HuggingFace Publishes LoRA Scripts For Efficient Stable Diffusion Fine-Tuning
Microsoft unveiled Low-Rank Adaptation (LoRA) in 2021 as a cutting-edge method for optimizing massive language models (LLMs). LoRA is an effective adaptation technique that maintains model quality while significantly reducing the number of trainable parameters for downstream tasks with no increased inference time.
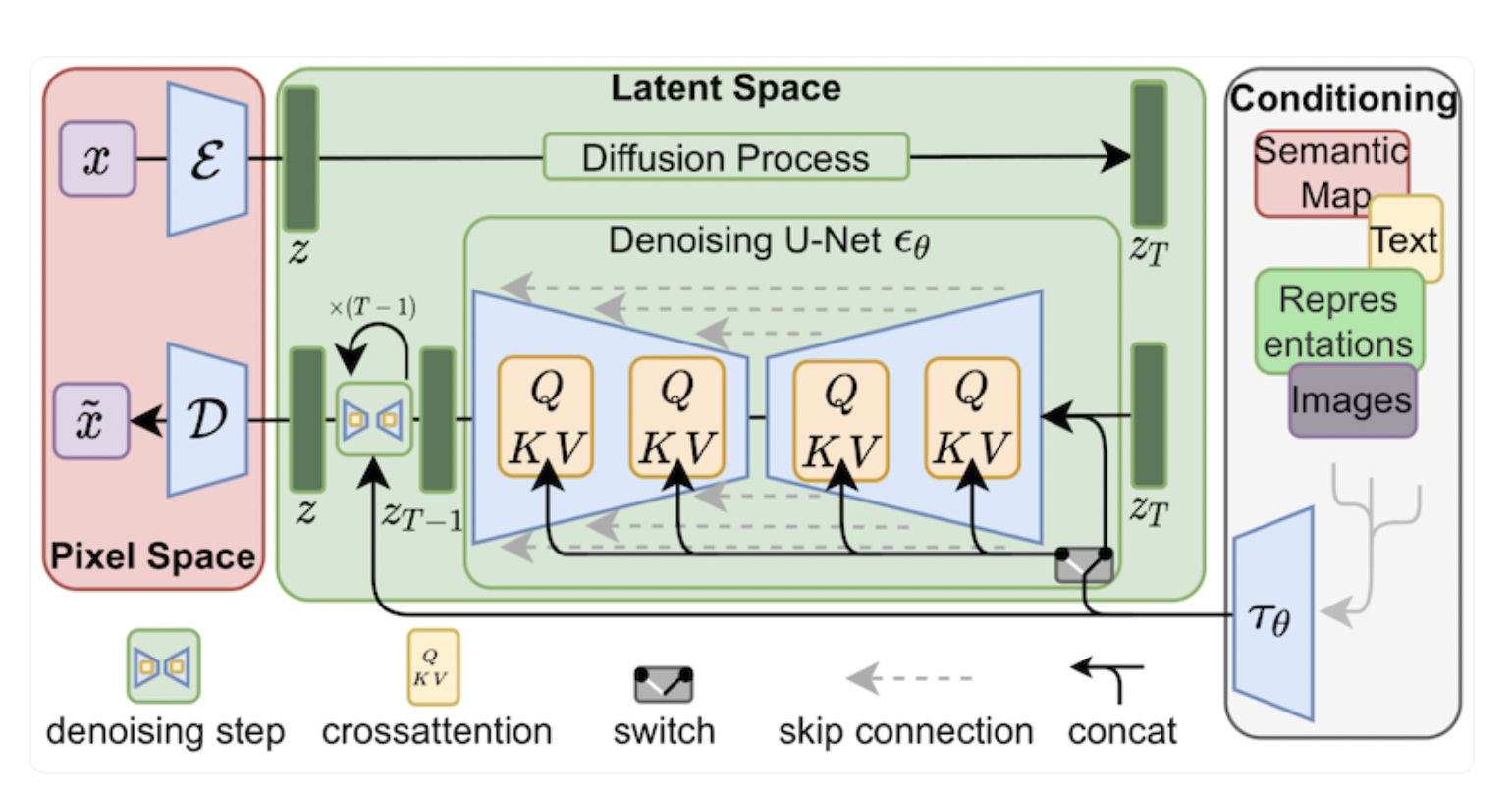
Although LoRA was first suggested for LLMs, it can also be used in other contexts. Scientists published a Stable diffusion paper in 2022. The researchers introduced latent diffusion models as a quick and easy technique to boost denoising diffusion models’ training and sampling effectiveness without sacrificing their quality. The trials could show superior outcomes to state-of-the-art techniques across a wide range of conditional image synthesis tasks without task-specific structures based on this model and the cross-attention conditioning mechanism. Although LDMs demand substantially less computing power than pixel-based methods, the sequential sampling procedure is still slower with LDMs than with GANs. Moreover, when great precision is required, the employment of LDMs may be in doubt.
Recently, scientists and a team from the machine learning platform Hugging Face worked together to develop a universal strategy that enables users to integrate LoRA in diffusion models like Stable Diffusion using Dreambooth and complete fine-tuning techniques.
LoRA fine-tuning
Stable Diffusion’s full model fine-tuning used to be time-consuming and challenging, which is partly why faster, more straightforward techniques like Dreambooth or Textual Inversion have gained popularity. LoRA makes it significantly simpler to fine-tune a model on a unique dataset. The LoRA fine-tuning script that Diffusers now offers can operate with as little as 11 GB of GPU RAM without using cheats like 8-bit optimizers. With LoRA, you may train orders of magnitude with fewer weights than the initial model size and achieve outstanding results. The researchers created an inference procedure that enables loading the extra weights on top of the consequences from the original Stable Diffusion model.
Dreamboothing with LoRA
One can “teach” new ideas to a Stable Diffusion model using Dreambooth. Dreambooth and LoRA are compatible, and the procedure is similar to fine-tuning with a few benefits:
1. Training is more rapid.
2. Only a few pictures of the subject we wish to train are required (5 or 10 are usually enough).
3. If one wishes to increase the text encoder’s subject-specific fidelity, one can adjust it.
Use this diffuser script to train Dreambooth to use LoRA.
Easy fine-tuning has long been a goal. Textual inversion is another well-liked technique that aims to introduce new ideas to a trained Stable Diffusion Model in addition to Dreambooth. The fact that training weights are portable and straightforward to transmit is one of the key benefits of utilizing text inversion. They can be used for a single subject (or a small number of issues), but LoRA can be used for general-purpose fine-tuning, which allows it to be customized for different domains or datasets.
A technique called pivotal tuning aims to combine LoRA and textual inversion. Users must first educate the model using Textual Inversion approaches to represent a new concept. Then, to connect the best of both worlds, train the token embedding using LoRA. The team is expecting to explore pivotal tuning with LoRA in the future.
Check out the Source Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.