CMU Researchers Introduce Zeno: A Framework for Behavioral Evaluation of Machine Learning (ML) Models
Prototyping AI-driven systems has always been more complex. But, after using the prototype for a while, you may discover it could be more functional. A chatbot for taking notes, an editor for creating images from text, and a tool for summarising customer comments can all be made with a basic understanding of programming and a couple of hours.
In the actual world, machine learning (ML) systems can embed issues like societal prejudices and safety worries. From racial biases in pedestrian detection models to systematic misclassification of particular medical images, practitioners and researchers continually uncover substantial limitations and failures in state-of-the-art models. Behavior evaluation or testing is commonly used to discover and validate model limitations. Understanding patterns of model output for subgroups or slices of input data goes beyond examining aggregate metrics like accuracy or F1 score. Stakeholders such as ML engineers, designers, and domain experts must work together to identify a model’s expected and potential faults.
The importance of doing behavioral evaluations has been stressed extensively, although doing so remains difficult. In addition, many popular behavioral evaluation tools, such as fairness toolkits, do not support the models, data, or behaviors that real-world practitioners typically deal with. Practitioners manually test hand-picked cases from users and stakeholders to evaluate models and select the optimal deployment version properly. Models are frequently created before practitioners are familiar with the products or services for which the model will be used.
Understanding how well a machine learning model can complete a particular task is the difficulty of model evaluation. The performance of models can only be roughly estimated using aggregate indicators, much like an IQ test is only a rough and imperfect measure of human intelligence. For instance, they could fail to embed fundamental capabilities like accurate grammar in NLP systems or cover up systemic flaws like societal prejudices. The standard testing method involves calculating an overall performance metric on a subset of the data.
The difficulty of determining which features a model should possess is essential to the field of behavioral evaluation. In complicated domains, the list of requirements would be impossible to test because there could be an endless number of them. Instead, ML engineers collaborate with domain experts and designers to describe a model’s expected capabilities before it is iterated and deployed. Users contribute feedback on the model’s constraints and expected behaviors through their interactions with products and services, which is subsequently included in future model iterations.
Many tools exist for identifying, validating, and monitoring model behaviors in ML evaluation systems. The tools employ data transformations and visualizations to unearth patterns like fairness worries and edge cases. Zeno works together with other systems and combines the methods of others. Subgroup or slice-based analysis, which calculates metrics on subsets of a dataset, is the closest behavioral evaluation method to Zeno. Zeno now allows sliding-based and metamorphic testing for any domain or activity.
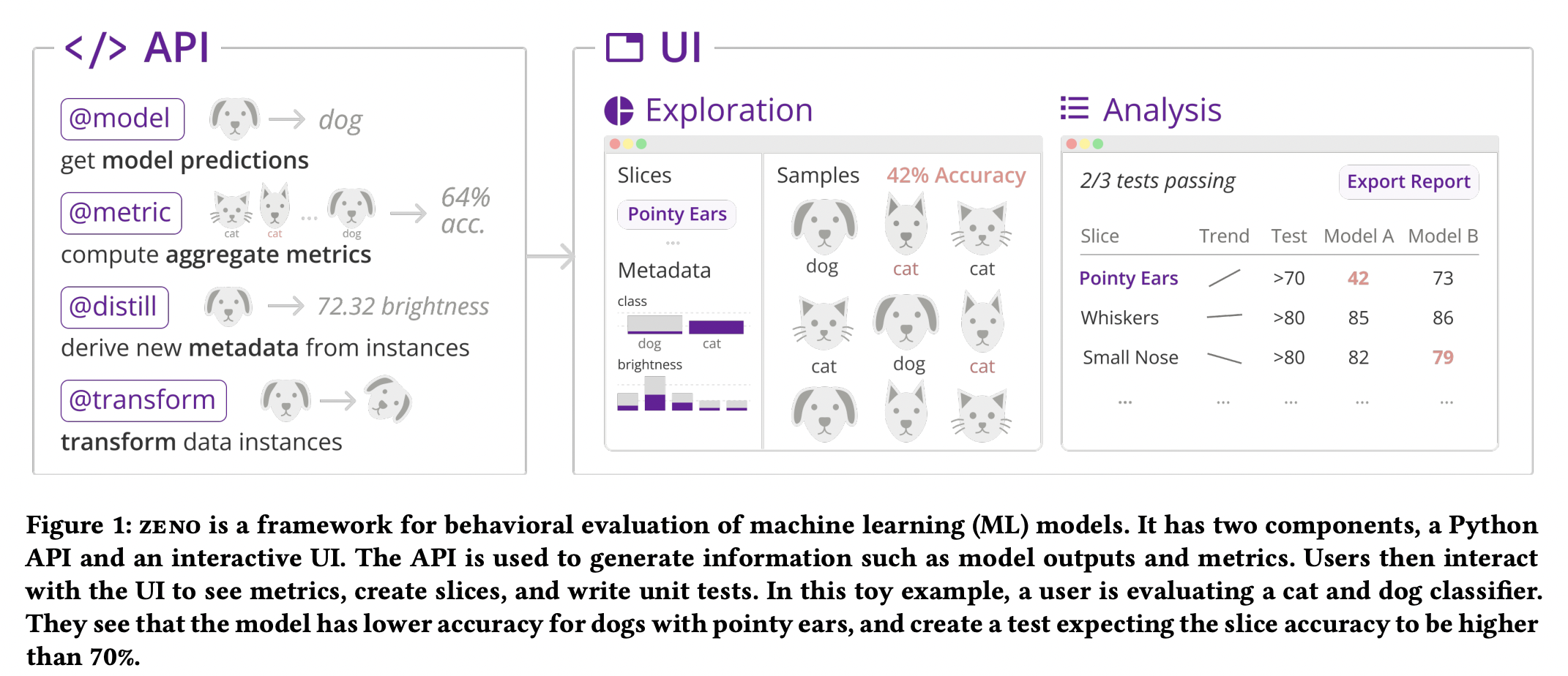
Zeno consists of a Python application programming interface (API) and a graphical user interface (GUI) (UI). Model outputs, metrics, metadata, and altered instances are only some of the fundamental components of behavioral assessment that can be implemented as Python API functions. The API’s outputs are a framework to build the main interface for conducting behavioral evaluation and testing. There are two main zeno frontend views: the Exploration UI, which is used for data discovery and slice creation, and the Analysis UI, which is used for test creation, report creation, and performance monitoring.
