The Latest Google Research Shows how a Machine Learning ML Model that Provides a Weak Hint can Significantly Improve the Performance of an Algorithm in Bandit-like Settings
In many applications, decisions are frequently made based on requests that come in an online fashion, which means that not all of the problem’s constraints are originally understood, and there is inherent uncertainty regarding significant components of the situation. The multi-armed or n-armed bandit problem, where a finite amount of resources must be divided across various options to maximize their projected gain, is a particularly well-known problem within this domain. The primary distinguishing characteristic of these problems is that each choice’s attributes are only partially recognized at the time of allocation and may be understood more fully over time or as resources are allocated.
A navigation app that responds to driver queries is a nice illustration of the multi-armed bandit problem. The alternative choices in this scenario are a set of precomputed alternative routes in navigation. The driver’s preferences for route features and potential delays due to traffic and road conditions are unpredictable parameters that affect user satisfaction. The “regret,” which is the difference between the reward of the best choice and the reward acquired by the algorithm across all T rounds, is used to compute the algorithm’s performance over T rounds versus the optimal action in retrospect.
Online machine learning researches these conditions and offers several methods for making decisions in uncertain situations. Although existing solutions achieve sublinear regret, their algorithms only optimize for worst-case scenarios and ignore the plethora of real-world data that could otherwise be utilized to train machine learning models, which could aid in algorithm design.
Working on this problem statement, Google Research researchers recently demonstrated in their work “Online Learning and Bandits with Queried Hints” how an ML model that offers a weak hint can dramatically enhance the performance of an algorithm in bandit-like conditions. The researchers explained that numerous current models that have been trained using pertinent training data could produce extremely accurate outcomes. However, their technique guarantees remarkable performance even when the model feedback is provided as a less direct weak hint. The user can ask the computer to predict which of the two alternate choices will be best.
Returning to the case of the navigation app, the algorithm can choose between two routes and ask an ETA model which of the two is faster, or it can show the user two ways with contrasting features and let them select the safer bet. In terms of dependence on T, using such a method increased the bandits’ remorse on an exponential scale. Additionally, the paper will also be presented at the esteemed ITCS 2023 conference.
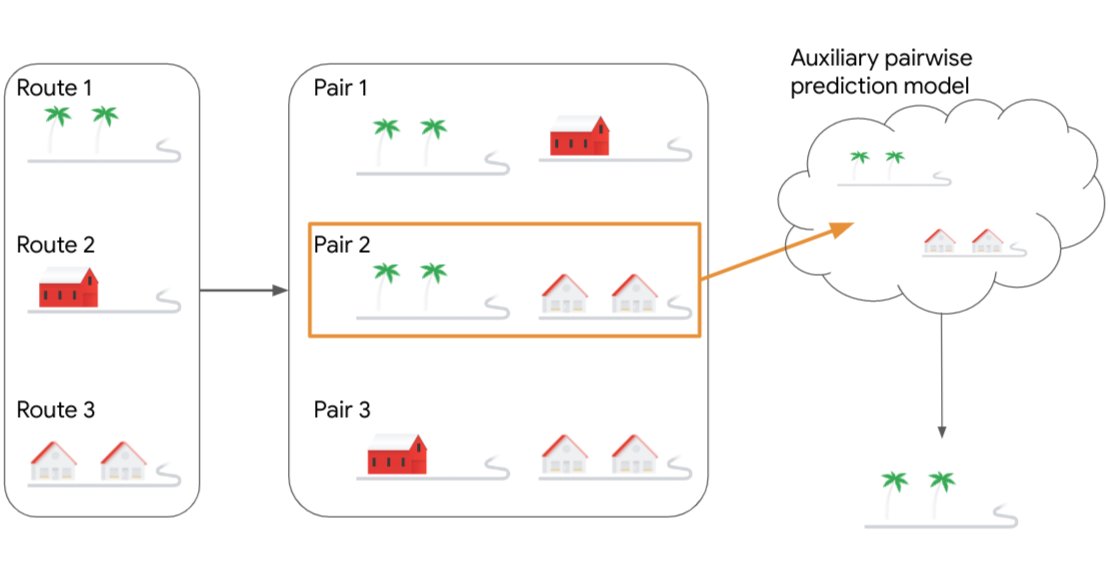
The algorithm uses the popular upper confidence bound algorithm (UCB) as its foundation. The UCB method keeps track of an alternative option’s average reward up to the current point as a score and adds an optimism parameter that shrinks the more times the choice has been selected. This maintains a steady balance between exploration and exploitation. To enable the model to choose the superior option out of two, the method applies the UCB scores to pairs of alternatives. The maximum reward from the two selections determines the reward in each round. The algorithm then looks at all of the pairs’ UCB scores and selects the pair with the highest score. The ML auxiliary pairwise prediction model is then given these pairs as input and returns the best result.
In terms of theoretical assurances, the algorithm created by Google researchers accomplishes significant advancements, including an exponential improvement in the dependence of regret on the time horizon. The researchers compared their method to a baseline model that uses the conventional UCB approach to select alternatives to send to the pairwise comparison model. It was noted that their method swiftly determines the optimum decision without accumulating regret, in contrast to the UCB baseline model. In a nutshell, the researchers explored how a pairwise comparison ML model might offer weak hints that can be incredibly effective in situations like the bandits settings. The researchers believe that this is just the beginning and that their model of hint can be used to solve more intriguing challenges in machine learning and the combinatorial optimization domain.
Check out the Paper and Google blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.