A New Artificial Intelligence Research Proposes Multimodal Chain-of-Thought Reasoning in Language Models That Outperforms GPT-3.5 by 16% (75.17% → 91.68%) on ScienceQA
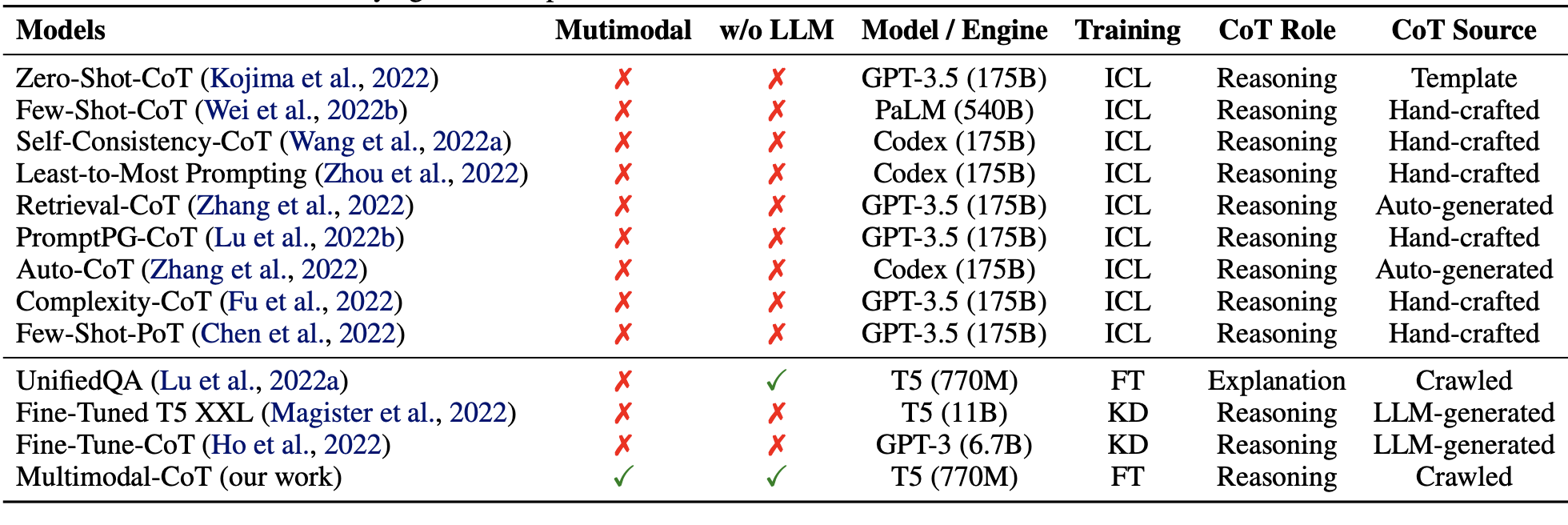
Due to recent technological developments, large language models (LLMs) have performed remarkably well on complex and sophisticated reasoning tasks. This is accomplished by generating intermediate reasoning steps for prompting demonstrations, which is also known as chain-of-thought (CoT) prompting. However, most of the current work on CoT focuses solely on language modality, and to extract CoT reasoning in multimodality, researchers frequently employ the Multimodal-CoT paradigm. Multimodal-CoT divides multi-step problems into intermediate reasoning processes, generating the final output even when the inputs are in various modalities like vision and language. One of the most popular ways to carry out Multimodal-CoT is to combine the input from multiple modalities into a single modality before prompting LLMs to perform CoT. However, this method has several drawbacks, one being the significant information loss that occurs while converting data from one modality to another. Another way to accomplish CoT reasoning in multimodality is to fine-tune small language models by combining different features of vision and language.
However, the main issue with this approach is that these language models have the propensity to produce hallucinatory reasoning patterns that significantly affect the answer inference. To lessen the impact of such errors, Amazon researchers proposed Multimodal-CoT, which combines visual features in a decoupled training framework. The framework divides the reasoning process into two phases: rationale generation and answer inference. The model produces more persuasive arguments by including the vision aspects in both stages, which helps to create more precise answer inferences. This work is the first of its kind that studies CoT reasoning in different modalities. On the ScienceQA benchmark, the technique, as provided by Amazon researchers, demonstrates state-of-the-art performance, outperforming GPT-3.5 accuracy by 16% and surpassing human performance.
The Multimodal-answer CoT’s inference and reasoning-generating stages use the same model architecture and differ in the kind of input and output. Taking the example of a vision-language model, the model is fed data from both the visual and language domains during the rationale generation stage. Once the rationale has been produced, it is then added to the initial language input in the answer inference step to create the language input for the following stage. The model is then given the updated data and trained to produce the desired result. A transformer-based model that performs three main functions (encoding, interaction, and decoding) provides the basis of the underlying model. To put it simply, the language text is supplied into a Transformer encoder to create a textual representation. This textual representation is then combined with the vision representation and fed into the Transformer decoder.
👉 Read our latest Newsletter: Microsoft’s FLAME for spreadsheets; Dreamix creates and edit video from image and text prompts……
In order to assess the effectiveness of their method, the researchers ran many tests on the ScienceQA benchmark, a large-scale dataset of multimodal science questions that contains over 21k multimodal MCQs with annotated answers. The researchers concluded that their approach outperforms the prior state-of-the-art GPT-3.5 model by 16% on the benchmark. In a nutshell, researchers from Amazon investigated and solved the issue of eliciting Multimodal-CoT reasoning by putting forth a two-stage framework by fine-tuning language models to combine vision and language representations to execute Multimodal-CoT. The model, thus, generates informative rationales to facilitate inferring final answers. The GitHub repository for the model can be accessed below.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.