Zeno is made available to the public via a Python script. The built frontend, written in Svelte, employs Vega-Lite for visuals and Arquero for data processing; this library is included in the Python package. Users begin Zeno’s processing and Interface from the command line after specifying necessary settings, including test files, data paths, and column names in a TOML configuration file. Zeno’s ability to host the UI as a URL endpoint means it can be deployed locally or on a server with other computing, and users can still access it from their own devices. This framework has been tried and proven with datasets containing millions of instances. Thus it should scale well to great deployed scenarios.
The ML environment has numerous frameworks and libraries, each catering to a specific data or model. Zeno relies heavily on a Python-based model inference and data processing API that may be customized. Researchers developed the backend API for zeno as a set of Python decorator methods that can support most modern ML models, even though most ML libraries are based on Python and hence suffer from the same fragmentation.
Case studies conducted by the research team demonstrated how the API and UI of Zeno worked together to help practitioners discover major model flaws across datasets and jobs. In a broader sense, the study’s findings suggest that a behavioral evaluation framework can be useful for various data and model kinds.
Depending on the user’s needs and the difficulties of the task at hand, Zeno’s various affordances made behavioral evaluation simpler, faster, and more accurate. The participant in Case 2 used the API’s extensibility to create model-analysis metadata. Case study participants reported little to no difficulty incorporating Zeno into their existing workflows and writing code communicating with the Zeno API.
Constraints and Preventative Measures
- Knowing which behaviors are essential to end users and encoded by a model is a major difficulty for behavioral evaluation. Researchers are actively developing ZenoHub, a collaborative repository where users may share their Zeno functions and more readily locate relevant analysis components to encourage the reuse of model functions to scaffold discoveries.
- Zeno’s primary function is to define and test metrics on data slices, but the tool only offers limited grid and table views for displaying data and slices. Zeno’s usefulness might be enhanced by supporting various strong visualization methods. Users may be better able to discover patterns and novel behaviors in their data using instance views that encode semantic similarities, such as DendroMap, Facets, or AnchorViz. ML Cube, Neo, and ConfusionFlow are just some visualizations of ML performance that Zeno can modify to display model behaviors better.
- While Zeno’s parallel computation and caching let it scale to huge datasets, the size of machine learning datasets is increasing rapidly. Thus more improvements would greatly accelerate processing. Processing in distributed computing clusters using a library like Ray could be a future update.
- The cross-filtering of several histograms over very large tables is another barrier. Zeno may employ an optimization method like Falcon to facilitate real-time cross-filtering on massive datasets.
In conclusion –
Even if a machine learning model achieves great accuracy on training data, it may still suffer from systemic failures in the actual world, such as negative biases and safety hazards. Practitioners conduct a behavioral evaluation of their models, inspecting model outputs for certain inputs to identify and remedy such shortcomings. Important yet difficult, behavioral evaluation necessitates the uncovering of real-world patterns and the validation of systemic failures. Behavioral evaluation of machine learning is crucial to identify and correct problematic model behaviors, including biases and safety problems. In this study, the authors delved into the difficulties of ML evaluation and developed a universal method for scoring models in various contexts. Through four case studies in which practitioners evaluated real-world models, researchers demonstrated how Zeno might be applied across multiple domains.
Many people have high hopes for the development of AI. Nonetheless, the intricacy of their actions is developing at the same rate as their capabilities. It is essential to have robust resources to enable behavior-driven development and guarantee the construction of intelligent systems that are in harmony with human values. Zeno is a flexible platform that allows users to perform this type of in-depth examination across a wide range of AI-related jobs.
Check out the Paper and CMU Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.