Meet FlexGen: A High-Throughput Generation Engine For Running Large Language Models (LLMs) With Limited GPU Memory
Large language models (LLMs) have recently shown impressive performance on various tasks. Generative LLM inference has never-before-seen powers, but it also faces particular difficulties. These models can include billions or trillions of parameters, meaning that running them requires tremendous memory and computing power. GPT-175B, for instance, only needs 325GB of GPU RAM to load its model weights. It would take at least five A100 (80GB) GPUs and sophisticated parallelism techniques to fit this model onto GPUs. Hence, reducing the resources needed for LLM inference has recently generated a lot of interest.
LLMs are used for various “back-of-house” operations, including benchmarking, information extraction, data wrangling, form processing, and interactive use cases like chatbots. In this study, they concentrate on a situation that they refer to as throughput-oriented generative inference. The fact that these tasks frequently call for conducting LLM inference in batches across a large number of tokens such as all the papers in a company’s corpus and are less susceptible to the delay of token generation is a significant feature of these jobs. Because of this, there are possibilities to lower resource needs in certain workloads by trading off latency for better throughput.
Three approaches have been used to reduce the resources needed for LLM inference: model compression to reduce the overall memory footprint, collaborative inference to spread out the cost of inference through decentralization, and offloading to make better use of memory on the CPU and disc. Although clear limits exist, these strategies have considerably reduced the resource needs for employing LLMs. Research in the first two methods often needs help to run 175B-scale models on a single commodity GPU because it assumes that the model fits within the GPU memory. On the other hand, due to ineffective I/O scheduling and tensor placement, cutting-edge offloading-based systems in the third category cannot reach an acceptable throughput on a single GPU.
With a single commodity GPU, their main goal is to build effective offloading mechanisms for high-throughput generative inference. They can partially load an LLM and execute computation piecemeal by offloading it to secondary storage to operate an LLM with constrained GPU memory. The memory hierarchy is divided into three tiers in a typical system. Lower levels are slower but more plentiful, whereas higher levels are quicker but more scarce. Small batch sizes may cause bottlenecks in these systems. They may compromise latency in throughput-oriented scenarios by using a high batch size and distributing the expensive I/O operations over several memory hierarchies throughout a large batch of inputs overlapped with processing.
Even if they can compromise the delay, achieving high-throughput generative inference with constrained GPU memory is difficult. The first difficulty is coming up with a successful unloading plan. The plan should outline which tensors should be offloaded, where they should be offloaded in the three-level memory structure, and when during inference. Three types of tensors are used in generative inference: weights, activations, and key-value (KV) caching.
There are several ways to calculate because of the algorithm’s batch-by-batch, token-by-token, and layer-by-layer structure. These options come together to create a complicated design space. Offloading-based inference systems now in use inherit training-based methodologies that conduct excessive I/O and achieve throughput far below theoretical hardware constraints, making them some poor areas for inference. The creation of efficient compression algorithms presents the second problem. LLMs’ weights and activations have shown promising compression results in earlier publications. Nevertheless, when compression and offloading are coupled for high-throughput generative inference, additional compression strategies are driven by the I/O costs and memory reduction of the weights and KV cache.
Researchers from UCB, Stanford, CMU, Meta, Yandex, ETH and HSE jointly introduce FlexGen, an offloading framework for high-throughput LLM inference, to overcome these problems. FlexGen effectively schedules I/O activities, potential compression techniques, and distributed pipeline parallelism by combining memory from the GPU, CPU, and disc. These are the contributions they made:
- They explicitly describe a search space of potential offloading options by considering the computing schedule, tensor placement, and computation delegation. They demonstrate that their search space captures a computing order with I/O complexity within 2 of optimality. Next, they create a search algorithm based on linear programming to maximize throughput within the search space.
