Meet RangeAugment: Image Augmentation Technique That Works By Learning The Range of Magnitudes For Effective Computation
The performance of a deep neural network depends on the characteristics and quantity of the data provided for training purposes. Since there is a significant scarcity in the amount of data available, data augmentation is opted for. Data augmentation is a method of artificially increasing the volume of data by producing new data points from current data. It is a low-cost method for increasing the samples of training data. Data augmentation is carried out by adding minimal alterations to the data. This is done by using machine learning models to produce new data points in the latent space of original data to expand the training dataset.
An image is just a 2-dimensional array of numbers for a machine. The numbers represent pixel values, which can be tweaked in different ways to produce new images that are augmented. For automatic image data augmentation, methods like AutoAugment and RandAugment are currently being used. These methods help in diversifying the image training data. AutoAugment can be described as an automatic method to search for data augmentation policies in data. It puts together the issue of searching for the finest augmentation policy as a separate search problem and contains a search algorithm and a search space. Similarly, RandAugment is another automatic augmentation method that takes the input of two integers – N and M for creating several images where N is the number of random transformations and M is the magnitude of the transformations.
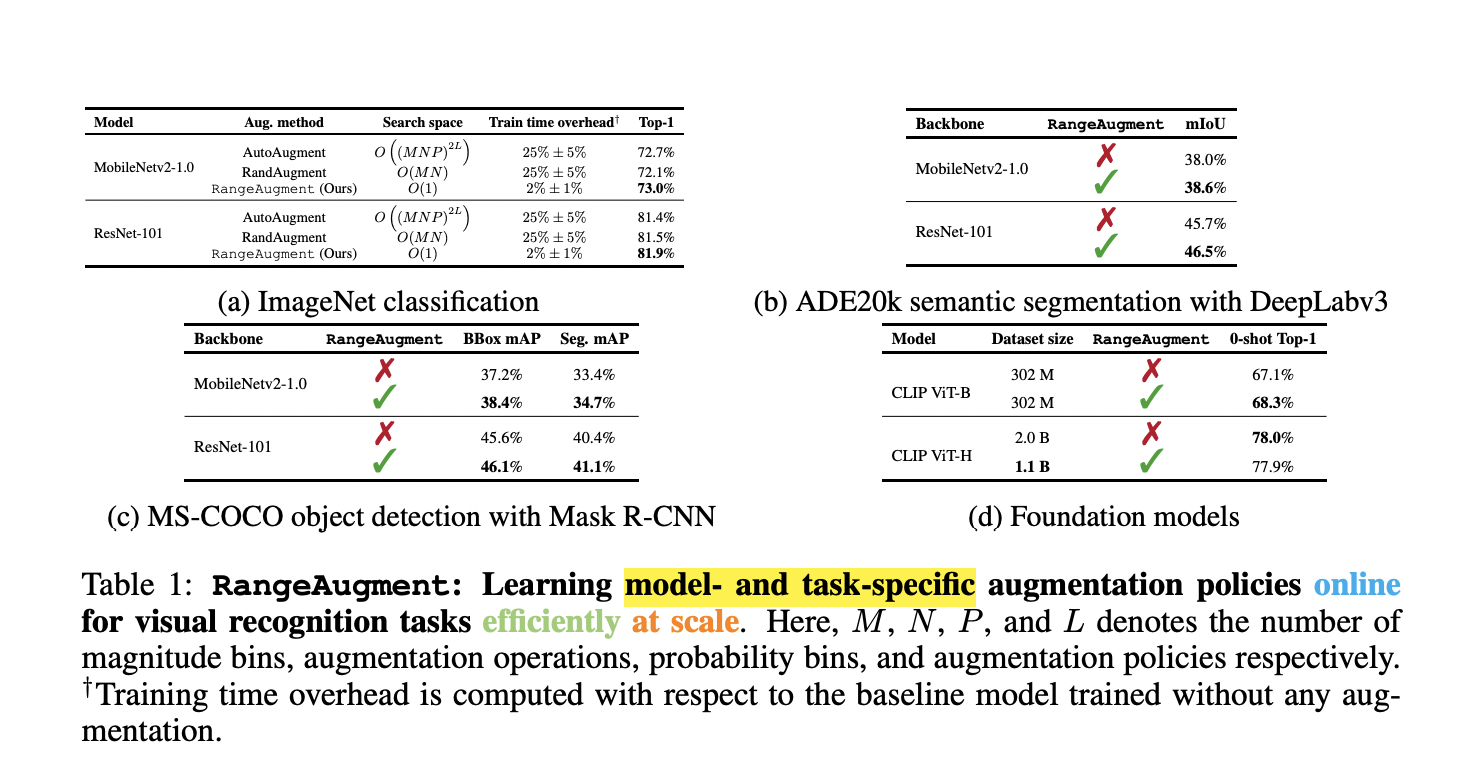
The current methods’ major disadvantage is that they use fixed and manually defined ranges of magnitudes for applying different augmentation operations. The latest method, called RangeAugment, has been developed to overcome this limitation. This approach learns the magnitude range of each augmentation operation instead of fixing the magnitude range for diversifying the training data. RangeAugment learns the range by using auxiliary loss on image similarity.
Augmentation operations like the application of contrast and brightness have a continuous range of magnitude. Thus, to manage the search computation, the old methods use fixed and defined ranges leading to obtaining sub-optimal policies. On the other hand, RangeAugment using image similarity metrics, learns the range of magnitudes for separate and composite augmentation functions. It consists of only one parameter for both searching and image similarity. This method evaluates the loss function by blending the empirical and augmentation loss after taking the resultant image similarity as the only input. The aim is to basically match the augmentation loss with the value of the target image similarity.
The team behind the research shows the comparison of RangeAugemnt with the traditional methods, and the study shows that RangeAugment attains the desired performance and efficiency with 4 to 5 times lesser augmentation operations when tested on the ImageNet dataset. Considering the policies, RangeAugment conveniently merges with any model and starts learning model-specific augmentation policies. It even shows great effectiveness in semantic segmentation, object detection, foundation models, and knowledge distillation.
Consequently, RangeAugment seems promising considering its noteworthy performance, and that too with only three basic operations – brightness, contrast, and additive Gaussian noise. It can undoubtedly be utilized for augmentation operations and overcome the current traditional ways’ limitations.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.