Meet OnePose++: A Novel AI Keypoint-Free One-Shot Object Pose Estimation Framework Without CAD Models
Recent developments in Artificial Intelligence (AI) have been truly remarkable, with rapid advancements in deep learning and other machine learning techniques leading to breakthroughs in a wide range of applications. One of the mentioned applications refers to as object pose estimation.
Object pose estimation is a field of computer vision that aims to determine the location and orientation of objects in an image or a video sequence. It is a crucial task for many applications, such as augmented reality, robotics, and autonomous driving. Object pose estimation can be performed using a variety of techniques, including 2D keypoint detection and 3D reconstruction. The ultimate goal of object pose estimation is to provide a rich representation of the objects in the scene, including their position and orientation, shape, size, and texture.
Object pose estimation is crucial for immersive human-object interactions in augmented reality (AR). The AR scenario demands the pose estimation of arbitrary household objects in our daily lives. However, most existing methods either rely on high-fidelity object CAD models or require training a separate network for each object category. These methods’ instance- or category-specific nature limits their applicability in real-world applications.
Recent techniques have been investigated to overcome these issues and limitations.
Large models LMs can teach themselves to use external tools via simple APIs; 🚨 If 2022 is the year of pixels for generative AI, then 2023 is the year of sound waves……
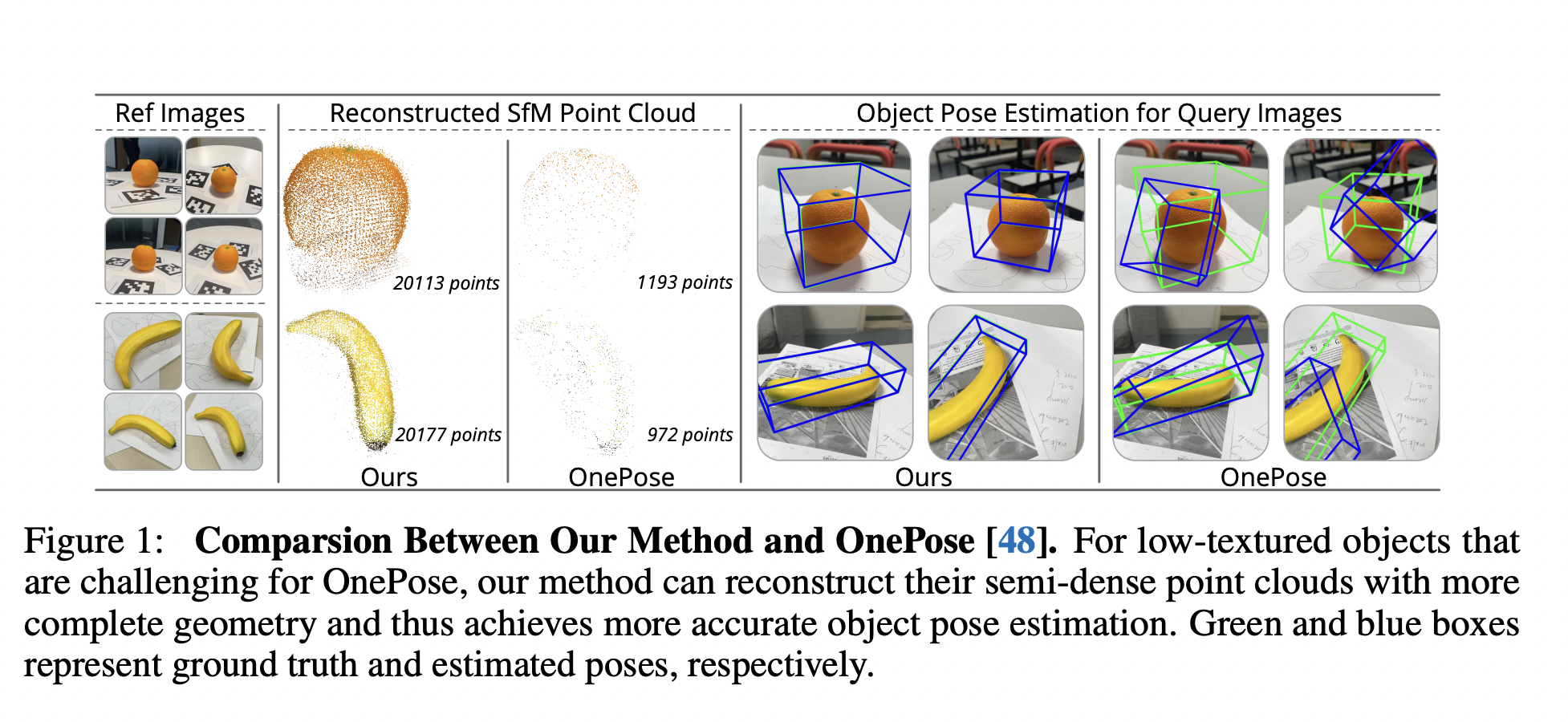
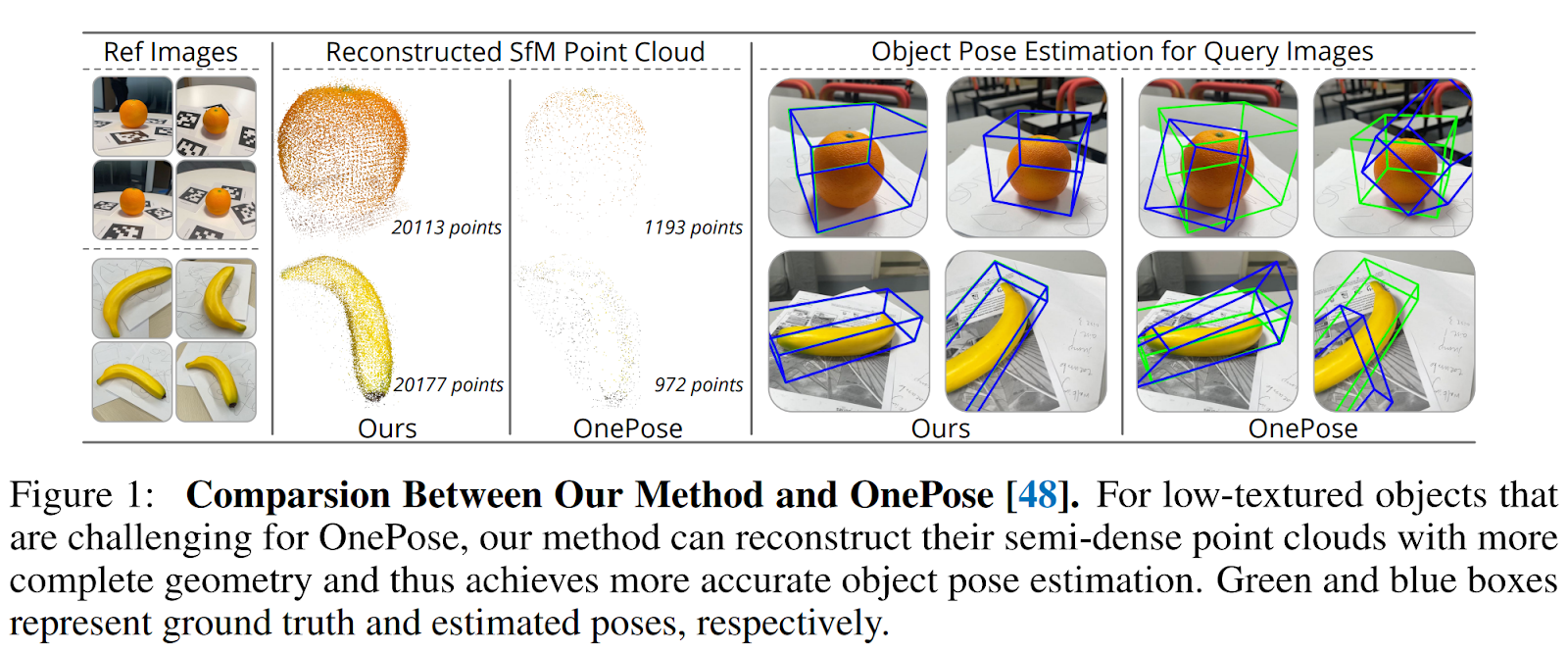
OnePose aims to simplify the process of object pose estimation for AR applications by eliminating the need for CAD models and category-specific training. Instead, it only requires a video sequence with annotated object poses. OnePose uses a feature-matching-based approach that reconstructs sparse object point clouds, establishes 2D-3D correspondences between keypoints, and estimates the object pose. However, this method struggles with low-textured objects as the complete point clouds are difficult to reconstruct with keypoint-based Structure from Motion (SfM), leading to pose estimation failures.
