Google AI Introduces PRESTO: A Dataset of Over Half a Million Contextual Multilingual Conversations Between Humans and Virtual Assistants
Recent technological breakthroughs have significantly expanded the number of ways in which artificial intelligence and machine learning can be integrated into our lives. A well-known example is the widespread use of virtual assistants like Amazon Alexa, Google Assistant, and Samsung Bixby in daily life. These virtual agents are extremely beneficial in performing even the smallest tasks, such as setting a reminder for someone’s birthday, to more complex tasks, like assisting people with disabilities in navigating their homes and other surroundings. However, even though virtual assistants are practically everywhere now, a lot of hard work and research goes into developing them behind the scenes. This category of training virtual assistants to use natural language and parse it using a model to understand the user intent and accomplish the task at hand often comes under the task-oriented dialogue parsing task. Understanding what the user wants and the information the model needs to complete that task with amazing accuracy, however, is a challenging task.
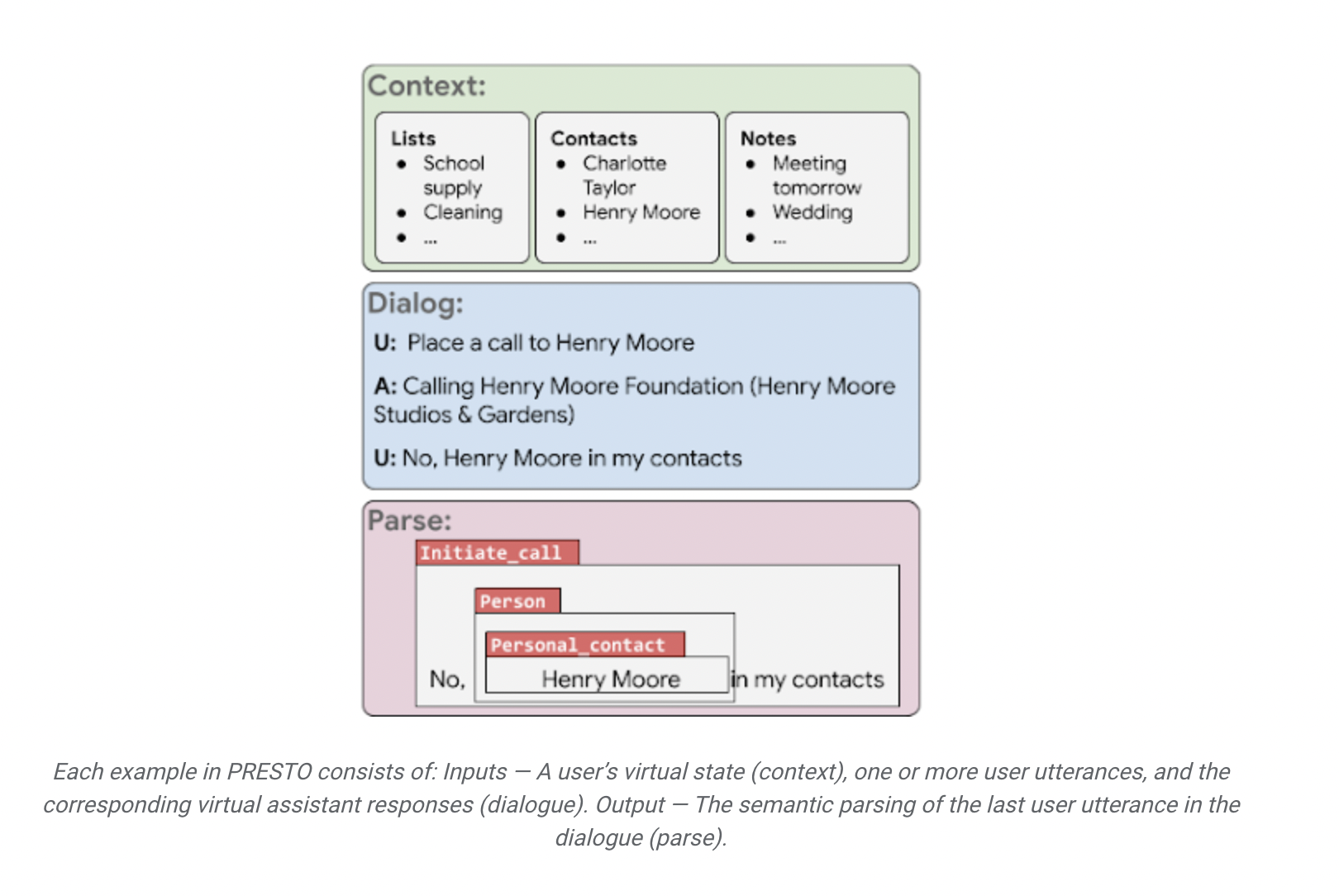
In the past, using special-purpose datasets like MultiWOZ, SMCalFlow, etc., made it possible to handle task-oriented conversations. However, experiments demonstrated several drawbacks associated with such datasets because they lack speech phenomena. These include several revisions to the user dialogue, code-mixing, and the use of structured contexts, such as notes, contacts, and so on. For instance, a virtual assistant may occasionally misinterpret the user’s context and dial the incorrect number. As a result, the user will need to rephrase their speech to correct the assistant’s error. Also, the virtual assistant must be knowledgeable enough to understand that in order to complete the work at hand successfully, it needs access to the user’s saved contacts. As a result, models developed using such datasets frequently perform poorly, which causes customer discontent in general. To solve this problem, a team from Google Research has worked on developing a new multilingual dataset, PRESTO, for parsing realistic task-oriented dialogues. The dataset includes over 550K realistic multilingual conversations between humans and virtual assistants, along with a diverse set of conversational scenarios that a user might encounter while interacting with a virtual agent. These include disfluencies, code-mixing, and user revisions. However, this is not all! PRESTO is the only large-scale human-generated conversation dataset with related structured context, such as users’ contacts and notes associated with each data point.
