Google AI Introduces Universal Speech Model (USM): A Family of State-of-the-Art Speech Models with 2B Parameters Trained on 12 Million Hours of Speech and 28 Billion Sentences of Text
Self-supervised learning has recently made significant strides, ushering in a new age for voice recognition.
In contrast to earlier studies, which mainly concentrated on enhancing the quality of monolingual models for widely used languages, “universal” models have become more prevalent in more recent research. This could be a single model that excels at many jobs, covers many other areas, or supports many languages. The article highlights the limits of language extension.
A universal speech model is a machine learning model trained to recognize and understand spoken language across different languages and accents. It is designed to process and analyze large amounts of speech data. It can be used in various applications, such as speech recognition, natural language processing, and speech synthesis.
One famous example of a universal speech model is the Deep Speech model developed by Mozilla, which uses deep learning techniques to process speech data and convert it into text. This model has been trained on large datasets of speech data from various languages and accents and can recognize and transcribe spoken language with high accuracy.
Universal speech models are essential because they enable machines to interact with humans more naturally and intuitively and can help to bridge the gap between different languages and cultures. They have many potential applications, from virtual assistants and voice-controlled devices to speech-to-text transcription and language translation.
To increase inclusion for billions of people worldwide, Google unveiled the 1,000 Languages Initiative, an ambitious plan to develop a machine learning (ML) model to support the world’s top one thousand languages. A significant issue is how to support languages with relatively few speakers or little available data because less than twenty million people speak some of these languages. To implement this, the team performed ASR(Automatic Speech Recognition) on the data. However, there are two major problems faced by the team.
- Scalability is a problem with traditional supervised learning systems.
- Another area for improvement is that while the team increases the language coverage and quality, models must advance computationally efficiently. This necessitates a flexible, effective, and generalizable learning algorithm.
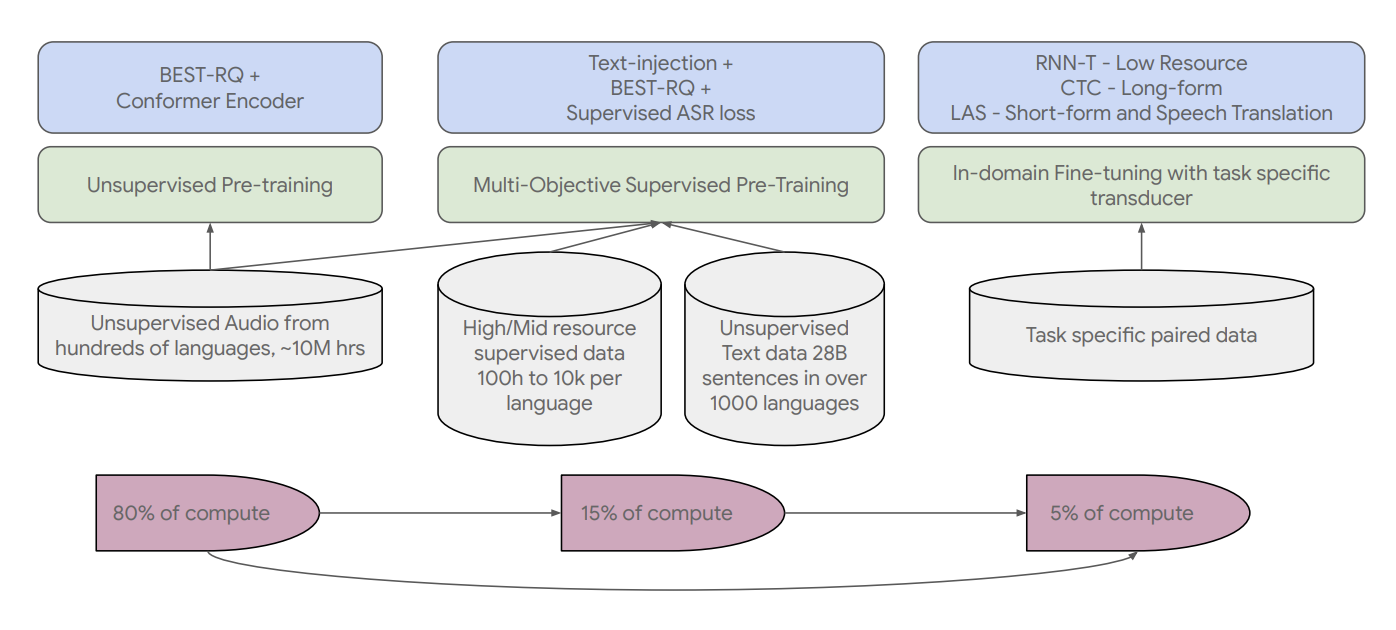
The typical encoder-decoder architecture used by USM can include a CTC, RNN-T, or LAS decoder as the decoder. USM employs the Conformer, a convolution-augmented transformer, as the encoder. The Conformer block, which includes attention, feed-forward, and convolutional modules, is the central part of the conformer. The voice signal’s log-mel spectrogram is used as the input. Convolutional sub-sampling is then used to create the final embeddings, obtained by applying a series of Conformer blocks and a projection layer.
The training process begins with a stage of unsupervised learning on speech audio that includes hundreds of different languages. The model’s quality and language coverage can be increased with an additional pre-training stage using text data in the second optional step. If text data is accessible will determine whether the second step should be included. With this second optional step, USM performs best. With minimal supervised data, the training pipeline’s final stage involves fine-tuning downstream tasks (such as automatic voice recognition or automatic speech translation).
Through pre-training, the encoder incorporates more than 300 languages. The pre-trained encoder’s efficiency is shown by fine-tuning the multilingual voice data from YouTube Caption. Less than three thousand hours of data are present in each language in the 73 languages included in the supervised YouTube data. Despite the minimal trained data, the model achieves an unprecedented benchmark of an average word error rate (WER; lower is better) of less than 30% across all 73 languages.
Creating USM is essential in achieving Google’s goal of organizing and facilitating global access to information. The scientists think that USM’s base model architecture and training pipeline provide a framework that can be developed to extend speech modeling to the subsequent 1,000 languages.
Check out the Paper, Project and Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.