World Bank Researchers Open Source REaLTabFormer: A Tabular and Relational Synthetic Data Generation Model
The most prevalent type of data is tabular data. This form contains many datasets from surveys, censuses, and administrative sources. These datasets could include private information that shouldn’t be made public. Even after using statistical disclosure methods, they might still be the target of hostile assaults because their low utility results from their constrained dispersion. Differential privacy techniques, homomorphic encryption strategies, or federated machine learning may be used to implement, enabling researchers access to insights from sensitive data. A better option is synthetic tabular data, which adds greater value, particularly in granular and segmentation analysis, and has statistical features similar to real data.
The generative models used to create these synthetic data must ensure that “data copying” won’t take place to comply with data privacy regulations. Tabular data is formally a group of observations (rows) oi that may or may not be independent. oi = [xi1, xi2,…, xij,…, xin], where j denotes the jth column, defines a single observation in a data table with n columns. Non-relational tabular data are tabular data that contain observations that are unrelated to one another. Relational tabular data are tabular data that have observations that are connected. A relational dataset consists of at least one pair of tabular data files connected by a single identifier and containing a one-to-many mapping of observations between the parent table and the child table, respectively.
Relational tabular databases simulate logical data partitioning and avoid duplicating observations between parent and child tables. A parent table is non-relational tabular data in the context of a relational dataset, whereas the child table is relational tabular data. Despite its widespread use, only a small amount of effort has been made to creating artificial relational datasets. This could be because simulating the intricate interactions between and within tables takes a lot of work. In recent years, there has been substantial advancement in creating synthetic data. Synthetic picture-generating models like DALLE and, most recently, ChatGPT have made generative models widely used.
While generative models for text and graphics are ubiquitous, there are few models for creating artificial tabular data, despite the wide range of potential uses. To solve data privacy concerns and sparsity, synthetic tabular data might be helpful. They can assist in facilitating researchers’ access to private information, bridging data availability gaps for agent-based simulations, artificial control approaches, and counterfactual research. The creation of machine learning prediction models can add more value to tabular data.
