Google AI Introduces ‘Uncertainty Baselines Library’ For Uncertainty and Robustness in Deep Learning

Machine Learning has been a trending word in today’s technology. It is growingly used in a diverse range of real-world applications like Image and Speech recognition, Self-driving cars, Medical Diagnosis, to name a few. Hence, it becomes quintessential to understand its behavior and performance in practice. High-quality estimates of robustness and uncertainty are crucial for numerous functions, especially Deep Learning.
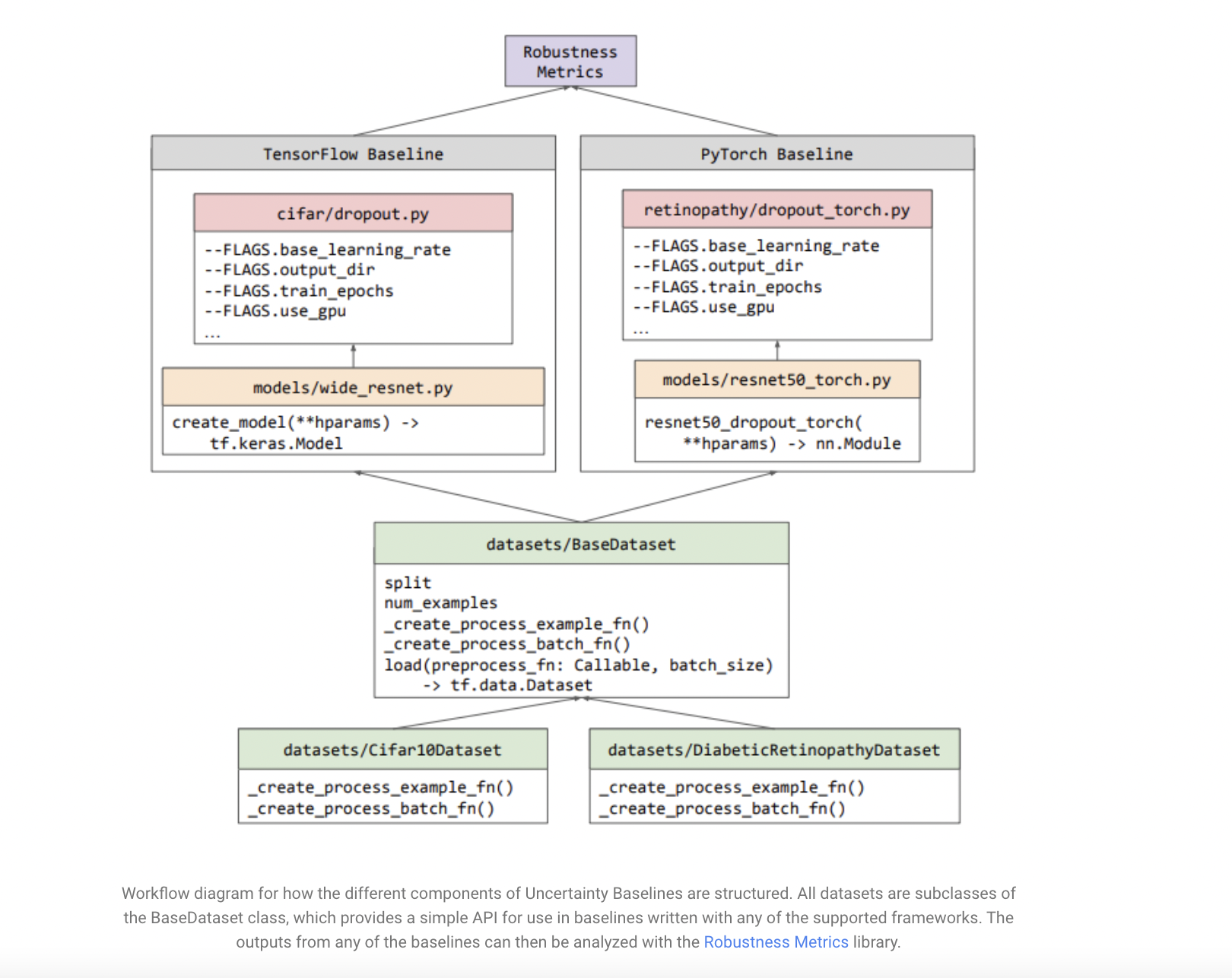
In order to tackle this problem and get a hold of a Machine Learning model’s behavior, the researchers at Google have introduced the concept of Uncertainty Baselines for every task of interest. These are a collection of high-quality implementations of standard and state-of-the-art deep learning methods on various tasks. The collection spans nineteen methods across nine tasks, each with a minimum of five metrics.
A baseline, in general, is defined as a number that is a reasonable and defined starting point for comparison studies. Each baseline in the collection is a self-contained experiment pipeline with effortlessly reusable and extendable constituents. The pipelines have been executed in TensorFlow, PyTorch, and Jax with limited dependencies outside the framework. The hyperparameters for each baseline have been trained across numerous iterations to provide cut-above results.
In this research, Uncertainty Baselines provide 83 baselines incorporating 19 methods encompassing more latest strategies. Some of the methods are BatchEnsemble, DeepEnsembles, Rank 1 Bayesian Neural Nets, and acts as a successor in coalescing various benchmarks in the community. Each baseline is tuned over its hyperparameters to maximize performance for a given set of metrics.

The baselines vary among three different axes:
- Base Models: Simple fully-connected networks.
- Training Datasets: Data required to train a machine learning model.
- Evaluation Metrics: Predictive Metrics like accuracy, Uncertainty metrics like calibration error, computational metrics like inference latency.
To enable easy use of these baselines, they are deliberately optimized to be as minimal and modular as possible. Instead of establishing new class abstractions, pre-existing ones are used. The train/evaluation pipeline is contained in a standalone python file for a particular experiment to ensure independence among the different baselines. It can be developed in any of TensorFlow, PyTorch, or JAX. Simple python flags defined using Abseil are used to manage hyperparameters and other experiment configuration values.
In the future, the researchers aim to release hyperparameter tuning results and final model checkpoints to allow the reproducibility of baselines. They also assure that the repository has undergone extensive hyperparameter tuning and can be readily used by other researchers without retraining or retuning. The researchers hope to avoid minor differences in the pipeline implementations which tend to affect baseline comparisons and urge people to contribute new methods to the repository.
Paper: https://arxiv.org/pdf/2106.04015.pdf
Github: https://github.com/google/uncertainty-baselines
Source: https://ai.googleblog.com/2021/10/baselines-for-uncertainty-and.html
Suggested
Credit: Source link
Comments are closed.