Researchers from the University of Zurich Develop SwissBERT: a Multilingual Language Model for Switzerland’s Four National Languages
The famous BERT model has recently been one of the leading Language Models for Natural Language Processing. The language model is suitable for a number of NLP tasks, the ones that transform the input sequence into an output sequence. BERT (Bidirectional Encoder Representations from Transformers) uses a Transformer attention mechanism. An attention mechanism learns contextual relations between words or sub-words in a textual corpus. The BERT language model is one of the most prominent examples of NLP advancements and uses self-supervised learning techniques.
Before developing the BERT model, a language model analyzed the text sequence at the time of training from either left-to-right or combined left-to-right and right-to-left. This one-directional approach worked well for generating sentences by predicting the next word, attaching that to the sequence, followed by predicting the next to the next word until a complete meaningful sentence is obtained. With BERT, bidirectionally training was introduced, which gave a deeper sense of language context and flow compared to the previous language models.
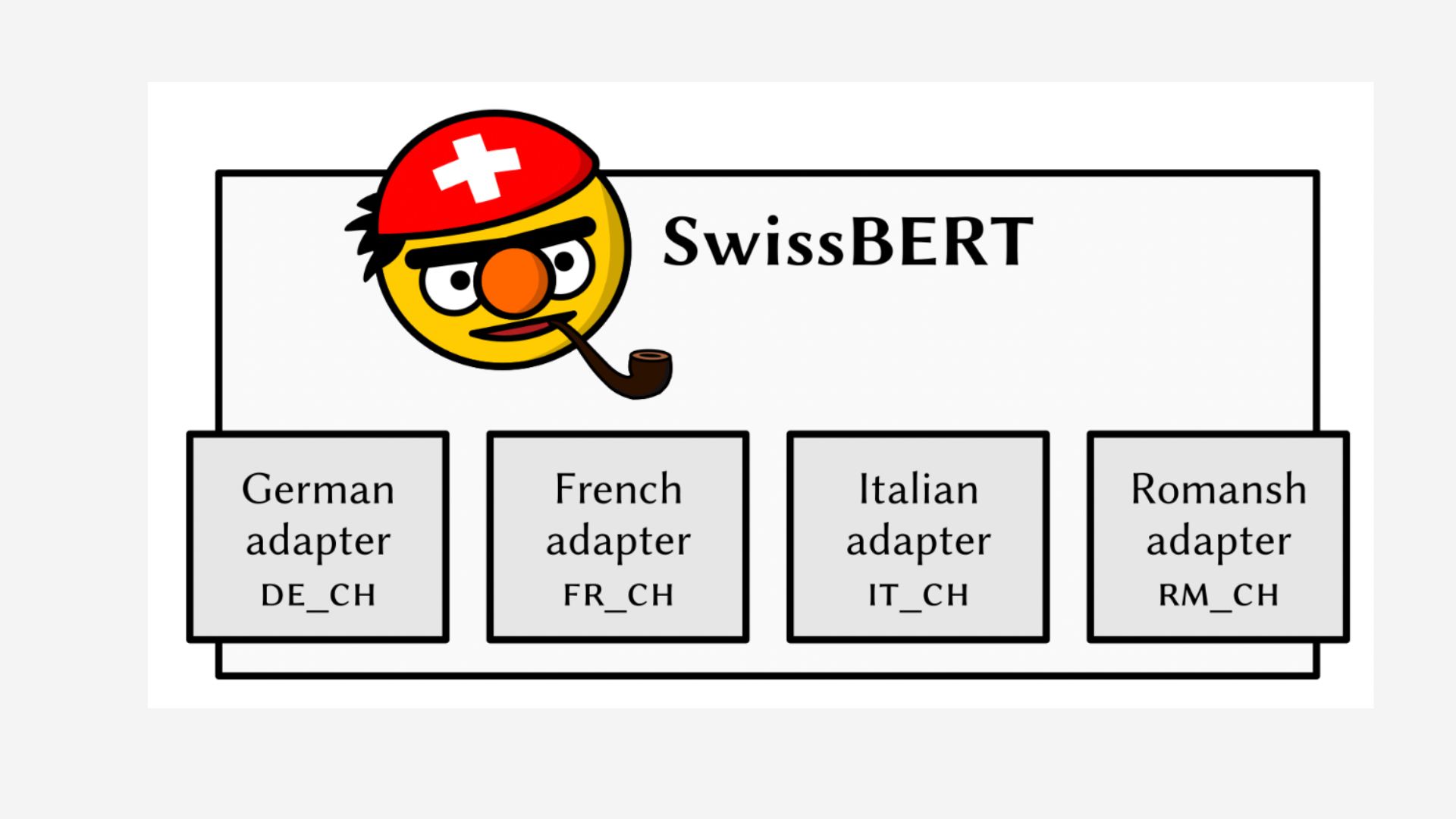
The original BERT model was released for the English language. Followed by that, other language models like CamemBERT for French and GilBERTo for Italian were developed. Recently, a team of researchers from the University of Zurich has developed a multilingual language model for Switzerland. Called SwissBERT, this model has been trained on more than 21 million Swiss news articles in Swiss Standard German, French, Italian, and Romansh Grischun with a total of 12 billion tokens.
SwissBERT has been introduced to overcome the challenges the researchers in Switzerland face due to the inability to perform multilingual tasks. Switzerland has mainly four official languages – German, French, Italian, and Romansh and individual language models for each particular language are difficult to combine for performing multilingual tasks. Also, there is no separate neural language model for the fourth national language, Romansh. Since implementing multilingual tasks is somewhat tough in the field of NLP, there was no unified model for the Swiss national language before SwissBERT. SwissBERT overcomes this challenge by simply combining articles in these languages and creating multilingual representations by implicitly exploiting common entities and events in the news.
The SwissBERT model has been remodeled from a cross-lingual Modular (X-MOD) transformer that was pre-trained together in 81 languages. The researchers have adapted a pre-trained X-MOD transformer to their corpus by training custom language adapters. They have created a Switzerland-specific subword vocabulary for SwissBERT, with the resulting model consisting of whopping 153 million parameters.
The team has evaluated SwissBERT’s performance on tasks, including named entity recognition on contemporary news (SwissNER) and detecting stances in user-generated comments on Swiss politics. SwissBERT outperforms common baselines and improves over XLM-R in detecting stance. While evaluating the model’s capabilities on Romansh, it was found that SwissBERT strongly outperforms models that have not been trained in the language in terms of zero-shot cross-lingual transfer and German–Romansh alignment of words and sentences. However, the model did not perform very well in recognizing named entities in historical, OCR-processed news.
The researchers have released SwissBERT with examples for fine-tuning downstream tasks. This model seems promising for future research and even non-commercial purposes. With further adaptation, downstream tasks can benefit from the model’s multilingualism.
Check out the Paper, Blog and Model. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.