Google Research Introduces An Extension of PyGlove: A General Purpose Python Library That Can Now Easily And Scalably Share Machine Learning Ideas As Code
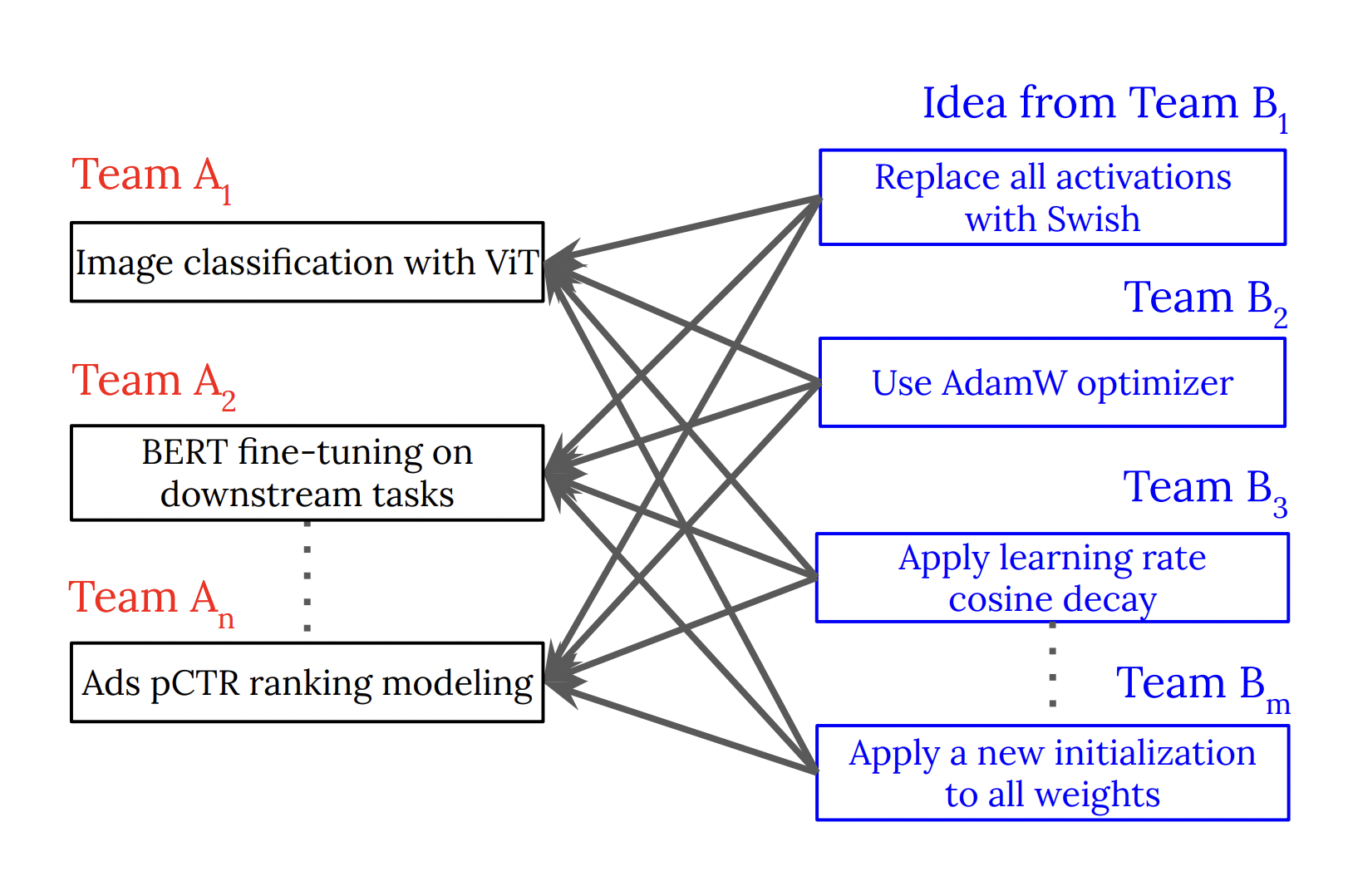
Over the past few years, machine learning (ML) partnerships have grown significantly in scale, making it more challenging to share code efficiently. Multiple scholars and engineers can connect through universities, GitHub projects, and technological firms. Many separate teams that share a codebase are frequently formed, particularly in technology businesses. Other groups must incorporate the insights made by these teams into their code. However, challenges may arise due to the specialization of teams and codebases. The most typical approach is for each team to keep an eye out for findings made by other teams and then apply those discoveries to their ML system. This process might take a long period when there are too many innovations or when they are difficult or need specialized expertise.
