Meet RECITE: A New Paradigm To Help Large Language Models (LLMs) Generate More Accurate Factual Knowledge Without Retrieving From An External Corpus
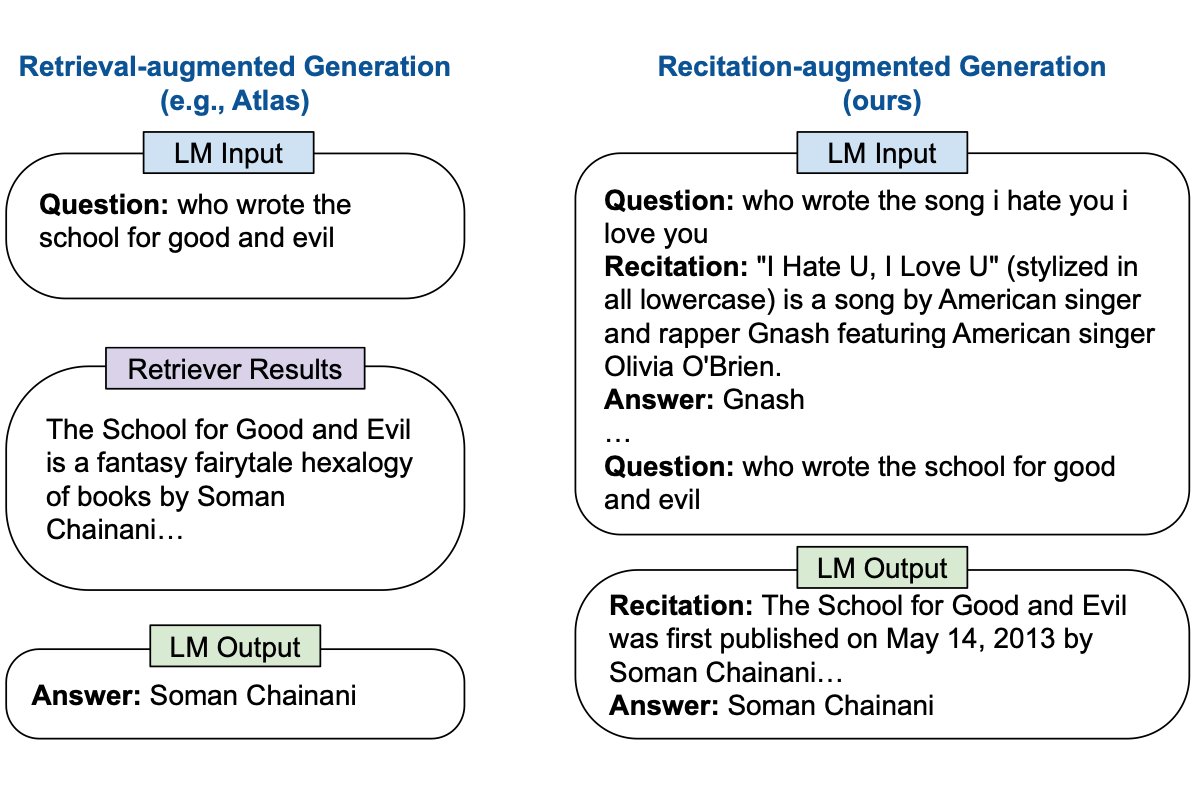
In-context learning is a natural language paradigm that demonstrates the ability of pre-trained models to pick up new behaviors using only a small number of example prompts as input. Most recent research indicates that large language models (LLMs), such as GPT-3 and the newest craze, ChatGPT, can achieve outstanding performance when it comes to in-context few-shot learning on knowledge-intensive NLP tasks. For instance, LLMs have successfully shown their ability to respond to arbitrary factual queries regarding open-domain question answering, which essentially refers to generating responses to arbitrary context-free questions. Researchers have found that retrieval augmentation can be very beneficial for knowledge-intensive activities, which can further enhance the performance of LLMs. LLMs perform retrieval augmentation by extracting relevant documents from an external corpus.
Yet, over the past few years, researchers have wondered whether LLMs are capable of producing factual data that is more accurate without the aid of retrieval augmented generation. A team of researchers at Google Brain and CMU conducted some ground-breaking research work that illustrates exactly this! The team has put forth a brand-new approach called RECITation-augmented gEneration (RECITE), in which, for a given input, RECITE first uses sampling to recall one or more pertinent passages from the LLMs’ own memories before generating the final results. RECITE’s innovative recite-and-answer approach has demonstrated state-of-the-art performance in a variety of knowledge-intensive NLP tasks, including closed-book question answering (CBQA). The team’s research paper was also published at the prestigious ICLR 2023 conference.
The paradigm presented by Google Brain researchers is based on dividing original knowledge-intensive work into two subtasks: task execution and knowledge recitation. Recitation can be considered as an intermediate knowledge retrieval process, whereas task execution is the final phase wherein the final outputs are generated. The researchers noticed that while few-shot prompting can assist LLMs in performing specific NLP tasks, these tasks are typically not in a similar format to the original causal language modeling pre-training objective. This frequently makes it difficult for LLMs to recall information accurately from memory. As a result, this observation gave the researchers the idea to use an additional knowledge-recitation step. The knowledge-recitation stage was included to simulate the language modeling pre-training assignment, eventually improving LLMs’ ability to generate factual information.
The researchers’ ultimate objective was to simulate a human’s capacity to recall pertinent factoids before responding to knowledge-intensive queries. The team tested and fine-tuned their recite-and-answer scheme for few-shot closed-book question answering (CBQA) tasks. These tasks consist of two parts: the evidence recitation module, which requires reading pertinent passages, and the question-answer module, which asks you to come up with answers based on the evidence you just recited. The researchers presented a prompt-based learning-to-recite system utilizing the LLM’s capacity for in-context learning. Paired examples of questions and recited evidence were given as input to the LLMs to learn such instances in an in-context manner to recite the question.
The researchers ran many tests on four pre-trained models (PaLM, UL2, OPT, and Codex) and three CBQA tasks (Natural Questions, TriviaQA, and HotpotQA) to assess their RECITE paradigm. It was found that using different pre-trained language models with the suggested recite-and-answer technique, CBQA performance on the Natural Questions and TriviaQA datasets could be greatly improved. The researchers also made an interesting observation that while performance increases on NQ were more uniform across various language models, improvements from recite-and-answer on TriviaQA were more significant on smaller language models. The likely cause of this might be that Trivia-style questions frequently include more contextual information, which lessens the impact of recitation for powerful LLMs like PaLM.
Even if the method developed by Google Brain Researchers is impressive, more work needs to be done. In order to update time-sensitive information, a pure LLM-based solution currently requires training or fine-tuning the LLMs on the new corpus, which can be quite computationally expensive. The researchers want to work on this front in the near future. Moreover, according to their future plans, the researchers also plan on validating the effectiveness of recitation-augmented generation for additional knowledge-intensive NLP tasks in the closed-book context, like fact-checking.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.