Meet LAMPP: A New AI Approach From MIT To Integrate Background Knowledge From Language Into Decision-Making Problems By Extracting Probabilistic Priors From Language Models
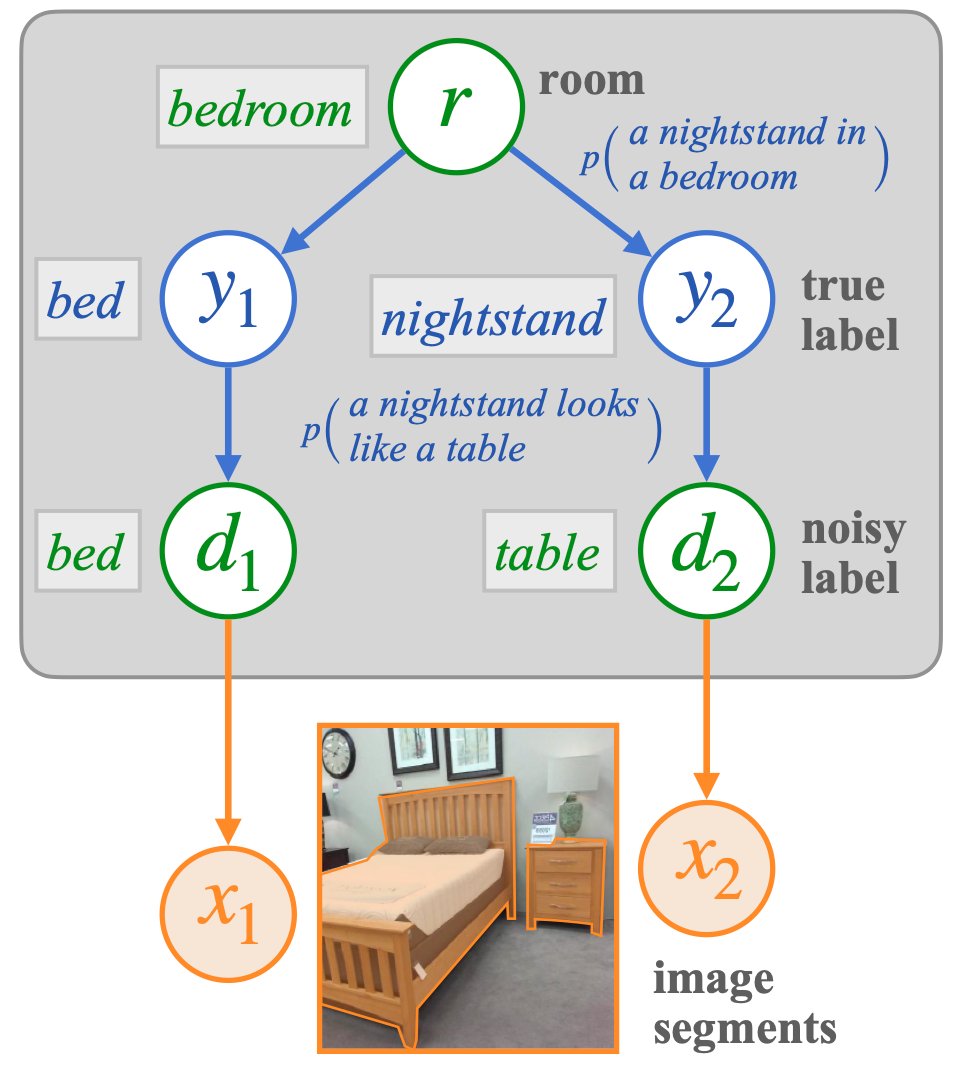
Common sense priors are essential to make decisions under uncertainty in real-world settings. Let’s say they want to give the scenario in Fig. 1 some labels. As a few key elements are recognized, it becomes evident that the image shows a restroom. This assists in resolving some of the labels for certain more difficult objects, such as the shower curtain in the scene rather than the window curtain and the mirror instead of the portrait on the wall. In addition to visual tasks, prior knowledge of expected item or event co-occurrences is crucial for navigating new environments and comprehending the actions of other agents. Moreover, such expectations are essential to object categorization and reading comprehension.

Unlike robot demos or segmented pictures, vast text corpora are easily accessible and include practically all aspects of the human experience. Current machine learning models use task-specific datasets to learn about the previous distribution of labels and judgments for the majority of problem domains. When training data is skewed or sparse, this can lead to systematic mistakes, particularly on uncommon or out-of-distribution inputs. How might they provide models with broader, more adaptable past knowledge? They suggest using learned distributions over natural language strings known as language models as task-general probabilistic priors.
LMs have been employed as sources of prior knowledge for tasks ranging from common-sense question answering to modeling scripts and tales to synthesizing probabilistic algorithms in language processing and other text production activities. They frequently give higher diversity and fidelity than small, task-specific datasets for encoding much of this information, such as the fact that plates are found in kitchens and dining rooms and that breaking eggs comes before whisking them. It has also been proposed that such language monitoring contributes to common-sense human knowledge in areas that are challenging to learn from first-hand experience.
Model chaining techniques, which encode the output of perceptual systems as natural language strings that encourage LMs to produce labels or plans immediately, have also been used to address difficulties with grounded language understanding. Instead, they concentrate on LMs in this study as a source of background probabilistic information that may be included with current domain models. LMs naturally pair with structured probabilistic modeling frameworks because they can be combined with domain-specific generative models or likelihood functions to integrate “top-down” background knowledge with “bottom-up” task-specific predictors by using them to place prior distributions over labels, decisions, or model parameters.
This kind of modeling is known as LAMPP. This method offers a sound technique to combine linguistic supervision with structured uncertainty about nonlinguistic factors, allowing one to benefit from LMs’ expertise even in challenging jobs where LMs have trouble concluding. LAMPP is adaptable and can be used to solve many different kinds of issues. Semantic image segmentation, robot navigation, and video action segmentation are examples of tasks they offer in three case studies. LAMPP frequently enhances performance on uncommon, out-of-distribution, and structurally new inputs and, on rare occasions, even enhances precision on samples inside the training distribution of the domain model. These results show that language is a useful source of background knowledge for general decision-making and that uncertainty in this background knowledge can be effectively integrated with uncertainty in nonlinguistic problem domains.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.