This Brain-AI Research Recreates Images From Reading Brain Waves With Stable Diffusion

Building artificial systems that see and recognize the world similarly to human visual systems is a key goal of computer vision. Recent advancements in population brain activity measurement, along with improvements in the implementation and design of deep neural network models, have made it possible to directly compare the architectural features of artificial networks to those of biological brains’ latent representations, revealing crucial details about how these systems work. Reconstructing visual images from brain activity, such as that detected by functional magnetic resonance imaging (fMRI), is one of these applications. This is a fascinating but difficult problem because the underlying brain representations are largely unknown, and the sample size typically used for brain data is small.
Deep-learning models and techniques, such as generative adversarial networks (GANs) and self-supervised learning, have recently been used by academics to tackle this challenge. These investigations, however, call for either fine-tuning toward the particular stimuli utilized in the fMRI experiment or training new generative models with fMRI data from scratch. These attempts have demonstrated great but constrained performance in terms of pixel-wise and semantic fidelity, in part due to the small amount of neuroscience data and in part due to the multiple difficulties associated with building complicated generative models.
Diffusion Models, particularly the less computationally resource-intensive Latent Diffusion Models, are a recent GAN substitute. Yet, as LDMs are still relatively new, it is difficult to have a complete understanding of how they work internally.
By using an LDM called Stable Diffusion to reconstruct visual images from fMRI signals, a research team from Osaka University and CiNet attempted to address the issues mentioned above. They proposed a straightforward framework that can reconstruct high-resolution images with high semantic fidelity without the need for complex deep-learning models to be trained or tuned.
The dataset employed by the authors for this investigation is the Natural Scenes Dataset (NSD), which offers data collected from an fMRI scanner across 30–40 sessions during which each subject viewed three repeats of 10,000 images.
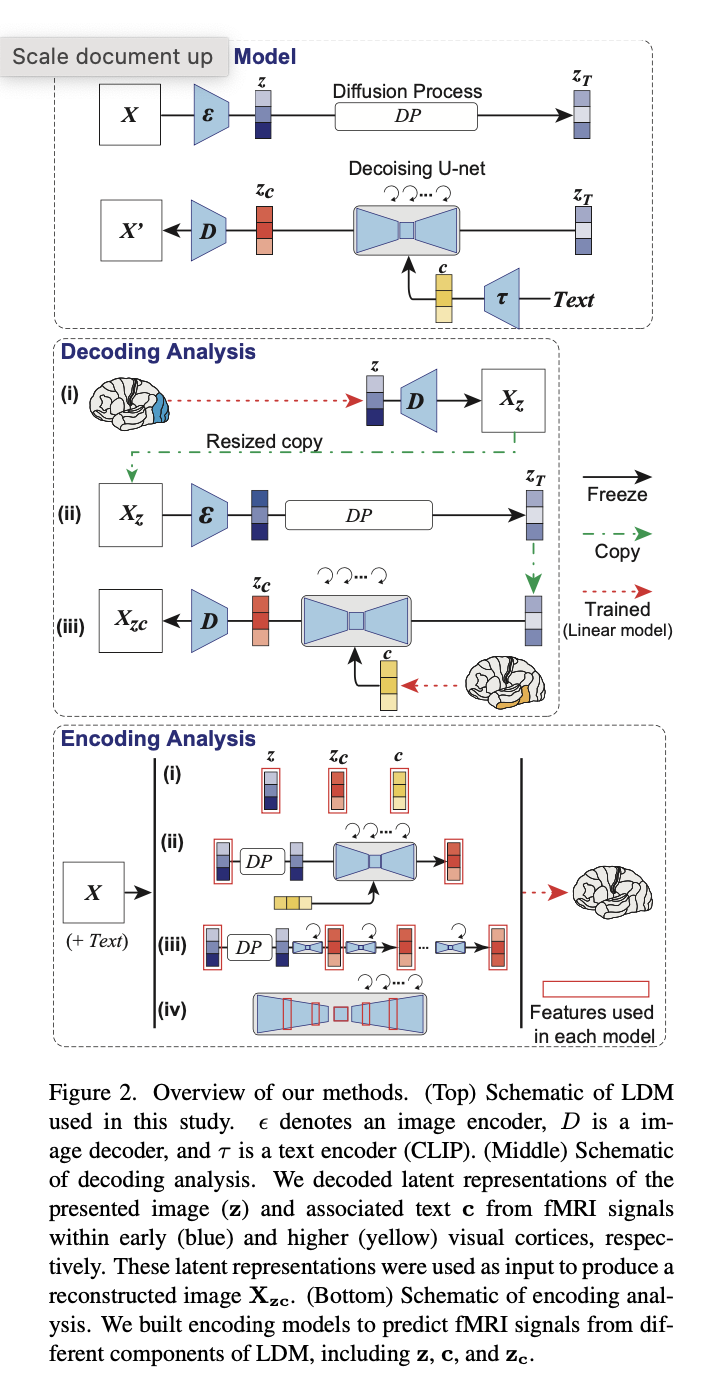
To begin, they used a Latent Diffusion Model to create images from text. In the figure above (top), z is defined as the generated latent representation of z that has been modified by the model with c, c is defined as the latent representation of texts (that describe the images), and zc is defined as the latent representation of the original image that has been compressed by the autoencoder.
