A New AI Research Presents a Cascading Latent Diffusion Approach Called Moûsai That can Generate Multiple Minutes of High-Quality Stereo Music at 48kHz from Textual Descriptions
It is a difficult topic because music generation, or audio generation, includes numerous components at various levels of abstraction. Although difficult, automated or model-assisted music production has been a popular study topic. It is encouraging to observe how much deep learning models can contribute to audio production, given the recent emergence of deep learning models and their success in computer vision and natural language processing. Recursive neural networks, adversarial generative networks, autoencoders, and transformers are all used in existing audio-generating models.
Diffusion models, a more recent development in generative models, have been employed in voice synthesis but have yet to be fully investigated for music creation. In addition, there are several persistent difficulties in the field of music synthesis, including the need to:
- Model the long-term structure.
- Enhance the sound quality.
- Broaden the musical variety.
- Enable simpler control of the synthesis, such as text prompts.
Allowing individuals to produce music using an approachable text-based interface can empower the general public to participate in the creative process. It can also help creators find inspiration and offer an endless source of original audio samples. The music industry would benefit greatly from adding a single model that could handle all the suggested features.
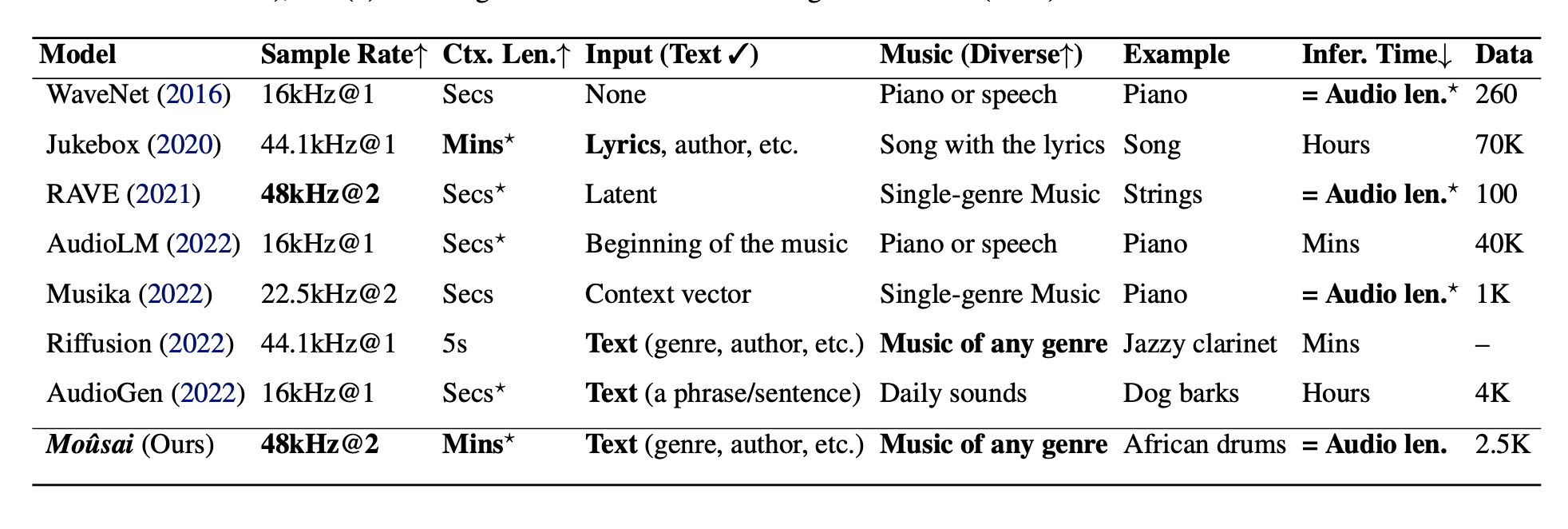
They can observe from Table 1’s landscape of existing music-generating models that the difficulties above are pervasive in the literature. For instance, most text-to-audio systems can only produce a few seconds of audio. Many often need a lengthy inference period of up to several GPU hours to make a minute of audio. When it comes to unconditional music creation, which is distinct from text-to-music generation models, some can produce high-quality samples and operate in real time on the CPU. Still, they are often trained on a single modality and need help handling long-term structures. To this purpose, they put forth Moûsai 2, a text-conditional cascading diffusion model (Figure 1) that aims to address each of the issues above simultaneously.
Their Moûsai model takes advantage of the unique two-stage cascading diffusion technique depicted in Figure 1. The audio waveform is compressed using a novel diffusion autoencoder in the first step. The second stage’s reduced latent representations are learned based on the text embedding produced by the pretrained language model. Both phases employ an effective U-Net that they have tuned, providing quick inference speed that enables use in upcoming applications plausible.

As a result, the following are the primary contributions of Their work:
1. Based on context exceeding the minute mark, they enable the generation of long-context 48kHz stereo music exceeding the minute mark and generate a diversity of music.
2. they suggest a productive 1D U-Net architecture for both stages of the cascade, allowing for the real-time production of audio on a single consumer GPU. Additionally, because each step of Their system can be taught on a single A100 GPU in about a week, the entire system can be trained and operated with the modest resources found in most colleges.
3. they describe a new diffusion magnitude autoencoder that, when used by the generation stage of the architecture to apply latent diffusion, can compress the audio signal 64 times compared to the original waveform with only minimal quality loss.
Check out the Paper, Github, and Demo. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.