A New AI Research Investigates The Benefits of Training Expert Language Models Over Instruction Tuning
Multitaskprompted fine-tuning (MT), also known as instruction-tuned Language Models (LMs), has recently demonstrated the ability to generalize to unseen tasks. It was once believed that increasing the total number of training tasks was the most important factor in improving MT LMs’ performance on unseen task generalization.
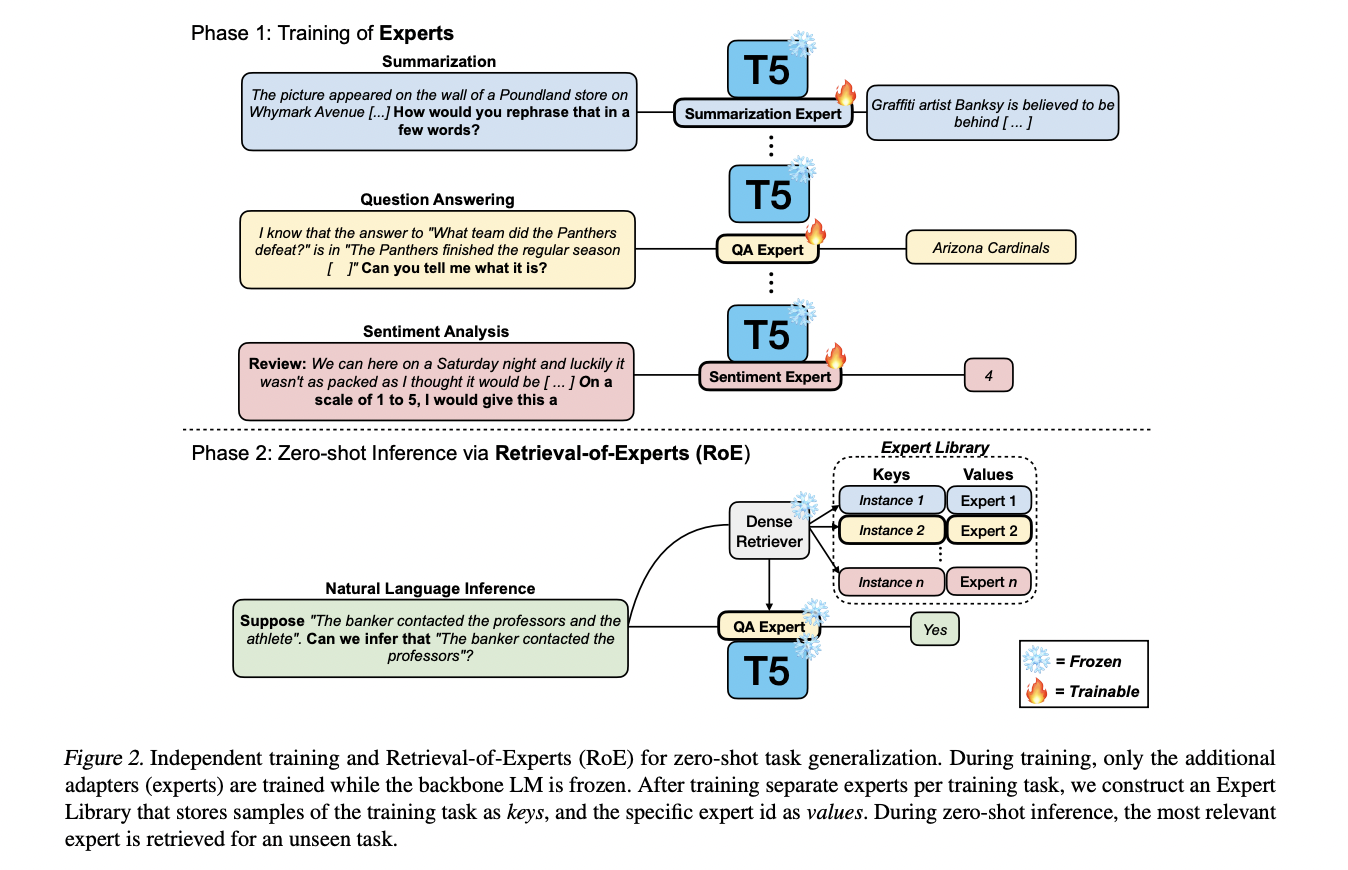
When it comes to unseen tasks, however, a new study by KAIST, LG AI Research, and the University of Illinois discovered that an LM trained on a single task could outperform an LM trained on 300+ tasks. For each unseen task, the researchers propose a straightforward technique of Retrieval-of-Experts (RoE) utilizing a commercially available dense retriever and training experts with T5-3B as the underlying LM.
Rather than fine-tuning the instructions across the board, the researchers specifically train expert LMs for each given training task (296) by freezing the underlying LM and updating adapters. They used the same experimental design (training and evaluation) as T0-3B, one of the most popular MT LM. Their findings show that 7 out of 296 experts outperform T0- 3B in terms of their ability to generalize to tasks with unknown mean accuracy. On 11 unknown datasets and 13 datasets from the BIG-Bench benchmark, using the highest performing expert outperforms T0-3B by a mean accuracy of 3.20% and 1.29%, respectively.
They further demonstrate that T0-3B-level performance may be achieved by employing a simple approach to retrieve applicable experts for each unseen job. These findings suggest that picking the right expert rather than naively using a single MT LM for all unseen tasks can be more efficient and effective, given the substantial room for improvement when retrieving the best-performing expert for each unseen task (+11.94% compared to T0-3B).
As mentioned in their paper, the proposed method offers the following three advantages over instruction tweaking:
- RoE is more resistant to the negative task transfer that often occurs during instruction tuning by showing that it outperforms T0-3B and T0-11B, respectively, in terms of mean accuracy on the 36 observed tasks by +10.40% and +7.70%, respectively.
- The proposed distributed method allows for non-stop learning of new tasks without impacting the performance of previously observed ones. However, LMs that are instructed to perform certain tasks will need to practice them repeatedly as they continue to learn.
- LMs tuned using instructions have a low capacity for instruction formulation. The distributed method allows for the composition of expert abilities by combining the efforts of multiple experts (summarization & translation).
The team hopes that their work will encourage the research community to dig deeper into the topic of dispersed and collaborative training of experts, which could have future benefits such as increased efficiency, privacy, and personalization.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.