UC Berkeley Researchers Propose LERF: An AI Method For Grounding Language Embeddings From Off-The-Shelf Models Like CLIP Into NeRF
In our daily lives, we frequently have to use natural language to explain our 3D surroundings. For this purpose, we make use of various properties of objects present in the physical world. They can include things like their semantics, associated entities, and overall appearance. On the other hand, when it comes to a digital setting, Neural Radiance Fields, commonly known as NeRFs, are a kind of neural network that has emerged as a powerful tool for capturing photorealistic digital representations of real-world 3D scenarios. These state-of-the-art neural networks can produce sophisticated views of even the most complicated settings using only a small collection of 2D photos.
However, one major shortcoming is associated with NeRFs, i.e., the immediate output produced by NeRFs is rather difficult to understand because it merely consists of a multicolored density field devoid of context or significance. This makes it extremely tedious for researchers to build interfaces out of these that interact with the resulting 3D scenes. For instance, Consider a scenario in which a person may find their way around a 3D environment, like his study, by inquiring where “papers” or “pens” are, for example, through normal everyday conversation. This is where integrating natural language queries with neural networks like NeRF can prove extremely helpful, as such a combination can make it very easy to navigate 3D scenarios. For this purpose, a team of postgraduate researchers at the University of California, Berkeley, have proposed a unique approach called Language Embedded Radiance Fields (LERF) for grounding language embeddings from off-the-shelf vision-language models like CLIP (Contrastive Language-Image Pre-Training) into NeRF. This method allows for using natural language to explain various ideas, including abstract concepts like electricity and visual characteristics like size, color, and other attributes. With each textual prompt, an RGB image and a relevancy map are generated in real-time, focusing on the area with the maximum relevancy activation.
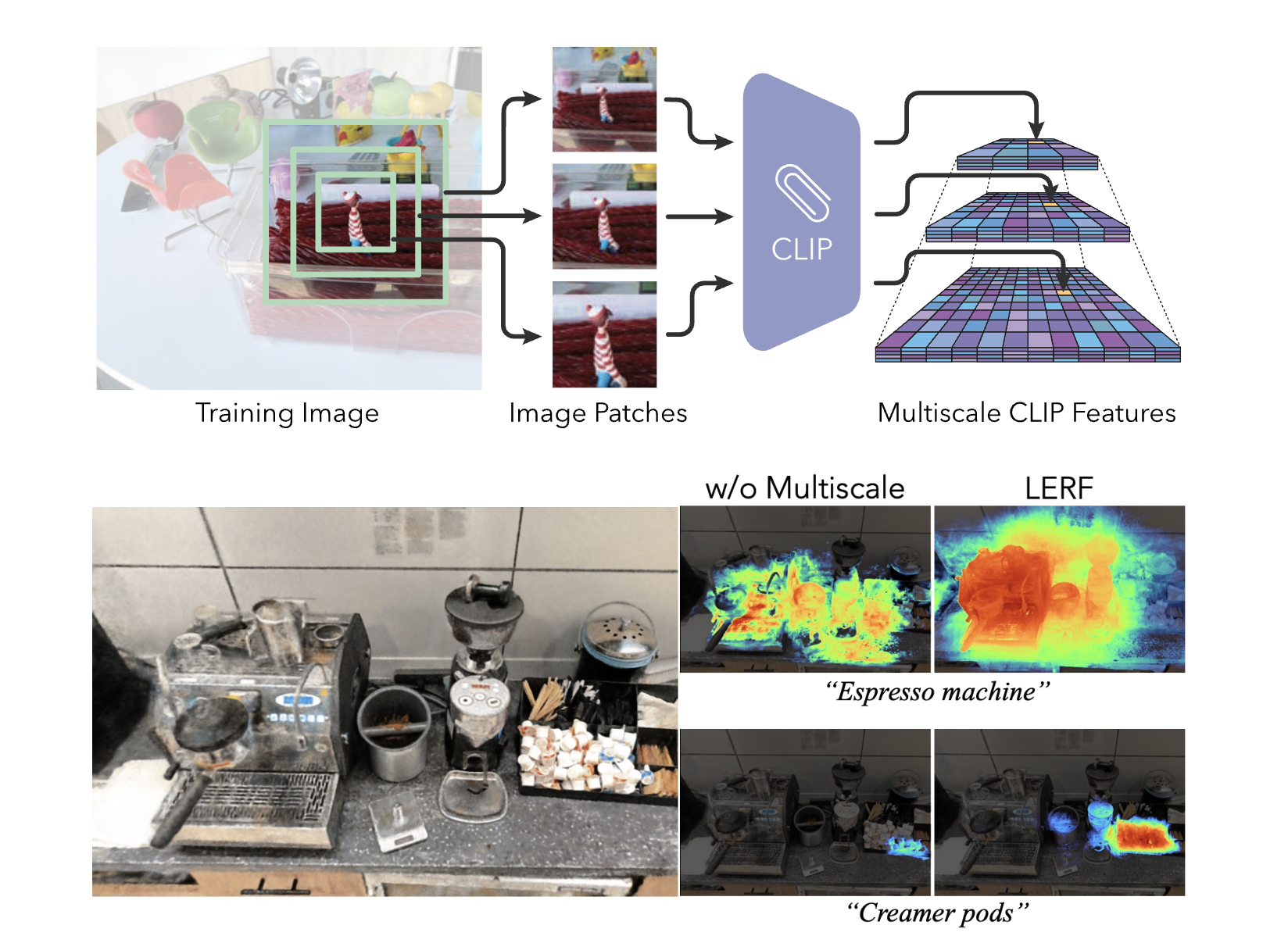
