Unified Understanding: This AI Approach Provides a Better 3D Mapping for Robots
Developing robots that could do daily tasks for us is a long-lasting dream of humanity. We want them to walk around and help us with daily chores, improve the production in factories, increase the outcome of our agriculture, etc. Robots are the assistants we’ve always wanted to have.
The development of intelligent robots that can navigate and interact with objects in the real world requires accurate 3D mapping of the environment. Without them being able to understand their surrounding environment properly, it would not be possible to call them true assistants.
There have been many approaches to teaching robots about their surroundings. Though, most of these approaches are limited to closed-set settings, meaning they can only reason about a finite set of concepts that are predefined during training.
On the other hand, we have new developments in the AI domain that could “understand” concepts in relatively open-end datasets. For example, CLIP can be used to caption and explain images that were never seen during the training set, and it produces reliable results. Or take DINO, for example; it can understand and draw boundaries around objects it hasn’t seen before. We need to find a way to bring this ability to robots so that we can say they can actually understand their environment truly.
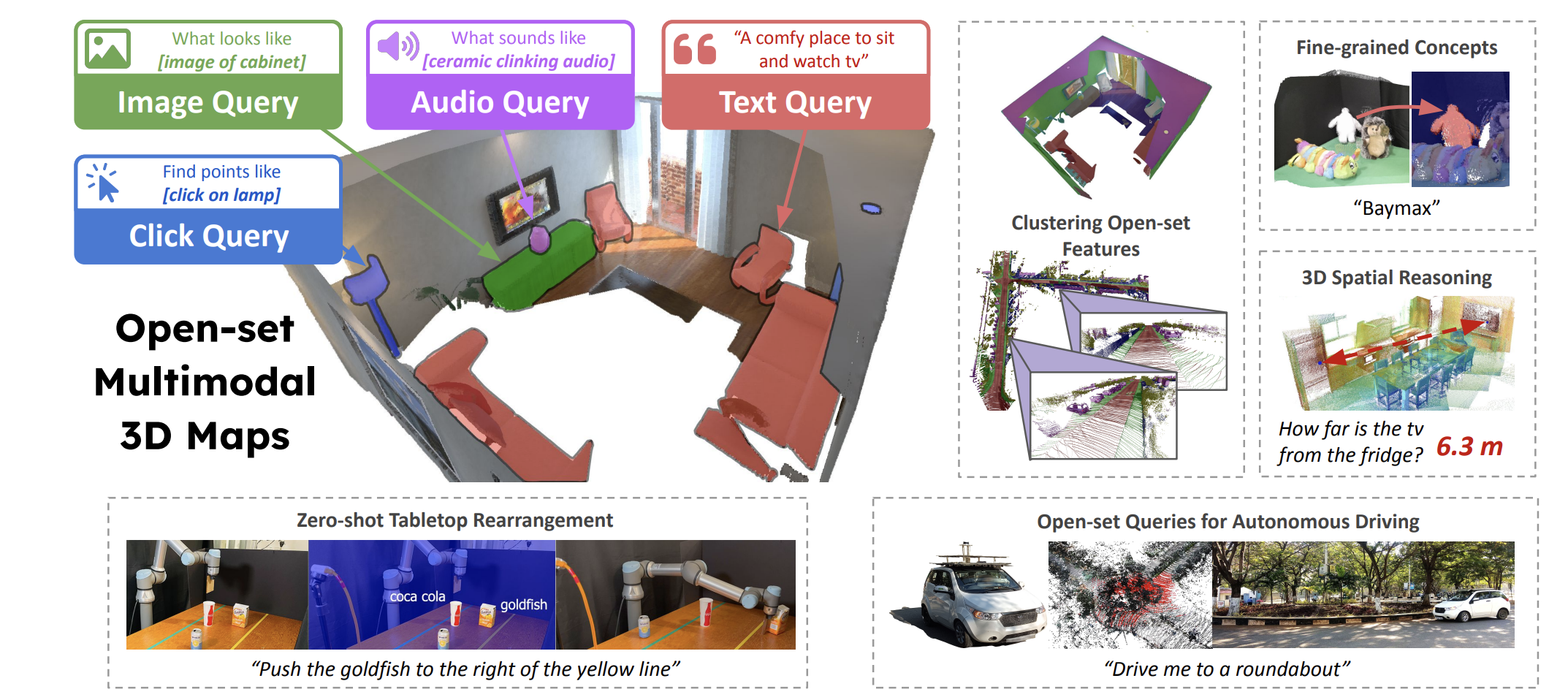
What does it require to understand and model the environment? If we want our robot to have broad applicability in a range of tasks, it should be able to use its environment modeling without the need for retraining for each new task. The modeling they do should have two main properties; being open-set and multimodal.
Open-set modeling means they can capture a wide variety of concepts in great detail. For example, if we ask the robot to bring us a can of soda, it should understand it as “something to drink” and should be able to associate it with a specific brand, flavor, etc. Then we have the multimodality. This means the robot should be able to use more than one “sense.” It should understand text, image, audio, etc., all together.
Let’s meet with ConceptFusion, a solution to tackle the aforementioned limitations.
ConceptFusion is a form of scene representation that is open-set and inherently multi-modal. It allows for reasoning beyond a closed set of concepts and enables a diverse range of possible queries to the 3D environment. Once it works, the robot can use language, images, audio, or even 3D geometry based reasoning with the environment.
ConceptFusion utilizes the advancement in large-scale models in language, image, and audio domains. It works on a simple observation; pixel-aligned open-set features can be fused into 3D maps via traditional Simultaneous Localization and Mapping (SLAM) and multiview fusion approaches. This enables effective zero-shot reasoning and does not require any additional fine-tuning or training.
Input images are processed to generate generic object masks that do not belong to any particular class. Local features are then extracted for each object, and a global feature is computed for the entire input image. Our zero-shot pixel alignment technique is used to combine the region-specific features with the global feature, resulting in pixel-aligned features.
ConceptFusion is evaluated on a mixture of real-world and simulated scenarios. It can retain long-tailed concepts better than supervised approaches and outperform existing SoTA methods by more than 40%.
Overall, ConceptFusion is an innovative solution to the limitations of existing 3D mapping approaches. By introducing an open-set and multi-modal scene representation, ConceptFusion enables more flexible and effective reasoning about the environment without the need for additional training or fine-tuning.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.