Welcome to the New Saga Introduced by MusicLM: This AI Model can Generate Music from Text Descriptions
There has been an explosion of generative AI models in the last couple of months. We’ve seen models that could generate realistic images from text prompts, looking at you Stable Diffusion, text generation in a given topic, now looking at you ChatGPT and GPT-3, video generation from text inputs, now it’s your turn MakeAVideo, and more. The advancement was so fast that, at some point, we thought the curtain between reality and virtual reality was almost coming down.
We are still not done with visual and textual generation models. They still have a long way to go until they reach a point where it would not be possible to differentiate AI-generated content from human-generated one. Until then, let us sit back and enjoy the beautiful progress.
Speaking of progress, people are not stopping to think of other text-to-X use cases. We’ve seen numerous models targeted for text-to-image, text-to-video, text-to-speech, etc. Now, get ready for the next saga of text-to-X models. Text-to-Music.
👉 Read our latest Newsletter: Diffusion models less private than prior generative models such as GANs; Can LLMs extract knowledge graphs from the unstructured text?…
The task of generating audio from a certain condition is called conditional neural audio generation. Such tasks include text-to-speech, lyrics-conditioned music generation, and audio synthesis from MIDI sequences. Most of the existing work in this field relies on temporally aligning the source signal, which is the condition, with the corresponding audio output.
On the other hand, some studies were inspired by the success of text-to-image models, and they explored generating audio from more generic captions like “melodic techno with waves hitting the shore.” However, those models were limited in their generation capacity and could only generate simple acoustic sounds for just a couple of seconds. So, we still have the open challenge of generating a rich audio sequence with long-term consistency and many stems, similar to a music clip, given a single text caption. Well, let’s just say it looks like the challenge is close to being closed now, thanks to MusicLM.
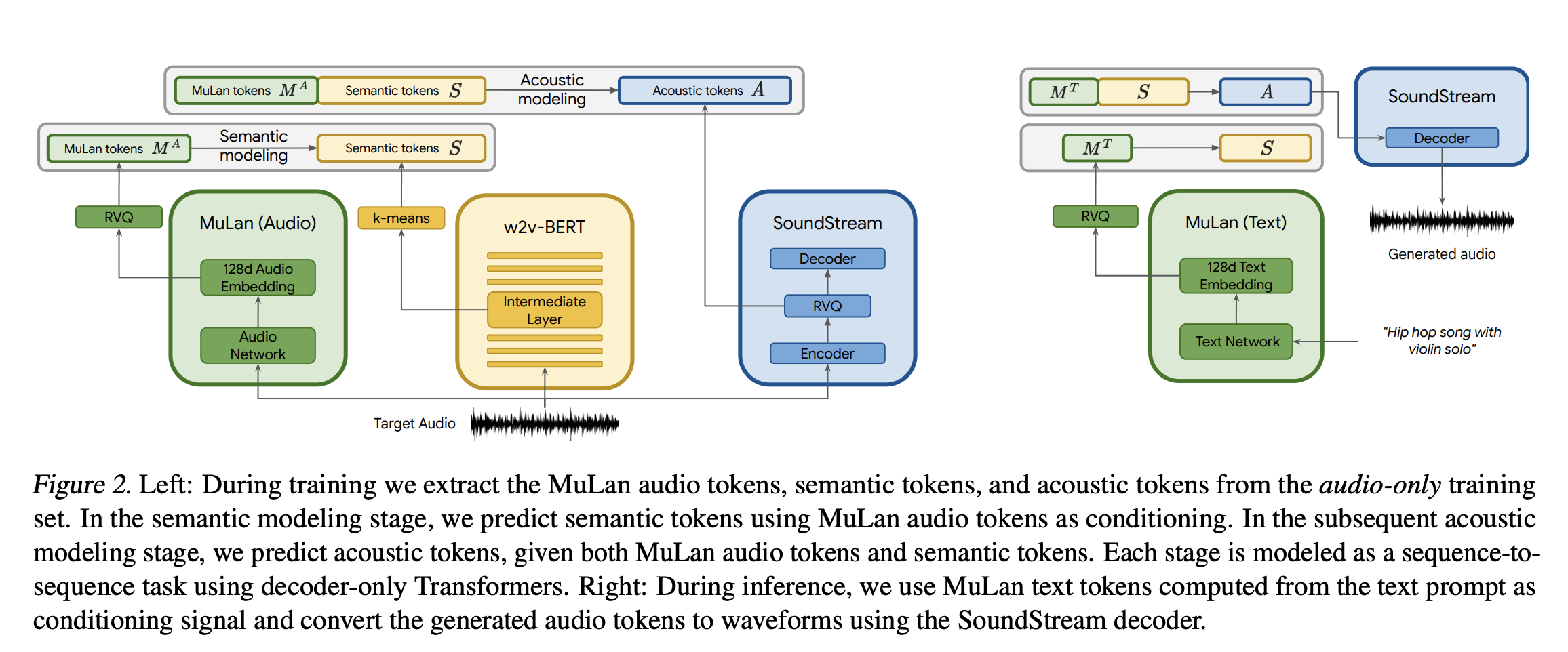
Treating audio generation as a language task using a system of simple to complex audio units, like words in a sentence, makes audio sound better and more consistent over time. Existing models used this approach, and MusicLM follows the same trend. However, the biggest challenge here is to construct a proper large-scale dataset.
Regarding text-to-image datasets, we have many massive datasets that contributed a lot to the significant development in recent years. This sort of dataset is missing for the text-to-audio task, making it really tricky to train large-scale models. Also, preparing text captions for the music is not as straightforward as image captioning. It is difficult to capture salient characteristics of acoustic scenes or music with just a few words. How can you describe all those vocals, rhythms, instruments, etc.? Also, audio is continuous; it does not have a stable structure as an image. This makes sequence-wide captions a much weaker level of annotation for audio.
MusicLM solves this problem by using an existing model, MuLan, that is trained to project music to its corresponding text description. MuLan projects audios to a shared embedding space, eliminating the need for captions during the training phase, thus enabling MusicLM to use just the audio data during training. Overall, MusicLM uses MuLan embeddings computed from the audio during the training and MuLan embeddings computed from the text during the inference.
MusicLM is the starting point of a new era of text-to-music. It is trained with a large-scale unlabeled music dataset. It can generate long and coherent music at 24 kHz, using complex text descriptions. Also, they propose an evaluation dataset named MusicCaps that contains music descriptions done by experts, which could be used to evaluate upcoming text-to-music models.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.