Meet Prismer: An Open Source Vision-Language Model with An Ensemble of Experts
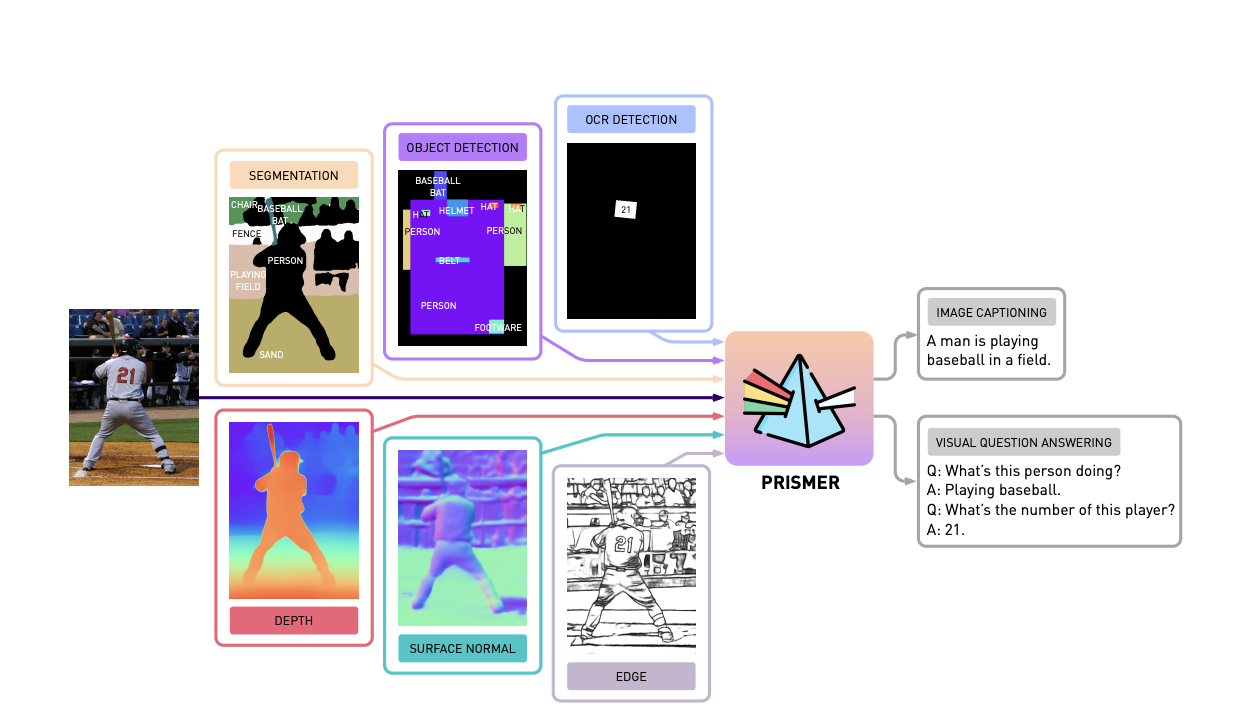
Several recent vision-language models have demonstrated remarkable multi-modal generation abilities. But typically, they call for training enormous models on enormous datasets. Researchers introduce Prismer, a data- and parameter-efficient vision-language model that uses an ensemble of domain experts, as a scalable alternative. By inheriting most of the network weights from publicly available, pre-trained domain experts and freezing them during training, Prismer only requires training a few components.
The generalization abilities of large pre-trained models are exceptional across many different tasks. However, these features come at a high price, necessitating a lot of training data and computational resources for training and inference. Models with hundreds of billions of trainable parameters are common in the language domain, and they typically necessitate a computing budget on the yottaFLOP scale.
Issues related to visual language learning are more difficult to solve. Even though this field is a superset of language processing, it also necessitates visual and multi-modal thinking expertise. Using its projected multi-modal signals, Prismer is a data-efficient vision-language model that uses a wide range of pre-trained experts. It can handle visual question answering and picture captioning, two examples of vision-language reasoning tasks. Using a prism as an example, Prismer divides a general reasoning job into several smaller, more manageable chunks.
Researchers developed a visually conditioned autoregressive text generation model toTwo of Prismer’s most important design features are I vision-only. Language-only models for web-scale knowledge to construct our core network backbones, and (ii) modalities-specific vision experts encoding multiple types of visual information, from low-level vision signals like depth to high-level vision signals like instance and semantic labels, as auxiliary knowledge, directly from their corresponding network outputs. Researchers developed a visually conditioned autoregressive text generation model to better use various pre-trained domain experts for exploratory vision-language reasoning tasks.
Even though Prismer was only trained on 13M examples of publicly available image/alt-text data, it shows strong multi-modal reasoning performance in tasks like image captioning, image classification, and visual question answering, which is competitive with many state-of-the-art vision language models. Researchers conclude with a thorough investigation of Prismer’s learning habits, where researchers find several good features.
Model Design:
The Prismer model, shown in its encoder-decoder transformer version, draws on a large pool of already-trained subject matter experts to speed up the training process. A visual encoder plus an autoregressive language decoder make up this system. The vision encoder receives a sequence of RGB and multi-modal labels (depth, surface normal, and segmentation labels anticipated from the frozen pre-trained experts) as input. It produces a sequence of RGB and multi-modal features as output. As a result of this cross-attention training, the language decoder is conditioned to generate a string of text tokens.
Advantages:
- The Prismer model has several benefits, but one of the most notable is that it uses data extremely efficiently while being trained. Prismer is constructed on top of pre-trained vision-only and language-only backbone models to achieve this goal with a considerable decrease in GPU hours necessary to attain equivalent performance to other state-of-the-art vision-language models. One may use these pre-trained parameters to use the massive amounts of available web-scale knowledge.
- Researchers also developed a multi-modal signal input for the vision encoder. The created multi-modal auxiliary knowledge can better capture semantics and information about the input image. Prismer’s architecture is optimized for maximizing the use of trained experts with few trainable parameters.
Researchers have included two varieties of pre-trained specialists in Prismer:
- Specialists in the Backbone The pre-trained models responsible for translating text and pictures into a meaningful sequence of tokens are called “vision-only” and “language-only” models, respectively.
- Depending on the data used in their training, moderators of Discourse Models may label tasks in various ways.
Properties
- The more knowledgeable people there are, the better the results. As the number of modality specialists in Prismer grows, its performance enhances.
- More Skilled Professionals, Higher Results researchers replace some fraction of the predicted depth labels with random noise taken from a Uniform Distribution to create a corrupted depth expert and assess the effect of expert quality on Prismer’s performance.
- Resistance to Unhelpful Opinions the findings further demonstrate that Prismer’s performance is steady when noise-predicting experts are incorporated.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.