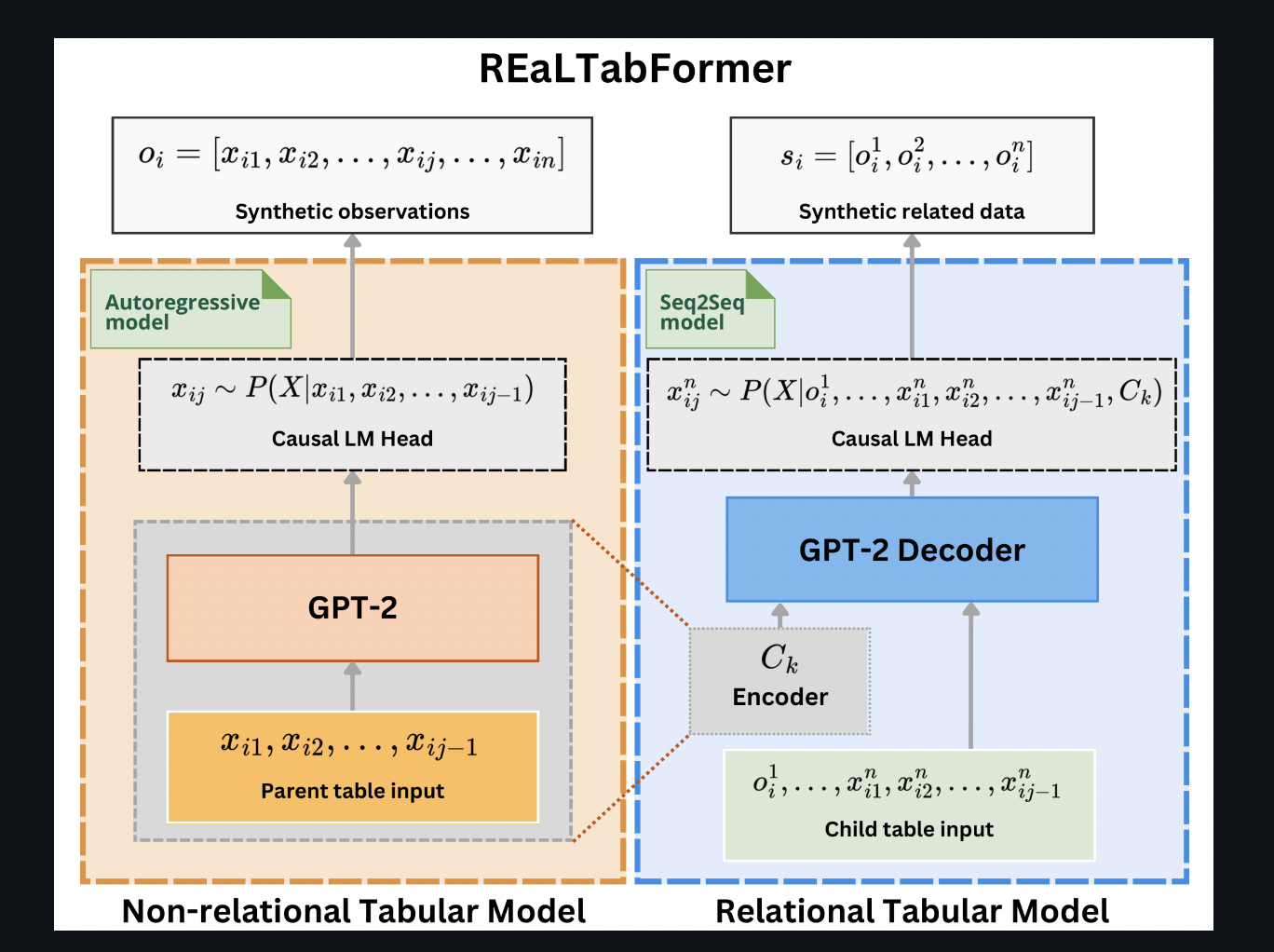
Deep learning models’ synthetic data has demonstrated success in predictive modeling tasks. These prediction models can infer variables of relevance from data that would otherwise be costly to obtain or correspond to certain performance indicators that might help businesses make decisions. This increases the usefulness of real-world data that could otherwise go underutilized out of concern about privacy. The REalTabFormer, a transformer-based system for producing relational datasets and non-relational tabular data, is introduced in this study.
It contributes in the following ways:
- Unified structure: For modeling and creating parent tables, the RealTabFormer models non-relational tabular data using an autoregressive (GPT-2) transformer. To contextualize the input and produce arbitrary-length data-matching to observations in a child table, the encoder network employs the pre-trained network weights for the parent table. After that, it models the data using the sequence-to-sequence (Seq2Seq) framework and creates observations for the child table.
- Techniques for privacy-preserving instruction: In addition to producing accurate data, synthetic data generation models must have controls to stop the model from “memorizing” and copying observations from training data during sampling. To detect overfitting during training reliably, they employ statistical bootstrapping, the distance to the closest record (DCR), and a data-copying metric. They incorporate target masking for regularisation to decrease the possibility that the model would reproduce training data.
- Open source models: The REaLTabFormer models are made available as an open-source Python module. One can use pip to install the package.
- Comprehensive assessment They test the effectiveness of their models using various real-world datasets. They evaluate the effectiveness of REaLTabFormer in producing relational and non-relational tabular datasets using open-sourced state-of-the-art models as baselines.
Their tests show that the REaLTabFormer model outperforms the state-of-the-art in machine learning tasks for big datasets for non-relational tabular data. They further offer that the REaLTabFormer’s synthesis observations for the child table better capture relational statistics than the baseline models. The codebase can be found on GitHub.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.