The group of Berkeley researchers constructed LERF by combining a NeRF model with a language field. This model inputs both position and physical scale in order to a single CLIP vector. During the training process. the language field is supervised using a multi-scale image pyramid that contains CLIP feature embeddings generated from the image crops of training views. This enables the CLIP encoder to capture the various context scales present in a picture, ensuring consistency across several views and connecting the same 3D position with different language embeddings. During the testing phase, the language field can be queried at arbitrary scales to obtain 3D relevancy maps in real time. This demonstrates how various elements of the same configuration are relevant to the language query. In order to regularise CLIP features, the researchers also used DINO features. Although CLIP embeddings in 3D might be sensitive to floaters and regions with sparse views, this considerably assisted in making qualitative improvements to object boundaries.
Instead of 2D CLIP embeddings, the relevancy maps resulting from text queries are obtained using 3D CLIP embeddings. This has the advantage that 3D CLIP embeddings are substantially more resistant to obstruction and changes in viewpoint than 2D CLIP embeddings. Moreover, 3D CLIP embeddings are more localized and fit better to the 3D scene structure, giving them a much cleaner appearance. In order to evaluate their approach, the team conducted several experiments on a collection of hand-captured in-the-wild scenarios and found that LERF can localize fine-grained queries relating to highly specific parts of geometry and even abstract queries relating to multiple objects. This innovative method generates 3D view-consistent relevancy maps for a variety of queries and settings. The researchers concluded that the LERF’s zero-shot capabilities had enormous potential in several areas, including robotics, decoding vision-language models, and interacting with 3D environments.
Even though LERF’s use cases have shown it to have a lot of potential, it still has several drawbacks. As a hybrid of CLIP and NeRF, it is subject to the limitations of both technologies. Capturing the spatial relationships between objects is difficult for LERF, like CLIP, and it is prone to false positives with queries that seem visually or semantically comparable. For example, “a wooden spoon” or any other such utensil. Moreover, LERF requires NeRF-quality multi-view images and known calibrated camera matrices, which are not always accessible. In a nutshell, LERF is an advanced technique for densely integrating raw CLIP embeddings into a NeRF without the need for fine-tuning. The Berkeley researchers also demonstrated that LERF significantly outperforms current state-of-the-art approaches in terms of enabling a wide variety of natural language queries across various real-world settings.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.