- They show that, without retraining or calibration, it is possible to decrease the weights and KV cache for LLMs like the OPT-175B to 4 bits with little to no accuracy loss. Fine-grained group-wise quantization, suited for lowering I/O costs and memory use during offloading, achieves this.
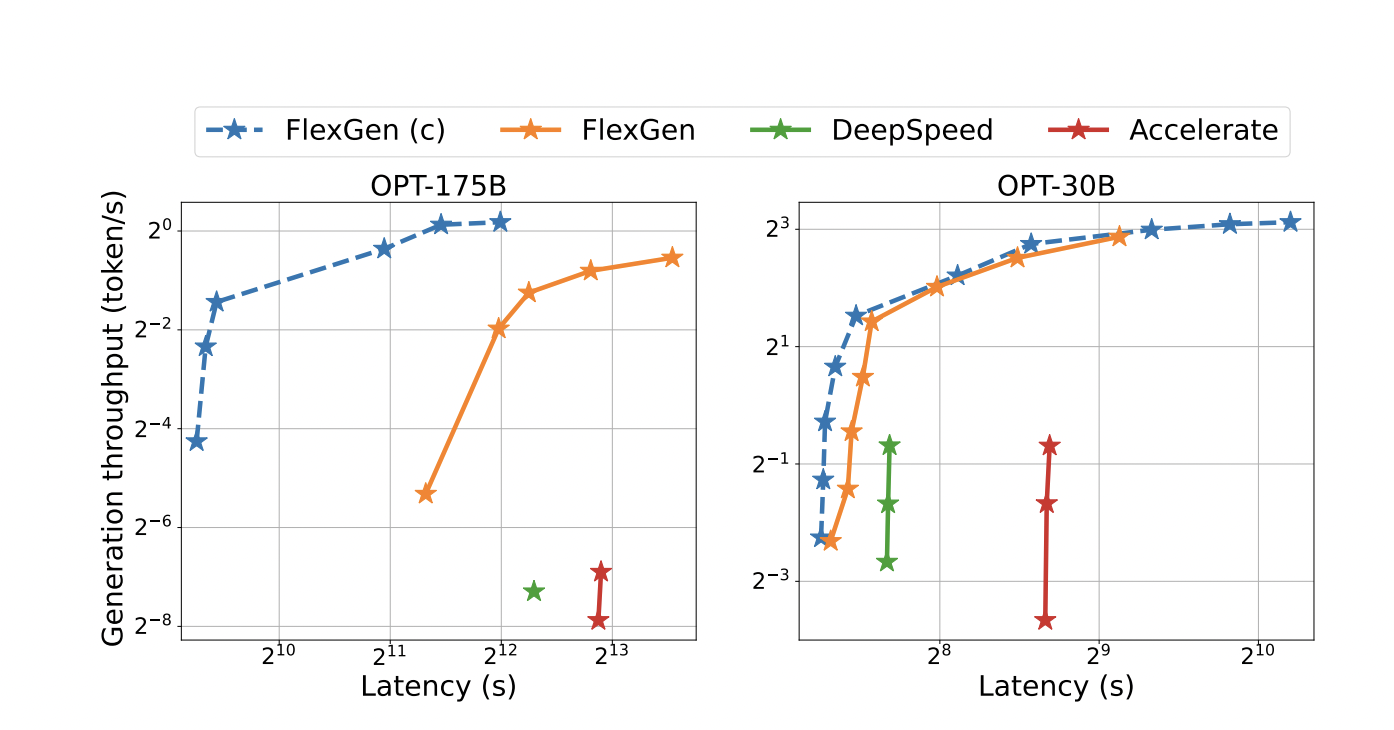
- They demonstrate the efficiency of FlexGen by running OPT-175B on NVIDIA T4 (16GB) GPUs. FlexGen often permits a bigger batch size than the two cutting-edge offloading-based inference algorithms, DeepSpeed Zero-Inference and Hugging Face Accelerate. FlexGen can accomplish substantially greater throughputs as a result.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.