The PRESTO dataset spans six languages: English, French, German, Hindi, Japanese, and Spanish. One of the most commendable aspects of the dataset is that, unlike earlier datasets that solely translated utterances from English to other languages, all conversations were captured by native speakers of the languages mentioned above. This is especially useful for capturing speech patterns and other subtle differences between native speakers of different languages and English speakers when they converse. Moreover, in order to create a unique dataset, Google Researchers also included surrounding structured context. Previous interactions with virtual agents have demonstrated that users frequently use information such as notes, contacts, etc. However, if an agent cannot access these resources, parsing errors can occur, which will prompt the user to revise their utterance. To prevent this kind of user dissatisfaction, PRESTO includes three types of structured context: notes, contacts, and user utterances and their parses. These lists, notes, and contacts were created by the native speakers of each language, making it a highly unique and valuable dataset.
Moreover, assuming the need arises for a user to revise or amend their utterance while speaking to a virtual assistant. In that case, PRESTO also includes annotations that reveal which conversations had some user revision. The necessity for modifications typically results from one of two situations: either the virtual assistant misunderstood the user’s intent, or the user changed their mind mid-utterance. Having explicit annotations for such revisions significantly helps train better virtual agents by enhancing their natural language comprehension. Code-mixing is another common problem associated with utterances that PRESTO seeks to address. Past investigations have shown that many bilingual users tend to switch languages while speaking to virtual assistants. PRESTO handles this by annotating code-mixed utterances, which account for about 14% of the dataset, with the assistance of its bilingual data contributors. The dataset additionally includes conversations with disfluencies in the form of repeated phrases or filler words in all six languages to produce a more varied dataset.
For their experiments, the Google researchers employed mT5-based models that had been trained on PRESTO. To evaluate their dataset, the team developed explicit test sets to individually investigate model performance, focusing on each phenomenon: user revisions, code-switching, disfluencies, etc. The results showed that when the targeted phenomena are not included in the training set, zero-shot performance is poor, which necessitates the use of such utterances to enhance performance. Also, the findings showed that while some phenomena, like code-mixing, require a large amount of training data, others, such as user revisions and disfluencies, are simpler to model with few-shot samples.
In a nutshell, PRESTO represents a significant step forward in the study of parsing sophisticated and realistic user utterances. The dataset contains a number of conversations that superbly illustrate a range of pain points that users frequently experience in their regular talks with virtual assistants and which are missing from other datasets in the NLP field. By addressing issues that users dealing with virtual agents face daily, Google Research hopes that the academic community will use their dataset to advance the current state of natural language understanding research.
Check out the Github and Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.