A New Deep Reinforcement Learning (DRL) Framework can React to Attackers in a Simulated Environment and Block 95% of Cyberattacks Before They Escalate
Cybersecurity defenders must dynamically adapt their techniques and tactics as technology develops and the level of complexity in a system surges. As machine learning (ML) and artificial intelligence (AI) research has advanced over the past ten years, so have the use cases for these technologies in various cybersecurity-related domains. A few functionalities in most existing security applications are backed by strong machine-learning algorithms trained on substantial datasets. One such instance is the early 2010s integration of ML algorithms in email security gateways.
When it comes to the real-world scenario, creating autonomous cyber system defense strategies and action recommendations is rather a difficult undertaking. This is because providing decision support for such cyber system defense mechanisms requires both the incorporation of dynamics between attackers and defenders and the dynamical characterization of uncertainty in the system state. Moreover, cyber defenders often face a variety of resource limitations, including those related to cost, labor, and time. Even with AI, developing a system capable of proactive defense remains an ideological goal.
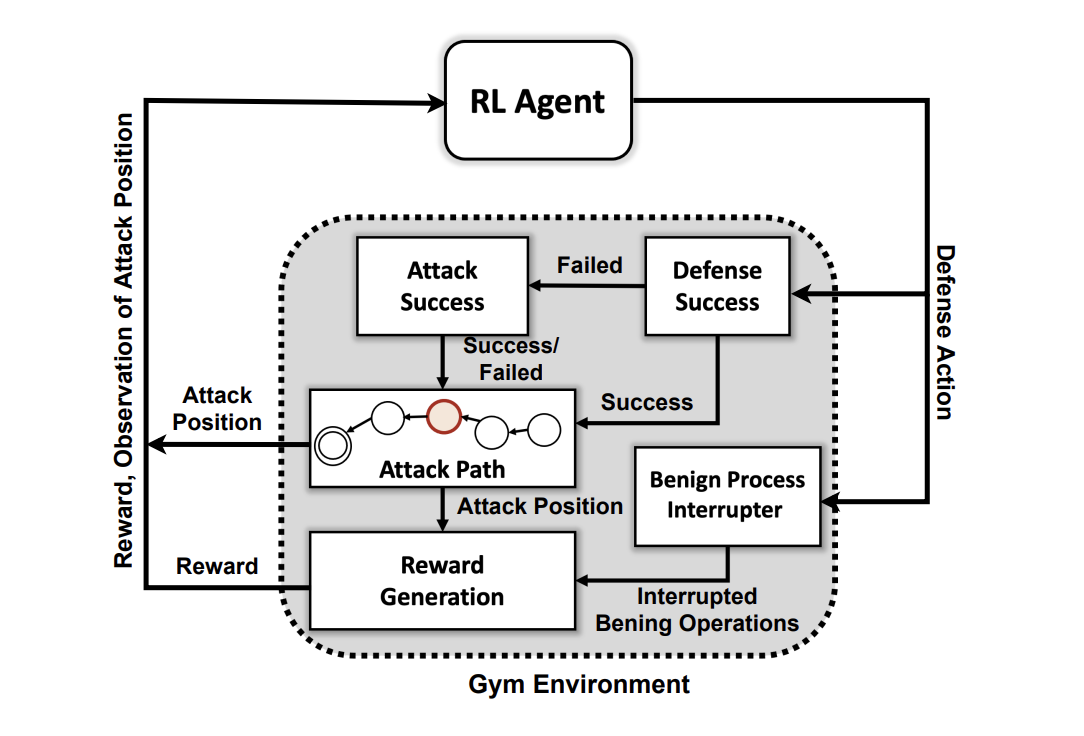
In an effort to offer a solution to this problem statement, researchers from the Department of Energy’s Pacific Northwest National Laboratory (PNNL) have created a novel AI system based on deep reinforcement learning (DRL) that is capable of responding to attackers in a simulated environment and can stop 95% of cyberattacks before they escalate. The researchers created a custom simulation environment demonstrating a multi-stage digital conflict between attackers and defenders in a network. Then, they trained four DRL neural networks using reinforcement learning principles, such as maximizing rewards based on avoiding compromises and reducing network disruption. The team’s work has also been presented at the Association for the Advancement of Artificial Intelligence in Washington, DC, where it received a great deal of praise.
The team’s philosophy in developing such a system was first to show that successfully training such a DRL architecture is possible. Before diving into sophisticated structures, they wanted to demonstrate useful evaluation metrics. The first thing the researchers did was create an abstract simulation environment using the Open AI Gym toolkit. The next stage was to use this environment to develop attacker entities that displayed skill and persistence levels based on a subset of 15 approaches and seven tactics from the MITRE ATT&CK framework. The attackers’ objective is to go through the seven attack chain steps— from the initial access and reconnaissance phase to other attack phases until they reach their ultimate goal, which is the impact and exfiltration phase.
It’s vital to remember that the team had no intention of developing a model for blocking an enemy before they could launch an attack inside the environment. Rather, they assume that the system has already been compromised. The researchers then used reinforcement learning to train four neural networks. The researchers stated that it is conceivable to train such a model without utilizing reinforcement learning, but it would take a long time to develop a good mechanism. On the other hand, deep reinforcement learning makes very efficient use of this enormous search space by imitating some aspects of human behavior.
Researchers’ efforts to demonstrate that AI systems can be successfully trained on a simulated attack environment have shown that an AI model is capable of defensive reactions to attacks in real-time. To rigorously assess the performance of four model-free DRL algorithms against actual, multi-stage assault sequences, the researchers ran several experiments. Their research showed that DRL algorithms might be trained under multi-stage assault profiles with varying skill and persistence levels, producing effective defense results in simulated environments.
Check out the Paper and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.