Meta AI Unveils LLaMA: A Series of Open-Source Language Models Ranging from 7B to 65B Parameters
Large language models (LLMs) have taken the tech industry by storm in the last few years. These language models, trained on vast amounts of data, can perform a variety of tasks, ranging from fundamental ones like summarising text and writing poetry to more challenging ones like generating AI art prompts and even predicting protein structure. OpenAI’s ChatGPT is currently among the greatest and most well-known examples of such LLMs. Using Generative Pre-trained Transformer 3, ChatGPT is a dialogue-based AI chat interface that can converse with people, write code, answer questions, and even solve challenging mathematical equations. Even other tech giants, like Google and Microsoft, have yet to leave any stone unturned in releasing their language models like BARD and Bing.
It is a widely held belief among academics that adding more parameters improves performance when training LLMs with almost a billion parameters. Recent research demonstrates that for a given training compute budget, smaller models trained on more data, as opposed to the largest models, produce the best performance. Inference budget is another key parameter crucial for obtaining a desired degree of performance. Although it might be cheaper to train a large model to reach a certain level of performance, a smaller one trained longer will ultimately be cheaper at inference. In some cases, the ideal model is not the one that trains the quickest but the one that makes inferences the fastest.
To make its mark in the competitive generative AI model race, Facebook’s parent company, Meta, introduces its line of AI language models under the name LLaMA. This work aims to develop several language models that perform optimally at different inference budgets, inspiring the AI community to conduct research on creating more responsible language models. Previously, access to such language models was expensive and limited because they frequently required servers to run. But with LLaMA, Meta aims to solve exactly that for researchers. Trained on only publicly available data, the organization claims that LLaMA can outperform larger AI models currently in use, including OpenAI’s older GPT-3 model. The company has done brilliant work in exhibiting the fact that it is possible to train state-of-the-art models without resorting to proprietary and inaccessible datasets.
Meta has open-sourced LLaMA with the hope that the models will help democratize the access and study of LLMs since they can be run on a single GPU. This will enable researchers to comprehend LLMs more thoroughly and reduce other known problems, including bias, toxicity, and the ability to spread misinformation. Another intriguing aspect of this collection of language models is that, in contrast to other language models like ChatGPT and Bing, LLaMA is exclusively meant for research purposes and is distributed under a “noncommercial license.” Access is currently available to a variety of academic researchers, governments, universities, and other academic institutions.
LLaMA can produce human-like dialogues from a text input prompt like other AI-powered chatbots. Four different models are available, with parameters ranging from 7 billion to 65 billion. Compared to OpenAI’s earlier GPT-3 model, it is almost ten times smaller. Only publicly accessible data from various domains that had already been used to train other LLMs were used to train the series of foundation models. This made it easier for the models to be open-sourced. English CCNet, C4, GitHub, Wikipedia, Books, ArXiv, and Stack Exchange are some data sources used to train LLaMA. The transformer design serves as the foundation for LLaMA, with further advancements being presented over the course of the past few years. Researchers at Meta trained large transformers on a vast amount of textual data using a standard optimizer.
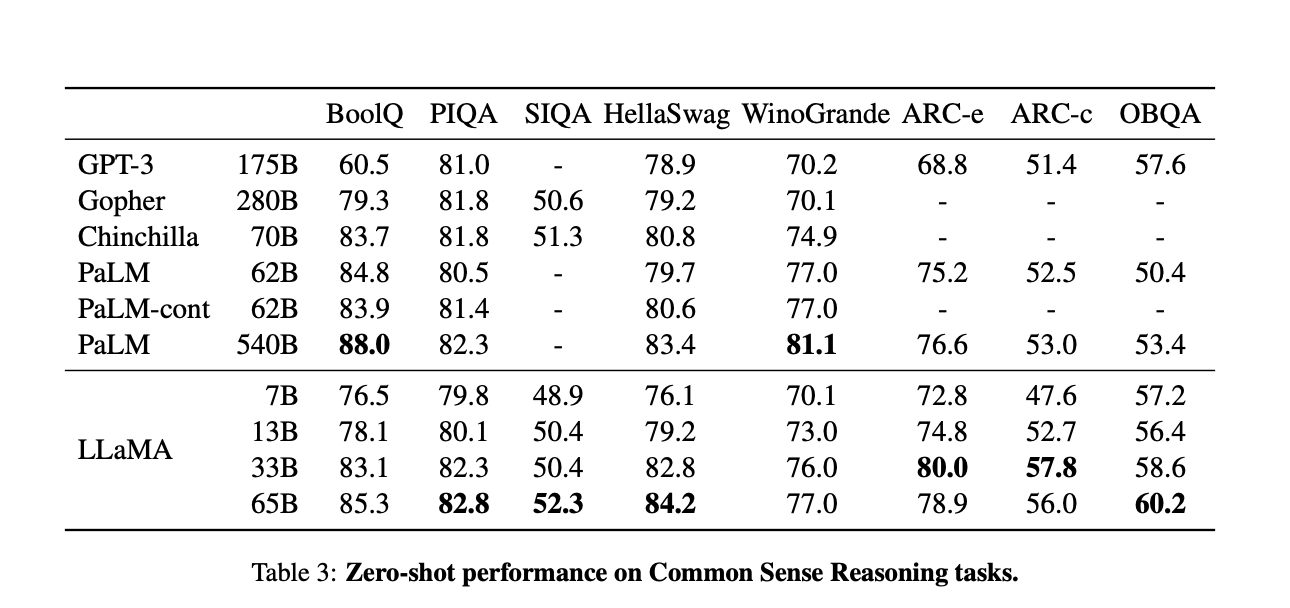
One trillion tokens were used in the training of the smallest model, LLaMA-7B. On the other hand, models with larger parameters like LLaMA-33B and LLaMA-65B have been trained on 1.4 trillion tokens. The researchers assessed their series of foundation models using a variety of benchmarks, including BoolQ, WinoGrande, OpenBookQA, NaturalQuestions, RealToxicityPrompts, WinoGender, and others. The researchers’ two most important findings are that the LLaMA-13B model, the second-smallest version, outperforms the older GPT-3 model on most benchmarks, and the LLaMA-65B model is competitive with some of the best models currently available, including DeepMind’s Chinchilla-70B and Google’s PaLM-540B models.
In a nutshell, Meta released a series of novel state-of-the-art AI LLMs called LLaMA for researchers hoping to advance research on LLMs and improve their robustness. The researchers have found that fine-tuning these models on instructions leads to positive outcomes when it comes to future work. The researchers will carry out further investigation on this. In order to improve performance, Meta also seeks to deploy larger models that have been trained on more substantial corpora.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.