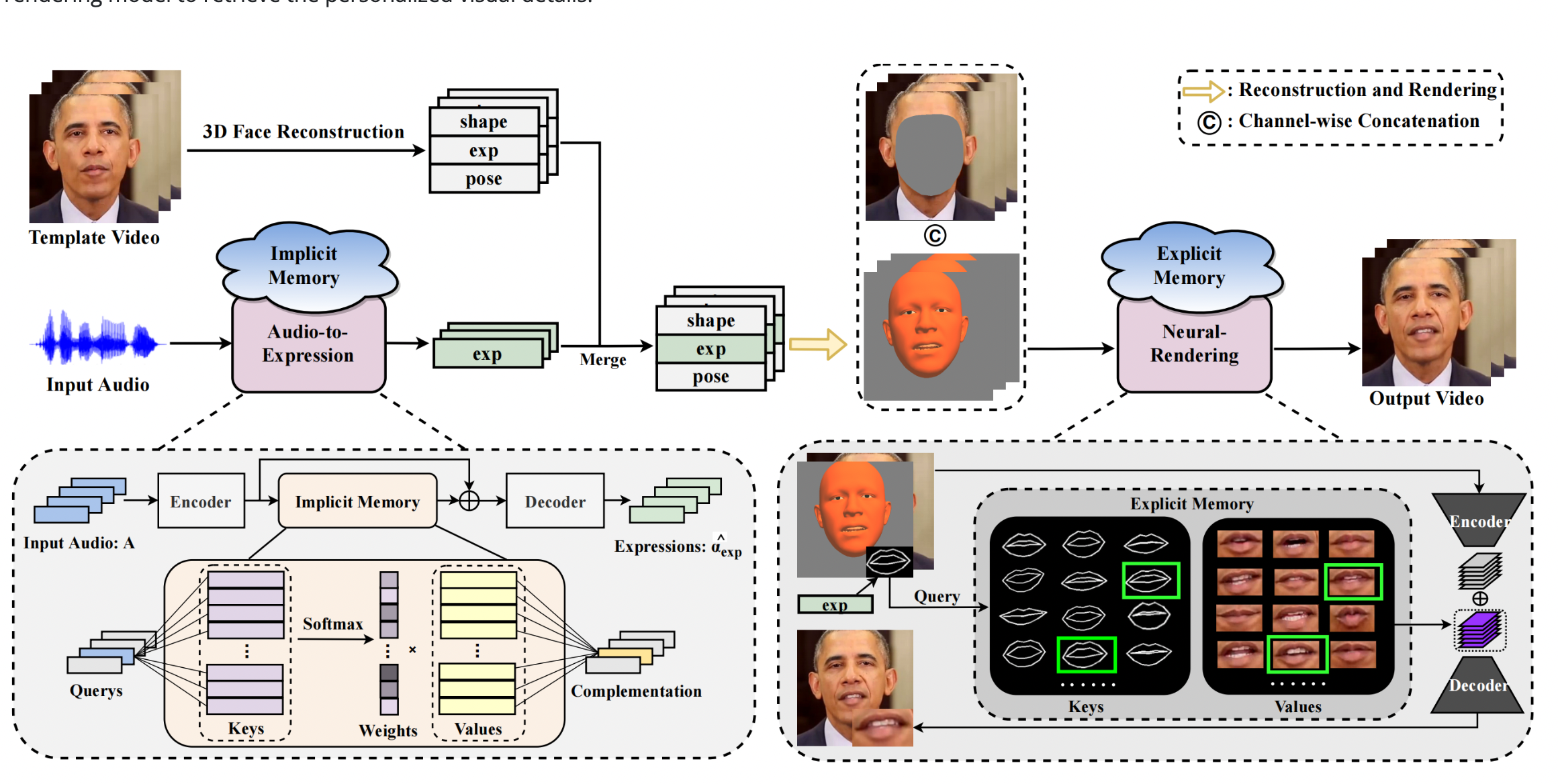
The architecture is presented in the figure below.

The inputs consist of an audio feature and a template video of the target person. For the template video, good practice involves masking the face region.
First, the audio-to-expression model takes in the extracted audio feature and predicts the mouth-related expression coefficients. These coefficients are then merged with the original shape and pose coefficients extracted from the template video and guide the generation of an image with the expected characteristics.
Next, the neural rendering model takes in the generated image and the masked template video to output the final results, which correspond to the mouth shape of the image. In this way, the audio-to-expression model is responsible for lip-sync quality, while the neural rendering model is responsible for rendering quality.
However, this two-stage framework still needs to be improved for tackling one-to-many mapping difficulty since each stage is separately optimized to predict missing information, like habits and wrinkles, by the input. For this purpose, the architecture exploits two memories, termed, respectively, implicit memory and explicit memory, with attention mechanisms to complement the missing information jointly. According to the author, using only one memory would have been too challenging, given that the audio-to-expression model and the neural-rendering model play distinct roles in developing talking faces. The audio-to-expression model creates semantically-aligned expressions from the input audio, and the neural-rendering model creates the visual appearance at the pixel level in accordance with the estimated expressions.
The results produced by the proposed framework are compared with state-of-the-art approaches mainly concerning lip-sync quality. In the figure below, some samples are reported.

This was the summary of a novel framework to alleviate the talking face generation problem using memories. If you are interested, you can find more information in the links below.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.