Google And Columbia University Researchers Introduce Mnemosyne Optimizer: A Learning-To-Learn System To Train Transformers With Transformers
While it may seem appealing to train ML optimizers, doing so is costly because the examples used to train these systems are optimization issues. Generalization in this context refers to the capacity to apply knowledge to “similar” optimization tasks that were not encountered during training.
The concept that has revolutionized ML—replacing hand-engineered features with learnable ones—can be seen as a natural lifting (to the optimizer space) by learning-to-learn (L2L) systems. It gets difficult and requires its topic to conduct a rigorous mathematical investigation of the attributes of L2L systems that entails defining distributions over optimization problems.
The new study Mnemosyne: Learning to Train Transformers with Transformers by a Google and Columbia University team proposes Mnemosyne Optimizer, an L2L system meant to train whole neural network topologies without any task-specific optimizer tuning.
👉 Read our latest Newsletter: Google AI Open-Sources Flan-T5; Can You Label Less by Using Out-of-Domain Data?; Reddit users Jailbroke ChatGPT; Salesforce AI Research Introduces BLIP-2….
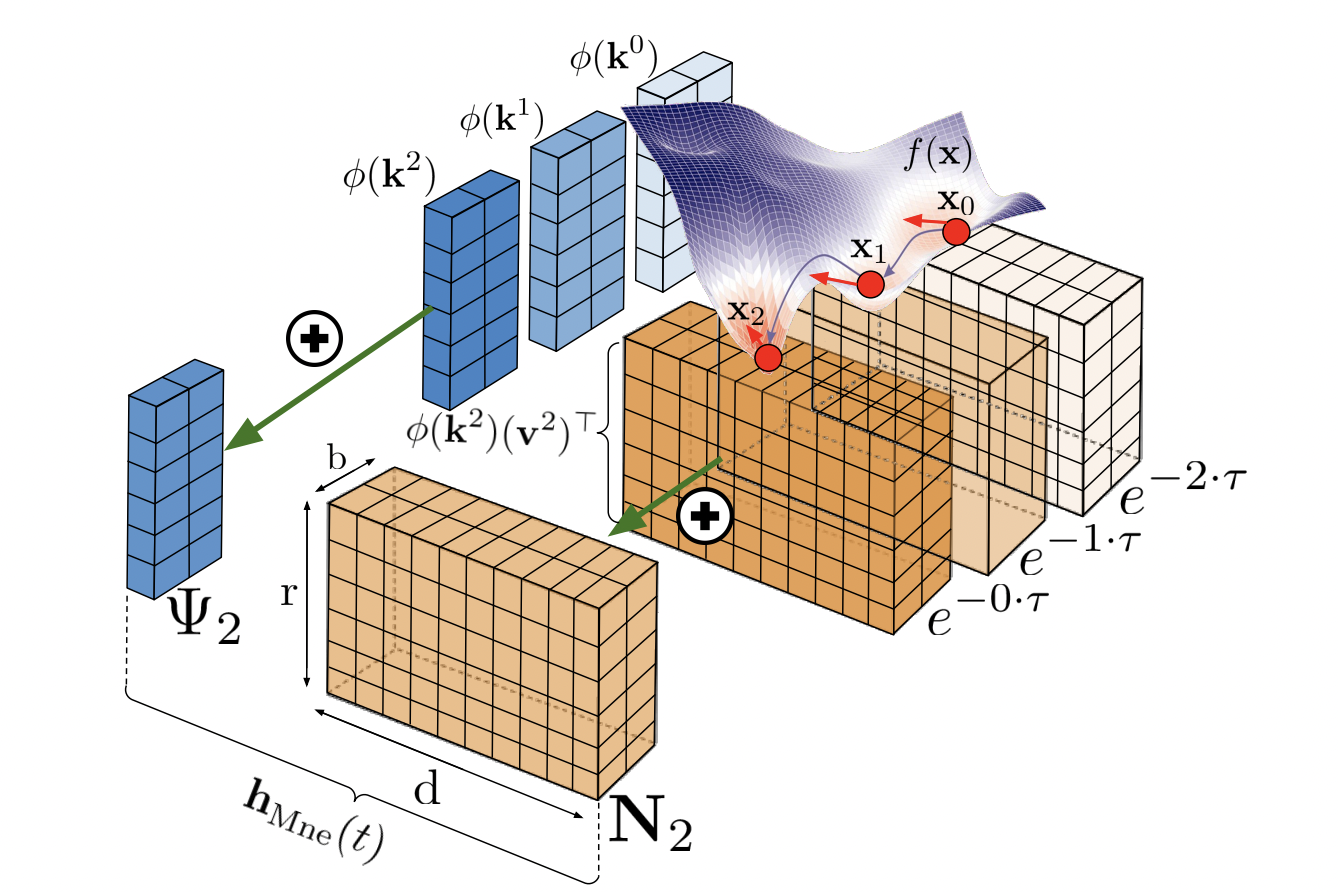
Scalable low-rank implicit attention memory cells used in Performer architectures constitute the basis of Mnemosyne, together with techniques for estimating attention via low-rank decomposition of the attention matrix. Mnemosyne is built to reduce the quadratic complexity cost of conventional attention while simultaneously training a full neural network architecture.
Standard transformers can be considered differentiable dictionaries that employ potent associative memory processes with exponential memory. Meanwhile, linear low-rank attention mechanisms are more space-efficient and ideal for large-scale memory systems.
The key advantages of Mnemosyne, as identified by the researchers, are as follows:
- It has better generalization than state-of-the-art LSTM optimizers.
- Meta-trained on conventional multilayer perceptrons, it can successfully train vision transformers (ViTs) (MLPs).
- In robotics applications, it can initialize optimizers, resulting in faster convergence.
Mnemosyne was meta-trained and tested across a number of different NN training tasks using a wide variety of architectures and data sets in this empirical work. As demonstrated by the results, Mnemosyne can optimize MLPs using a wide variety of NN designs and activation functions, and it does it more quickly than competing optimizers.
The team theoretically examines Mnemosyne’s compact associative memory (CAM), showing that it can store and restore patterns much like its usual non-compact equivalents but stands out favorably in its ability to do so in an implicit manner.
According to the researchers, their study believes that the algorithmic heart of Mnemosyne is the first to give such significant capacity results. They hope this will serve as a springboard for future investigation into using learnable attention-based optimizers to solve the extremely challenging challenge of training Transformers.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.