Researchers Predict Semantically Meaningful and Calibrated Uncertainty Intervals in the Latent Space of a Generative Adversarial Network
There has been a continuous effort in the scientific and technological communities to raise the bar for the precision of measurements of all types, alongside a simultaneous push to improve the clarity of photographs. A secondary objective is to minimize guesswork associated with estimates and inferences drawn from the gathered information. However, it is impossible to eradicate all forms of ambiguity.
Recently, researchers from the Massachusetts Institute of Technology (MIT), the University of California at Berkeley, and the Israel Institute of Technology (Technion) developed a method to present uncertainty in a way that laypeople could understand. This study focuses on images that have been partially muddled or distorted (due to missing pixels) and on techniques, especially computer algorithms, that are meant to reveal the part of the signal that has been masked.
The first component of their model is an encoder, a type of neural network developed by researchers to restore sharpness to blurry photos. To construct a “latent” representation of a clean image, an encoder uses a distorted image to generate a series of numbers that can be understood by a computer but are likely to be lost on most humans. A decoder, which has several varieties, typically reusing neural networks, is the next stage.
The team used a “generative” model, a type of decoder. Specifically, they utilized a commercially available version of the algorithm known as StyleGAN, which takes the numbers from the encoded representation as its input and outputs a fully refined image (of that particular cat). Consequently, the combined results of the encoding and decoding steps produce a clear image from a hazy one.
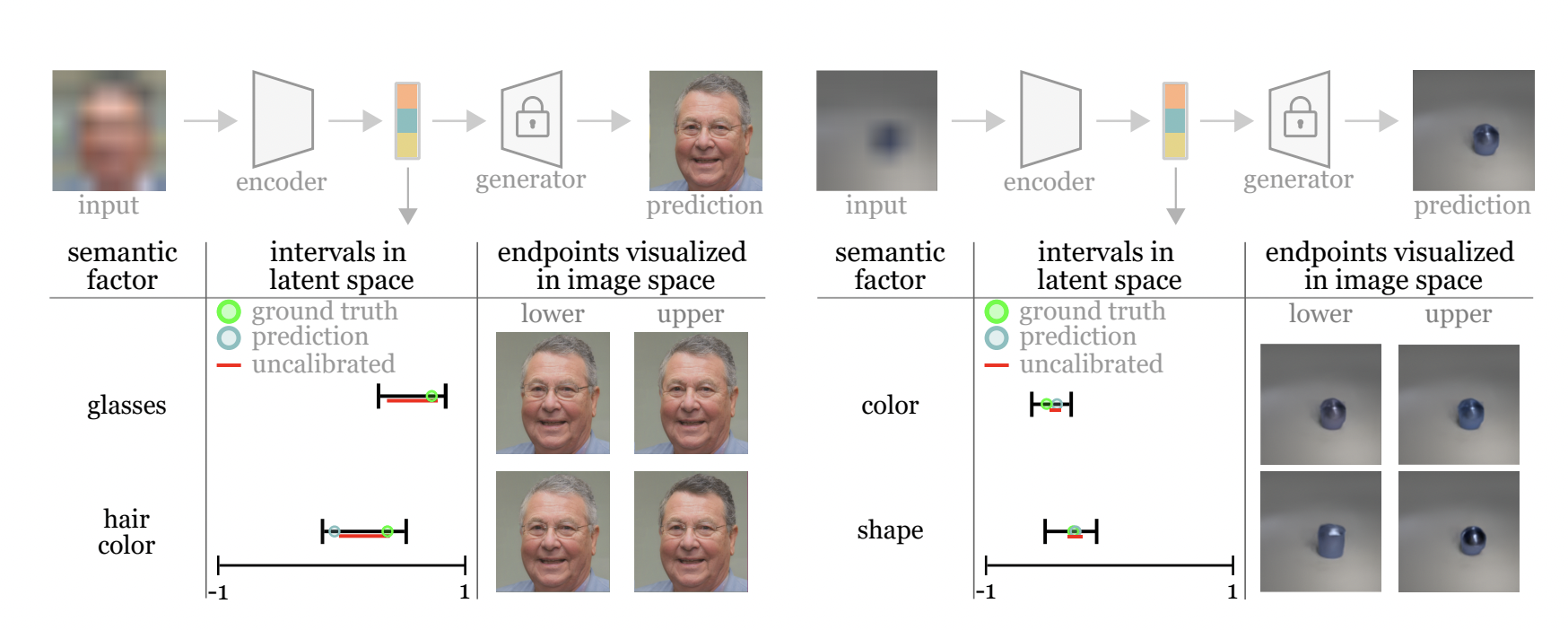
The ambiguity of a picture can be depicted by making a “saliency map,” which assigns a probability value (often between 0 and 1) to each pixel to show how sure the model is that it is true. This approach has limitations because the prediction is handled separately for each pixel, and meaningful objects occur among groups of pixels, not within an individual pixel.
Their method revolves around an image’s “semantic characteristics,” or clusters of pixels that, when put together, form something meaningful, like a human face, a dog’s face, or something else easily recognizable.
A single image representing the “best guess” of the correct image may be produced by the conventional method, but the inherent uncertainty in that representation is often not obvious. For practical applications, the researchers contend, uncertainty needs to be communicated in a way that makes sense to individuals who aren’t trained in machine learning. As an alternative to providing a single image, they developed a method to generate various images, which could be accurate.
As a bonus, they can establish tight limits on the range (or interval), guaranteeing probabilistically that the real representation is within that range. If the user just requires 90% certainty, then a smaller range can be provided, and if they can tolerate a higher degree of uncertainty, an even smaller range can be given.
According to the team, this research is the first to provide “a formal statistical guarantee” for uncertainty ranges related to important (semantically-interpretable) picture characteristics. It is thus suitable for use in a generative model. The team hopes to take it further into more crucial areas, like medical imaging, where this “statistical assurance” may prove invaluable.
The team has begun collaborating with radiologists to determine whether or not their method for detecting pneumonia has practical utility in cases where doctors have blurry chest X-rays on film or a radiograph. The team suggests that their findings may potentially be useful in the realm of law enforcement. A surveillance camera’s output may be grainy, so there may need to sharpen it. Some models can achieve this, but it is difficult to quantify the degree of error. The proposed model could exonerate an innocent person or convict a criminal one.
Check out the Paper and MIT Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.