Deep Learning for Deep Objects: ZoeDepth is an AI Model for Multi-Domain Depth Estimation
Have you ever encountered illusions where a kid in the image looks taller and bigger than an adult? Ames room illusion is a famous one that involves a room that is shaped like a trapezoid, with one corner of the room closer to the viewer than the other corner. When you look at it from a certain point, objects in the room look normal, but as you move to a different position, everything changes in size and shape, and it can be tricky to understand what is close to you and what is not.
Though, this is a problem for us humans. Normally, when we look at a scene, we estimate the depth of objects pretty accurately if there are no illusion tricks. Computers, on the other hand, are not that successful at depth estimation as it is still a fundamental problem in computer vision.
Depth Estimation is the process of determining the distance between the camera and the objects in the scene. Depth estimation algorithms take an image or a sequence of images as input and output a corresponding depth map or 3D representation of the scene. This is an important task as we need to understand the depth of the scene in numerous applications like robotics, autonomous vehicles, virtual reality, augmented reality, etc. For example, if you want to have a safe autonomous driving car, understanding the distance to the car in front of you is crucial to adjust the driving speed.
There are two branches of depth estimation algorithms, metric depth estimation (MDE), where the goal is to estimate the absolute distance, and relative depth estimation (RDE), where the goal is to estimate the relative distance between the objects in the scene.
MDE models are useful for mapping, planning, navigation, object recognition, 3D reconstruction, and image editing. However, the performance of MDE models can deteriorate when training a single model across multiple datasets, especially if the images have large differences in depth scale (e.g., indoor and outdoor images). As a result, current MDE models often overfit specific datasets and do not generalize well to other datasets.
RDE models, on the other hand, use disparity as a means of supervision. The depth predictions in RDE are only consistent relative to each other across image frames, and the scale factor is unknown. This allows RDE methods to be trained on a diverse set of scenes and datasets, even including 3D movies, which can help improve model generalizability across domains. However, the trade-off is that the predicted depth in RDE does not have a metric meaning, which limits its applications.
What would happen if we combined these two approaches? We can have a depth estimation model that can generalize well to different domains while still maintaining an accurate metric scale. This is exactly what ZoeDepth has achieved.
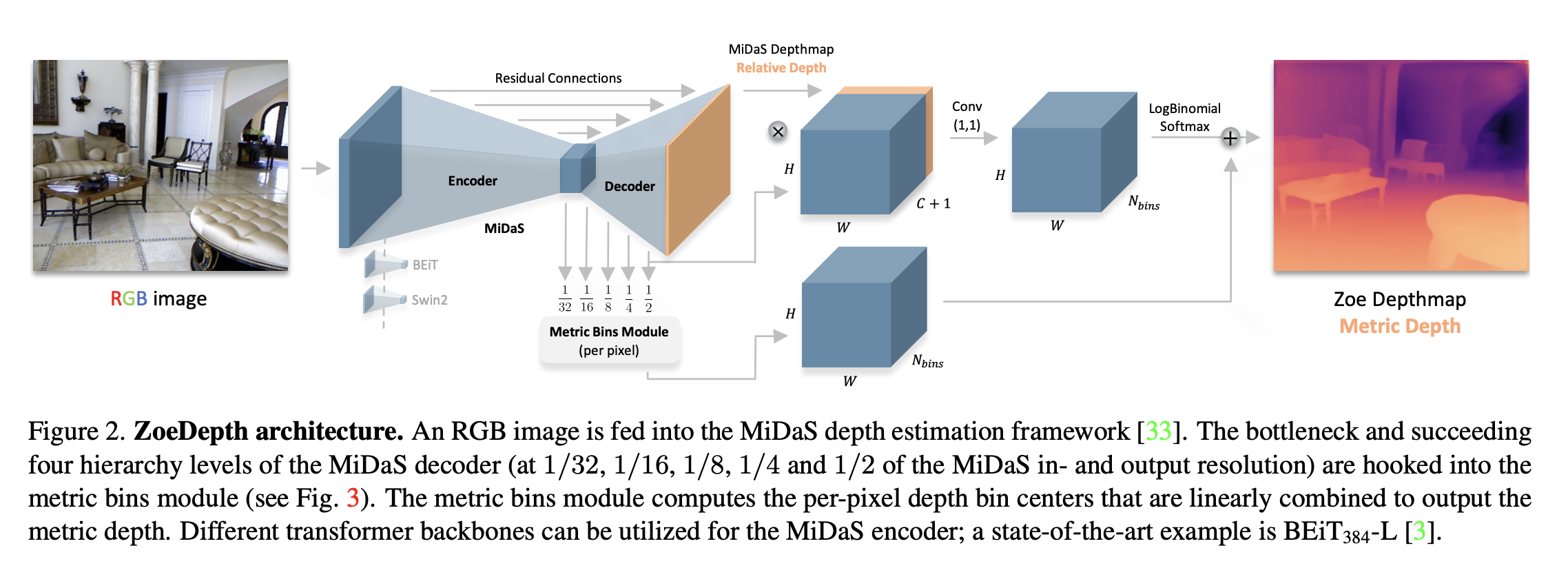
ZoeDepth is a two-stage framework that combines both MDE and RDE approaches. The first stage consists of an encoder-decoder structure that is trained to estimate relative depths. This model is trained on a large variety of datasets which improves the generalization. The second stage adds components responsible for estimating metric depth are added as an additional head.
The metric head design used in this approach is based on a method called the metric bins module, which estimates a set of depth values for each pixel rather than a single depth value. This allows the model to capture a range of possible depth values for each pixel, which can help improve its accuracy and robustness. This enables an accurate depth measurement that considers the physical distance between objects in the scene. These heads are trained on metric depth datasets and are lightweight compared to the first stage.
When it comes to inference, a classifier model selects the appropriate head for each image using encoder features. This allows the model to specialize in estimating depth for specific domains or types of scenes while still benefiting from the relative depth pre-training. In the end, we get a flexible model that can be used in multiple configurations.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.