Meet AudioLDM: A Latent Diffusion Model For Audio Generation That Trains On AudioCaps With A Single GPU And Achieves SOTA Text-To-Audio (TTA) Performance
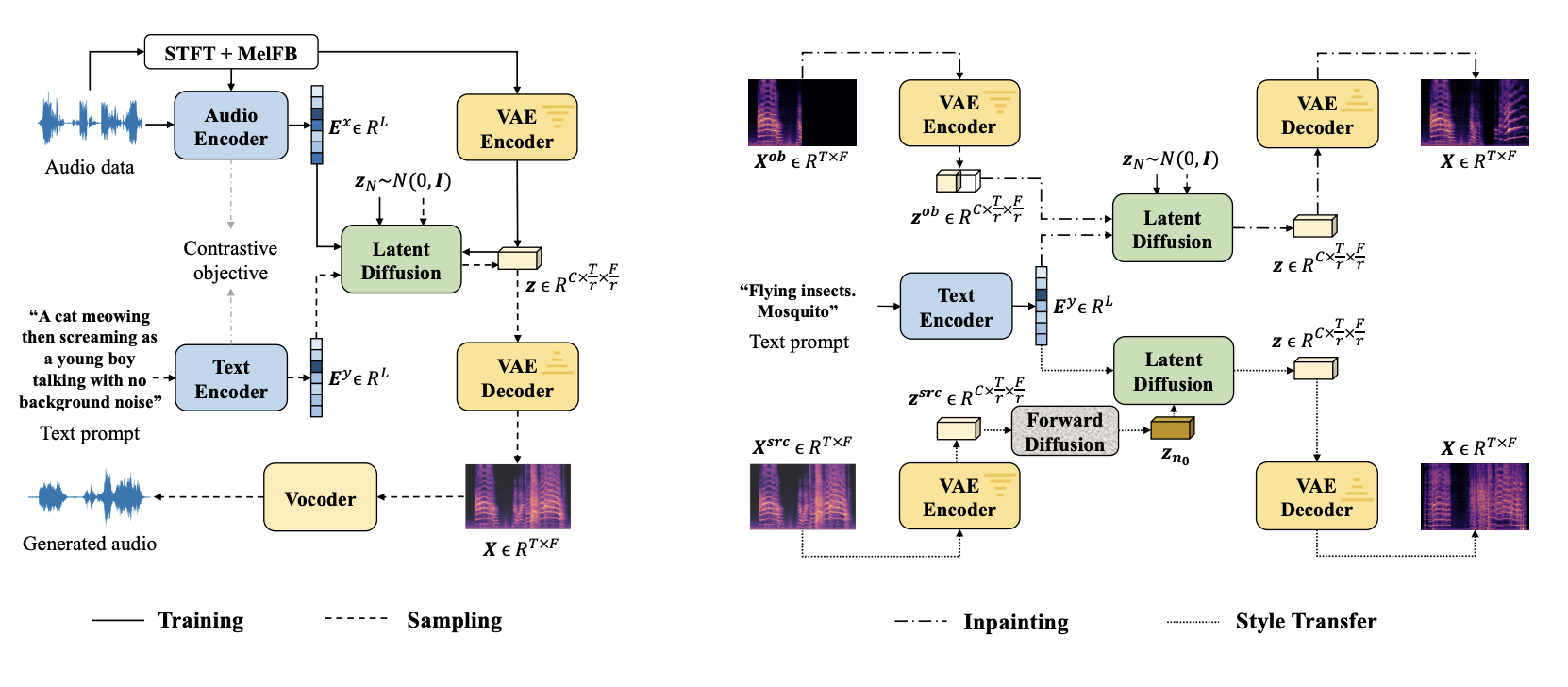
For many applications, like augmented and virtual reality, game creation, and video editing, it is crucial to produce sound effects, music, or speech by specific criteria. Traditionally, signal processing techniques have been used to generate audio. Recent years have seen a revolution in this job thanks to generative models, either unconditionally or dependent on other modalities. A modest collection of labels, such as the ten sound classes in the UrbanSound8K dataset, were used in previous experiments that mainly focused on the label-to-sound setting. Natural language, in contrast, is far more versatile than labels since it may contain fine-grained descriptions of auditory signals (e.g., pitch, acoustic environment, and temporal order).
Text-to-audio (TTA) generation is the process of producing audio that is suggested by natural language descriptions. TTA systems may provide a variety of high-dimensional audio streams. They build the generative model in a learning compact latent space to model the data efficiently. Similar concepts are used by DiffSound, a program that uses diffusion models to learn a discrete representation compressed from an audio file’s mel-spectrogram. In a discrete space of waveforms, AudioGen’s autoregressive model has supplanted DiffSound. They investigate latent diffusion models (LDMs) for TTA generation on a continuous latent representation rather than learning discrete representations because StableDiffusion employs LDMs to provide high-quality images as inspiration.
Additionally, they study and accomplish different zero-shot text-guided audio alterations with LDMs, which have never been proven before because audio manipulations like style transfer are also needed for audio signals. The need for large-scale, high-quality audio-text data pairs, typically not easily available and of restricted quality and quantity, might be a significant barrier to generation quality for past TTA studies. Several text preparation techniques have been suggested to use the data with noisy text captions better. However, by removing the relationships between sound events in their preprocessing processes, they inevitably restrict the performance of their creation (e.g., a dog barking at the bark is transformed into a dog bark park). This study addresses this issue by developing a technique that outperforms audio-text paired data and requires audio data for generative model training.
This paper introduces a TTA system called AudioLDM that benefits from computational efficiency and text-conditional audio manipulations while achieving state-of-the-art generation quality with continuous LDMs. In particular, AudioLDM learns to produce the audio prior in a latent space encoded by a variational auto-encoder based on mel-spectrograms (VAE). An LDM conditioned on the contrastive language-audio pretraining (CLAP) latent embedding is created for an earlier generation. They reduce the need for text data during training LDMs by utilizing this audio-text-aligned embedding space since the demand for the previous generation can come straight from the audio.
They show that training LDMs with audio alone is sometimes more effective than training with audio-text data pairs. On the AudioCaps dataset, the proposed AudioLDM outperforms the DiffSound baseline by a significant margin with a freshet distance (FD) of 23,31, achieving state-of-the-art TTA performance. Their method allows zero-shot audio changes throughout the sampling process in the interim. Their contributions, in brief, are as follows:
• They show the first attempt at creating a continuous LDM for TTA generation and perform better than current techniques in both subjective and objective criteria.
Without employing language-audio pairings to train LDMs, they generate TTA using CLAP latents.
• They demonstrate experimentally that a high-quality and computationally efficient TTA system can be created utilizing audio data during LDM training.
• They demonstrate that, without fine-tuning the model for a particular job, their proposed TTA system can execute text-guided audio style modification, such as audio style transfer, super-resolution, and inpainting. The code can be accessed at GitHub.
Check out the Github, Project, and Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.