There are further difficulties with the alternate technique, such as inadequate access or documentation, when the innovators implement their discoveries in other codebases directly. Most significantly, these expenses are spent each time there is an interchange between two teams. The same idea is executed more than once, resulting in poor scalability as there are more inventions. They introduce PyGlove in this article as an expansion of their earlier work to streamline the scale sharing of ideas as code. A novel idea may be used in several locations with little implementation work, thanks to PyGlove. By announcing their finding programmatically, the innovators themselves may update the code of other teams. At a high level, PyGlove utilizes rule-based fixes and annotations.
A codebase must first be peppered with properly structured, lightweight Python annotations that explain the code at an understandable level in order to make it PyGlove-compatible. The code-sharing will be conducted using annotations as a common language. After completing it, code may be transferred using rule-based patches that specify where the ported code must be. Consider a scenario where “team A” maintains a classifier for images and “team B” independently develops a new convolutional layer that should enhance most classifiers. According to the PyGlove method, team A can annotate their (pre-existing) code with phrases like “this is a convolution,” “this is a nonlinearity,” and so on. In contrast, team B would annotate their new layer with phrases like “these are hyperparameters.”
👉 Read our latest Newsletter: Google AI Open-Sources Flan-T5; Can You Label Less by Using Out-of-Domain Data?; Reddit users Jailbroke ChatGPT; Salesforce AI Research Introduces BLIP-2….
Team A can create a one-line rule that says, “replace all my convolutions with team B’s layer” after learning about the new layer, as illustrated in Figure 2. A unique twist is also possible thanks to PyGlove: Team B may create its own replacement rule, which is equivalent to saying, “in every image classifier, replace all convolutions with their layer.” After then, the rule developed by team B may be used by any team with a PyGlove-annotated image classifier. This unexpected turn gives many possibilities for future cooperation through the ML innovation repositories they outline in their paper. They point out that the convolution-layer-exchange scenario was used as an instance because it is relatively basic.
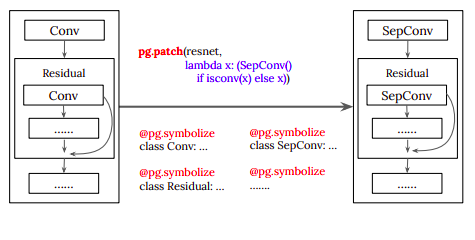
The rule-based approach used by PyGlove extends to all parts of the ML pipeline, including data augmentation, training algorithms, and meta-learning, and is not only limited to the sharing of architectural modifications. Particularly, scaling up model capacity is frequently required as ML technology advances. To solve this issue, empirical and theoretical principles have been developed. Such regulations might be made known to everyone in a group or neighborhood, saving critical engineer time. Due to a “network effect” among teams, PyGlove’s adoption cost can be swiftly compensated by its advantages. The work required to annotate a codebase when only the new annotations themselves need coding is the adoption cost. Since these are common Python annotations, most of the original code remains intact.
On the other side, PyGlove offers advantages that teams may take advantage of whenever they share ideas. When m innovations are applied to n team projects without PyGlove, the work is mn; however, with PyGlove, each innovation necessitates the creation of a PyGlove rule (m rules), and each team project is in charge of adding PyGlove annotations to their model (n models), resulting in only m + n work since the rule application is trivial. In each of these instances, their rule-based methodology differs from existing approaches, which frequently ask for numerous in-place adjustments and need to scale better with the model’s size or the number of practitioners in the community.
The open-sourced PyGlove library and supplemental code are used in this paper and The open-sourced PyGlove library. For instance, their case study of one sizable codebase revealed that PyGlove adoption resulted in an 80% decrease in the number of lines of code. Because of PyGlove’s fundamental symbolic programming nature, it may be used to write ML code in all of its facets and code for other purposes outside of ML. This paradigm transforms Python objects annotated with PyGlove into editable symbols, and PyGlove rules are meta-programs that operate on these symbols. To sum up, they present A method for effectively and scalable sharing complex ML ideas as code using symbolic patches, An example of how symbolic programming can be used throughout the ML development process. PyGlove is open source, and usage instructions can be found on their GitHub.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.