Researchers at Sony Introduces M2FNet: A Multi-modal Fusion Network for Emotion Recognition in Conversation
Knowing how people engage with content is a crucial skill. Unseen mental states connected to thinking and feeling are called emotions. Without physical cues, they would have to rely on human movements like speech, gesture, and sound to identify them.
Emotion Recognition in Conversations (ERC) aims to analyze textual, visual, and auditory information to identify the emotions expressed in a conversation. Using ERC to analyze and moderate multimedia information has rapidly become more important. It can be used for AI interviews, individualized conversational interfaces, analysis of user sentiment, and contextualizing material on social media sites like YouTube, Facebook, and Twitter.
Many state-of-the-art methods for performing robust ERC rely on text-based processing, which ignores the large amounts of information available from the auditory and visual channels.
The media analysis group from Sony Research India believes that the performance and robustness of existing systems can be enhanced by fusing the three modalities present in the ERC data: text, visual, and auditory. The ERC system accepts a sample of emotional expressions across three modalities as input and predicts the corresponding emotion for each.
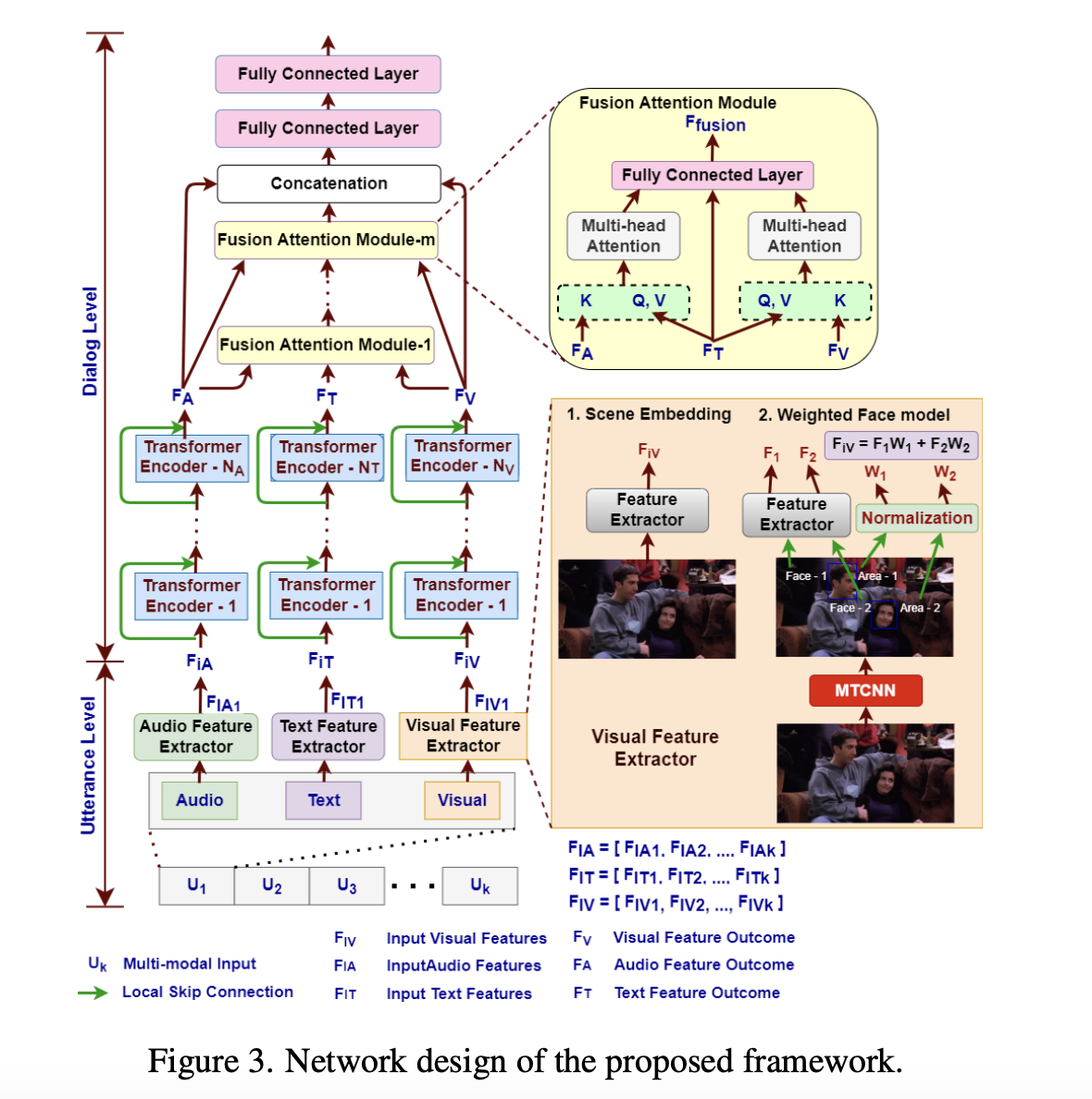
Their new study introduces a multimodal fusion network (M2FNet) that uses a novel multi-head fusion attention layer to make the most of the media’s inherent diversity. Layers of audio and visual data are mapped to the latent space of textual properties, allowing for the generation of rich representations that are emotionally relevant. Using all three modalities improves accuracy, and the suggested method’s Fusion process further boosts accuracy.
There are two key phases to this concept:
- Utterance Level performs feature extraction on an individual utterance (Intra-Speaker) and modality level.
- Halfway through the Dialog Level, features are retrieved for each inter-speaker (Inter-Speaker), and contextual information is recorded.
The final emotion labels are estimated when the link between modalities is retrieved.
A previous study demonstrated that treating voice data as an image rather than a mel-spectrogram of plotted frequency characteristics improves emotion recognition accuracy. Inspired by this, M2FNet extracts features from a spoken language, like images extracted from text. To extract more emotion-related data from videos, M2FNet presents a Dual Network that takes into account not just the person’s facial emotions but also the entire frame to capture the context.
In addition, they also suggest a new model for feature extraction using exHere. They develop a new adaptive margin-based triplet loss function that facilitates the proposed extractor’s ability to acquire accurate representations.
The team states that each embedding’s inability to boost accuracy on its alone demonstrates the importance of scene context in addition to aspects of facial expressions in recognizing emotions. They introduce a dual network inspired by merging the scene’s emotional content, considering the different persons in it. Furthermore, the research shows that the performance of state-of-the-art ERC approaches diminishes on more complicated datasets like MELD, notwithstanding their success on one benchmark dataset like IEMOCAP.
Over 1,400 chats and 13,000 utterances from the “Friends” television series make up MELD. Seven emotion labels—anger, contempt, sadness, joy, surprise, fear, and neutral—are applied to each statement. The pre-made Train/Valid is utilized exactly as is.
IEMOCAP is a conversational database with six emotion labels: happy, sad, neutral, furious, excited, and irritated. In the experiment, 10% of the training data was randomly chosen and utilized to tune the hyperparameters. 10% of the training data were randomly chosen to create the database.
The team experimented with comparing the proposed network’s performance against existing text-based and multimodal ERC techniques, verifying the network’s robustness. They compared the MELD and IEMOCAP datasets as weighted average F1 scores. The results suggest that the M2FNet model outperforms the competition by a significant margin when comparing weighted average F1 scores. The findings also suggest that M2FNet effectively used multimodal characteristics to enhance the precision of emotion recognition.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.