A New AI-Based Method Called SparseGPT can Prune Generative Pretrained Transformer (GPT) Family Models in One Shot to at least 50% Sparsity
Amazing performance across many tasks has been demonstrated by the Generative Pretrained Transformer (GPT) family of large language models (LLMs). However, they are cumbersome to deploy due to their high computing requirements. As a result, it’s not surprising that there’s been so much focus on model compression to cut down on these expenses. Quantization, or decreasing the accuracy of the numerical representation of individual weights, has been the primary emphasis of nearly all previous GPT compression methods.
Model compression can be complemented by the pruning process, which removes unused parts of the network, ranging from individual weights (unstructured pruning) to larger chunks like rows and columns of the weight matrices (structured pruning). However, in the case of GPT-scale models, considerable retraining of the model is required to recoup from the accuracy loss due to removing parts, which can be quite costly. As a result, precise pruning of GPT3-scale models has seen almost no development yet.
A new study by IST Austria and Neural Magic presents SparseGPT, the first precise one-shot pruning strategy that scales well to models with 10100 billion parameters. SparseGPT solves the pruning problem by treating it as a massively-scaled application of sparse regression. The algorithm relies on a new approximation sparse regression solver to solve a layer-wise compression problem and is fast enough to run on the largest openly-available GPT models (175B parameters) in a matter of hours on a single GPU. Yet, SparseGPT is accurate enough to lose just a tiny amount of accuracy after pruning.
When tested using the largest publicly accessible generative language models (OPT-175B and BLOOM-176B), the researchers discovered that running SparseGPT in one-shot causes 50-60% sparsity with negligible accuracy loss, measured either in terms of perplexity or zero-shot accuracy.
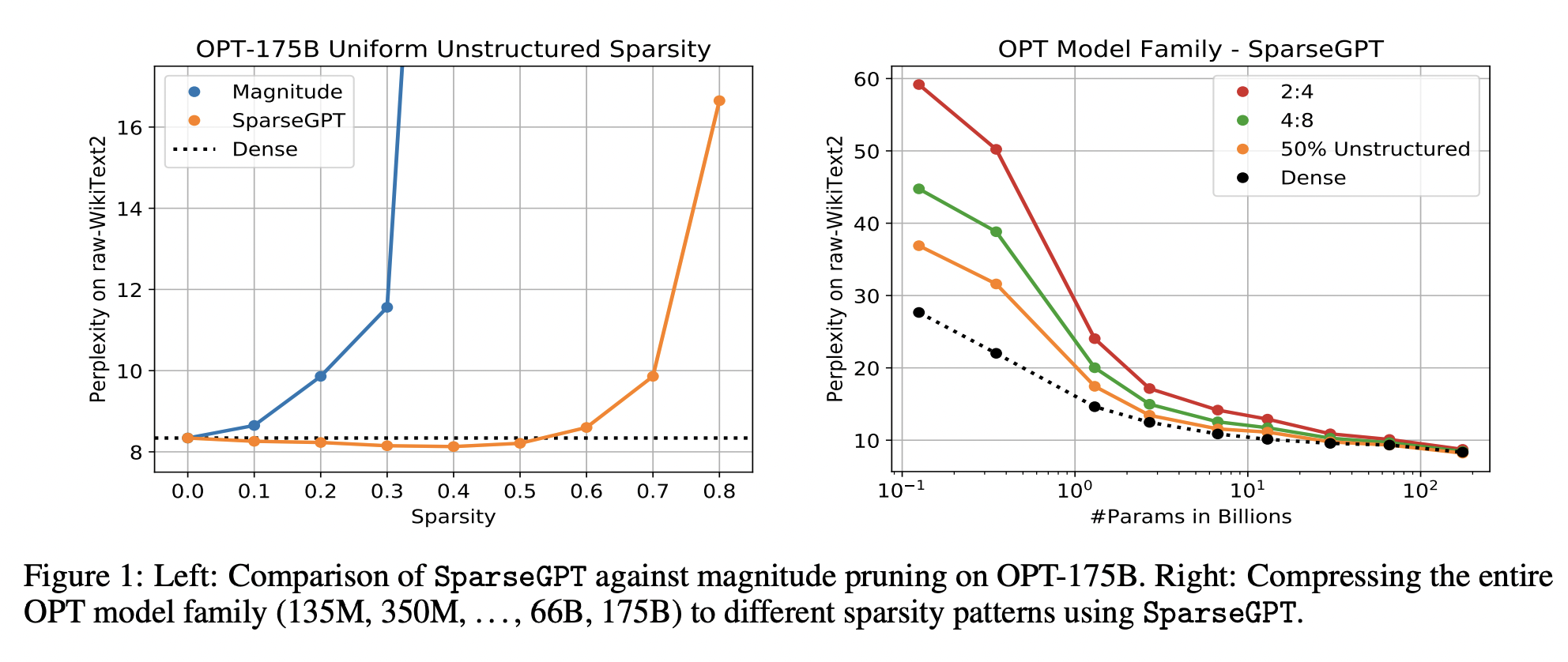
Two crucial points emerge from their experimental results:
- The 175-billion-parameter variant of the OPT family can have up to 60% of its parameters replaced by sparse ones using SparseGPT with only a modest hit to accuracy. In contrast, at 30% sparsity, Magnitude Pruning collapses and is the only known one-shot baseline that works at this scale.
- In addition to the less restrictive 1:1 and 1:2 semi-structured sparsity patterns, SparseGPT can reliably enforce sparsity in the more demanding 2:4 and 4:8 semi-structured sparsity patterns, which are nonetheless hardware-friendly. Although these patterns typically suffer from additional accuracy loss compared to the dense baseline, especially for the smaller models, these sparsity patterns can be directly exploited to obtain computational speedups. The sparsity introduced by the suggested method also adds to the compression achieved by quantization.
The suggested approach is intriguing since it is completely local; it does not use any global gradient information and instead computes weight updates that aim to maintain the input-output relationship for each layer. That such sparse models may be directly identified in the “neighborhood” of dense pretrained models, whose output corresponds remarkably closely with that of the dense model, is amazing.
They also found that the relative accuracy gap between the dense and sparse model variant narrows as model size increases to the point where inducing 50% sparsity results in practically no accuracy decrease on the largest models. This is consistent with the observation that larger models are easier to sparsify. The group is hoping their discoveries will inspire others to focus on further compressing such large models.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.