Meta AI Releases MuAViC: A New Benchmark For Audio-Visual Learning For Robust Speech Translation
The performance accuracy of models employed in various speech translation tasks has greatly increased due to recent scientific advances. Although these models perform better than ever, they are still far from perfect. One of the primary reasons for this shortcoming is background noise. Different background noises, such as traffic, music, and other people speaking, make it more difficult to understand others, even in daily life. Prior studies suggest that other human senses, particularly vision, are crucial for facilitating communication in this context. For instance, if someone converses with their friend at a party, they will likely pay attention to their lip movement in order to better grasp what they are saying.
In order to replicate this human behavior in neural networks, researchers in the past have developed many Audio-Visual Speech Recognition (AVSR) techniques that translate spoken words utilizing both audio and visual inputs. Some examples of such systems include Meta AI’s publicly available AV-HuBERT and RAVen models, which integrate visual data to enhance performance for English speech recognition tasks. These deep learning-based methods have been proven to be incredibly successful at improving the robustness of speech recognition. Adding on to this wave of research in speech translation, Meta AI has now unveiled MuAViC (Multilingual Audio-Visual Corpus), the first-ever benchmark that enables the application of audio-visual learning for extremely accurate speech translation. MuAViC is a multilingual audio-visual corpus that works well for tasks requiring accurate speech recognition and speech-to-text translation tasks. The researchers at Meta claim that it is the first open benchmark for audio-visual speech-to-text translation and the largest known benchmark for multilingual audio-visual speech recognition.
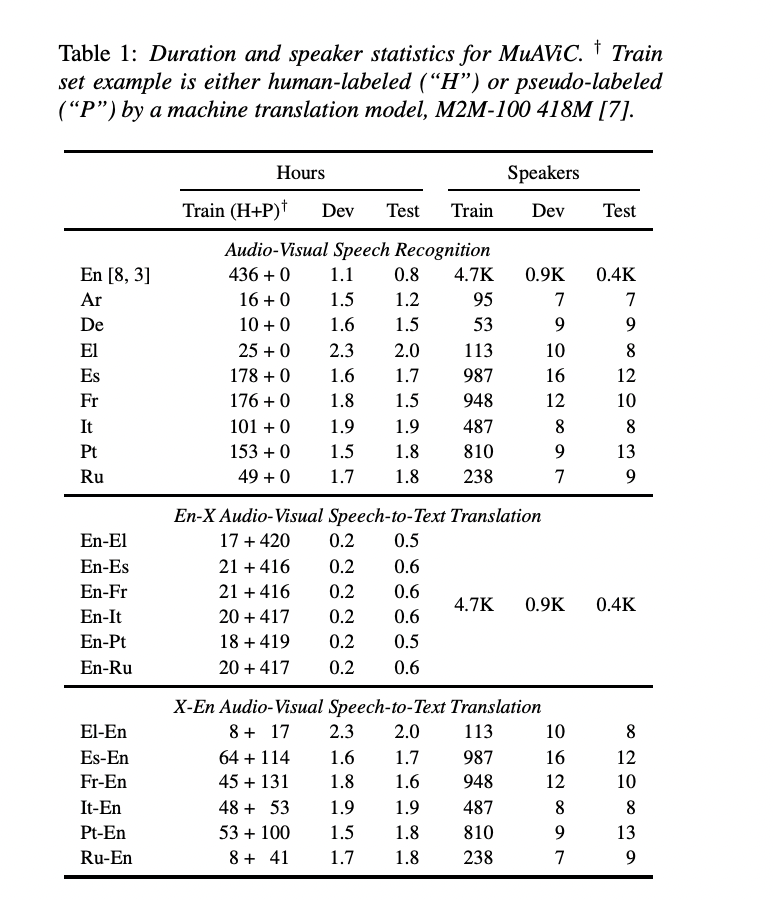
A total of 1200 hours of transcribed audio-visual speech from more than 8000 speakers in 9 languages, including English, Arabic, Spanish, French, and Russian, are included in MuAViC. This corpus, which contains text translations and establishes baselines for six English-to-X translations and six X-to-English translation directions, is derived from TED and TEDx lectures. Due to inadequate training data, the idea of extending audio-visual understanding to voice translation was previously untapped. This is where Meta researchers put significant effort into collecting and processing audio-video data.
The researchers utilized audio-visual data from the LRS3 dataset for English TED talks and then used a text-matching algorithm to align it with a corpus of machine translations. The target sentences for the matching samples were then paired with their appropriate translation labels in the machine translation corpus. To ensure the best accuracy, the researchers made sure to use the same text matching for samples from both the development set and the test set. For non-English TED talks, the researchers reused only audio data, transcriptions, and text translations collected in the speech translation dataset. They acquired the video tracks from the source recordings to add the visual component and then aligned processed video data with the audio data to produce audio-visual data.
The researchers employed MuAViC to train Meta’s AV-HuBERT architecture to create end-to-end speech recognition and translation models in noisy, challenging settings. Meta’s architecture can successfully process both modalities of an audio-video input and combine their representations into a single space that can be used for either speech recognition or translation tasks. Moreover, AV-HuBERT can still handle the given input modality, albeit less effectively, if one of the required input modalities is absent. Their model’s resistance to noise is what sets it apart. The model will rely more on the visual modality to complete the task correctly if the audio modality is distorted due to noise or other issues. Several experimental evaluations revealed that MuAViC is exceptionally effective for building noise-robust speech recognition and translation models.
Meta hopes their contribution will help the community build more robust speech recognition and translation systems in different languages. The company has always put significant efforts into speech translation research because they believe that it has the potential to bring people together by breaking down communication barriers. The researchers are extremely excited about how the research community will use MuAViC in developing systems that will contribute to solving real-world problems.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.