To analyze the decoding model, the authors followed three steps (figure above, middle). Firstly, they predicted a latent representation z of the presented image X from fMRI signals within the early visual cortex (blue). z was then processed by a decoder to produce a coarse decoded image Xz, which was then encoded and passed through the diffusion process. Finally, the noisy image was added to a decoded latent text representation c from fMRI signals within the higher visual cortex (yellow) and denoised to produce zc. From, zc a decoding module produced a final reconstructed image Xzc. It’s important to underline that the only training required for this process is to linearly map fMRI signals to LDM components, zc, z and c.
Starting from zc, z and c the authors performed an encoding analysis to interpret the internal operations of LDMs by mapping them to brain activity (figure above, bottom). The results of reconstructing images from representations are shown below.

Images that were recreated using simply z had a visual consistency with the original images, but their semantic value was lost. On the other hand, images that were only partially reconstructed using c yielded images that had great semantic fidelity but inconsistent visuals. The validity of this method was demonstrated by the ability of images recovered using zc to produce high-resolution images with great semantic fidelity.
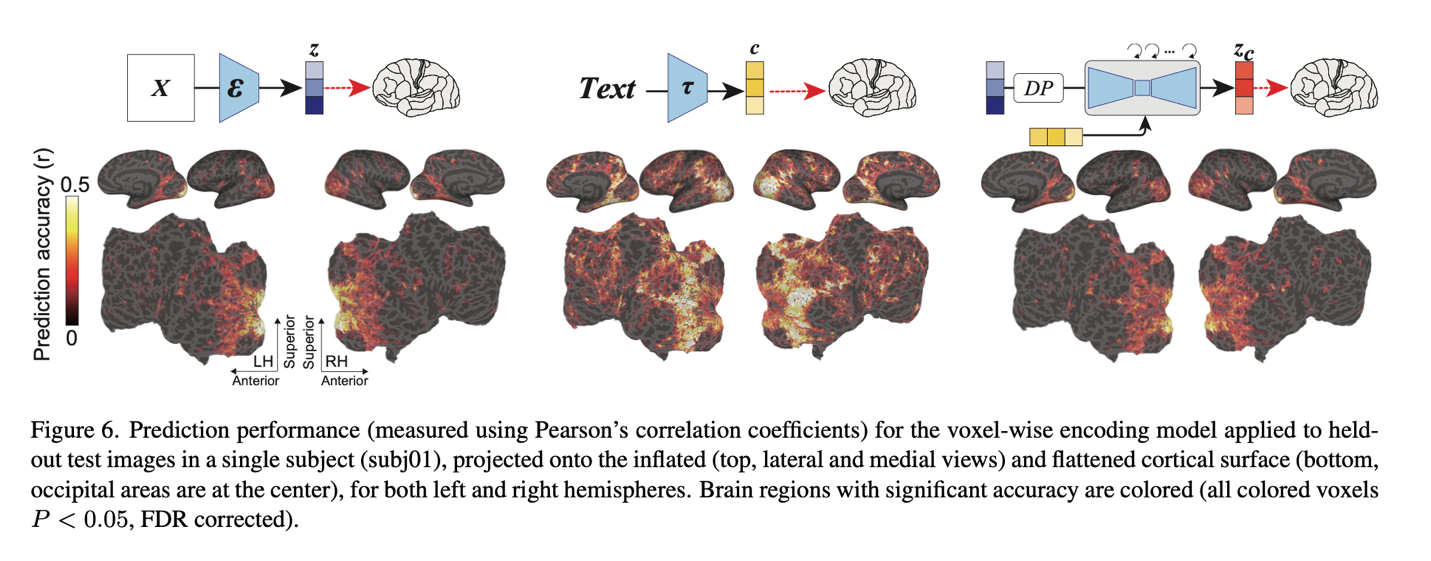
The final analysis of the brain reveals new information about DM models. At the back of the brain, the visual cortex, all three components achieved great prediction performance. Particularly, z provided strong prediction performance in the early visual cortex, which lies in the back of the visual cortex. Also, it demonstrated strong prediction values in the upper visual cortex, which is the anterior part of the visual cortex, but smaller values in other regions. On the other hand, in the upper visual cortex, c led to the best prediction performance.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Leonardo Tanzi is currently a Ph.D. Student at the Polytechnic University of Turin, Italy. His current research focuses on human-machine methodologies for smart support during complex interventions in the medical domain, using Deep Learning and Augmented Reality for 3D assistance.
Credit: Source link
Comments are closed.