CMU Researchers Propose DocPrompting: A Natural Language To Code Generation Approach By Retrieving Code Documentation
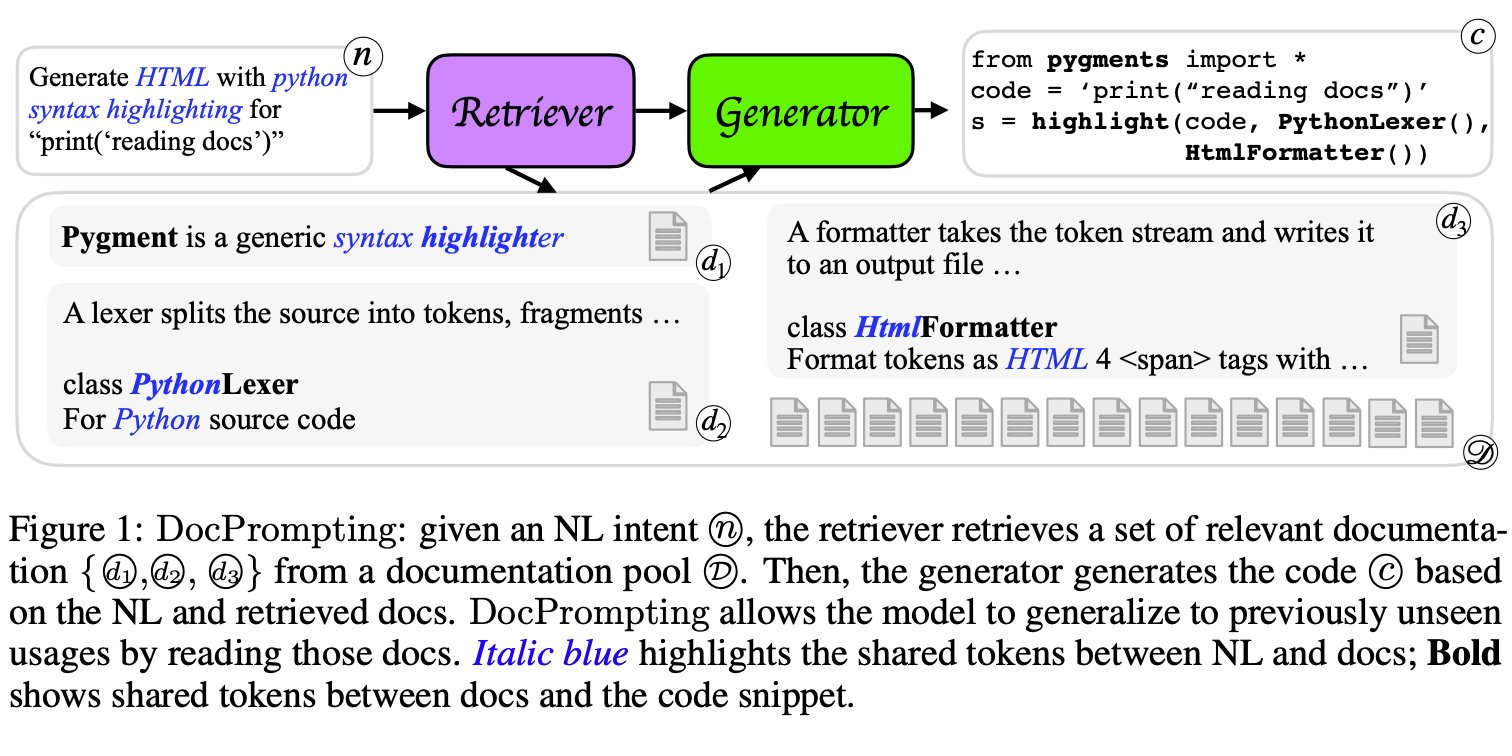
The source code libraries available to the public are always evolving and expanding. Thus, it is hard for code models to stay up-to-date with all accessible APIs by only training these models on existing code repositories. DocPrompting is a new way to generate code from natural language that explicitly uses documentation by requesting the appropriate documentation components in response to an NL intent.
The flexibility of DocPrompting means that it may be used with any programming language and is independent of the specific neural model being used. To help developers, docprompting may fetch documentation sections and write code based on those sections. By scanning the documentation, a code LM (like Codex or CodeT5) may create calls to libraries and functions it has never encountered in its training data.
How it works
To begin, a document retriever will access the documentation pool for the code being retrieved and, using the NL intent, pull back any applicable documentation. A code generator then inputs the documentation into a prompt that produces the code. New contents (such as documentation for freshly released libraries) may be added to the external data store documentation pool without re-training any part of the model. This enables DocPrompting to use newly added documentation and produce code that uses previously invisible or unused libraries and functions. The DocPrompting framework is generic and may be used with any programming language or underlying base architecture.
Study and analysis by researchers
A group of researchers has provided a set of freshly picked benchmarks to test future retrieval-based code generation models. Both a shell scripting work in which researchers had to write sophisticated shell commands based on intent and a Python programming assignment in which they had to generate responses in Python for NL queries were used to assess DocPrompting. The researchers present a freshly selected benchmark tldr before discussing the popular CoNaLa benchmark’s recent resplit. Researchers supply a global documentation pool D for each benchmark to train the retriever, including examples and oracle documents Dn.
According to the study’s authors, models using DocPrompting regularly beat their NL intents-only code-generating counterparts. CoNaLa’s execution-based assessment sees a 2.85% increase in pass@1 (52% relative gain) when using DocPrompting on top of already powerful base models like CodeT5.
DocPrompting consistently outperforms the state-of-the-art methods on the new NL->Bash “tldr” dataset. In the case of CodeT5 and GPT-Neo1.3B, for instance, it can increase the percentage of exact matches by as much as 6.9%.
According to researchers, one of the main reasons is that documentation comprises both natural language descriptions and function signatures, simplifying the mapping between NL intentions and code. The n-gram overlap between NL intents and the code snippets that corresponded to them was determined by the researchers (NLcode), and the overlap between NL intents and the top 10 documents that were retrieved was determined by the researchers ((NL+docs)code). The amount of shared information between n-grams grows dramatically when documentation is included. In other words, the retrieval of documentation aids in code accuracy generation since it helps to close the gap between “intent terminology” and “code terminology.”
In Conclusion, DocPrompting is a straightforward method for generating code by getting the appropriate documentation. DocPrompting reliably enhances NLcode models across several strong base models, two tasks, and two programming languages. Using the well-known Python CoNaLa benchmark, DocPrompting boosts strong base models like CodeT5 by 2.85% in pass@1 (52% relative gain) in execution-based assessment; on the novel Bash dataset tldr, DocPrompting boosts CodeT5 and GPT-Neo-1.3B by up to 6.9% exact match and Codex by 6.78 charBLEU score. These findings pave the way for a hopeful future for NLcode generation. More improvements are possible through cooperative training of the retriever and the generator, which should prevent cascade mistakes, and by the more intelligent encoding of the organized nature of big texts.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.