Based on the challenges mentioned above, OnePose++ has been developed. Its architecture is presented in the figure below.

OnePose++ exploits a keypoint-free feature-matching pipeline on top of OnePose to handle low-textured objects. First, it reconstructs the correct semi-dense object point cloud from reference photos. Then it solves the object pose for test images by establishing 2D-3D correspondences in a coarse-to-fine way.
An adapted version of the LoFTR method is exploited to achieve feature matching. It is a keypoint-free semi-dense technique that performs exceptionally well in matching image pairs and identifying correspondences in regions with low texture. It uses the centers of regular grids in the left image as keypoints and finds sub-pixel accurate matches in the right image through a coarse-to-fine process. However, the two-view-dependent nature of LoFTR leads to inconsistent keypoints and incomplete feature tracks. As a result, the keypoint-free feature matching method cannot be used directly in OnePose for object pose estimation.
To take advantage of both methods, a novel system has been developed to adapt the keypoint-free matching technique for one-shot object pose estimation. The authors propose a sparse-to-dense 2D-3D matching network that efficiently establishes accurate 2D-3D correspondences for pose estimation, taking full advantage of the architecture’s keypoint-free design. More specifically, to better adapt LoFTR for SfM, they design a coarse-to-fine scheme for accurate and complete semi-dense object reconstruction. The coarse-to-fine structure of LoFTR is then disassembled and integrated into the reconstruction pipeline. Additionally, self- and cross-attention are used to model long-range dependencies required for robust 2D-3D matching and pose estimation of complex real-world objects, which usually contain repetitive patterns or low-textured regions.
The figure below offers a comparison between the proposed approach and OnePose.
This was the summary of OnePose++, a novel AI keypoint-free one-shot object pose estimation framework without CAD models.
If you are interested or want to learn more about this framework, you can find a link to the paper and the project page.
Check out the Paper, Github, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.