This AI Paper Explores the Potential of Large Language Models (LLMs) for Text Annotation Tasks with a Focus on ChatGPT
High-quality labeled data are necessary for many NLP applications, particularly for training classifiers or assessing the effectiveness of unsupervised models. For instance, academics frequently seek to classify texts into various themes or conceptual categories, filter noisy social media data for relevance, or gauge their mood or position. Labeled data are necessary to provide a training set or a benchmark against which results may be compared, whether supervised, semi-supervised, or unsupervised methods are employed for these tasks. Such data may be provided for high-level tasks like semantic analysis, hate speech, and occasionally more specialized goals like party ideology.
Researchers must typically make original annotations to verify that the labels correspond to their conceptual categories. Up until recently, there were just two basic approaches. Research assistants, for example, can be hired and trained as coders by researchers. Second, they may rely on freelancers working on websites like Amazon Mechanical Turk (MTurk). These two approaches are frequently combined, with crowd-workers increasing the labeled data while trained annotators produce a tiny gold-standard dataset. Each tactic has benefits and drawbacks of its own. Training annotators often create high-quality data, although their services are expensive.
However, there have been worries about the decline in the quality of the MTurk data. Other platforms like CrowdFlower and FigureEight are no longer workable possibilities for academic research after being bought by Appen, a business-focused organization. Crowd employees are far more affordable and adaptable, but the quality might be better, especially for difficult activities and languages other than English. Researcher from University of Zurich examine large language models’ (LLMs’) potential for text annotation tasks, with a particular emphasis on ChatGPT, which was made public in November 2022. It demonstrates that, at a fraction of the cost of MTurk annotations, zero-shot ChatGPT classifications outperform them (that is, without any additional training).
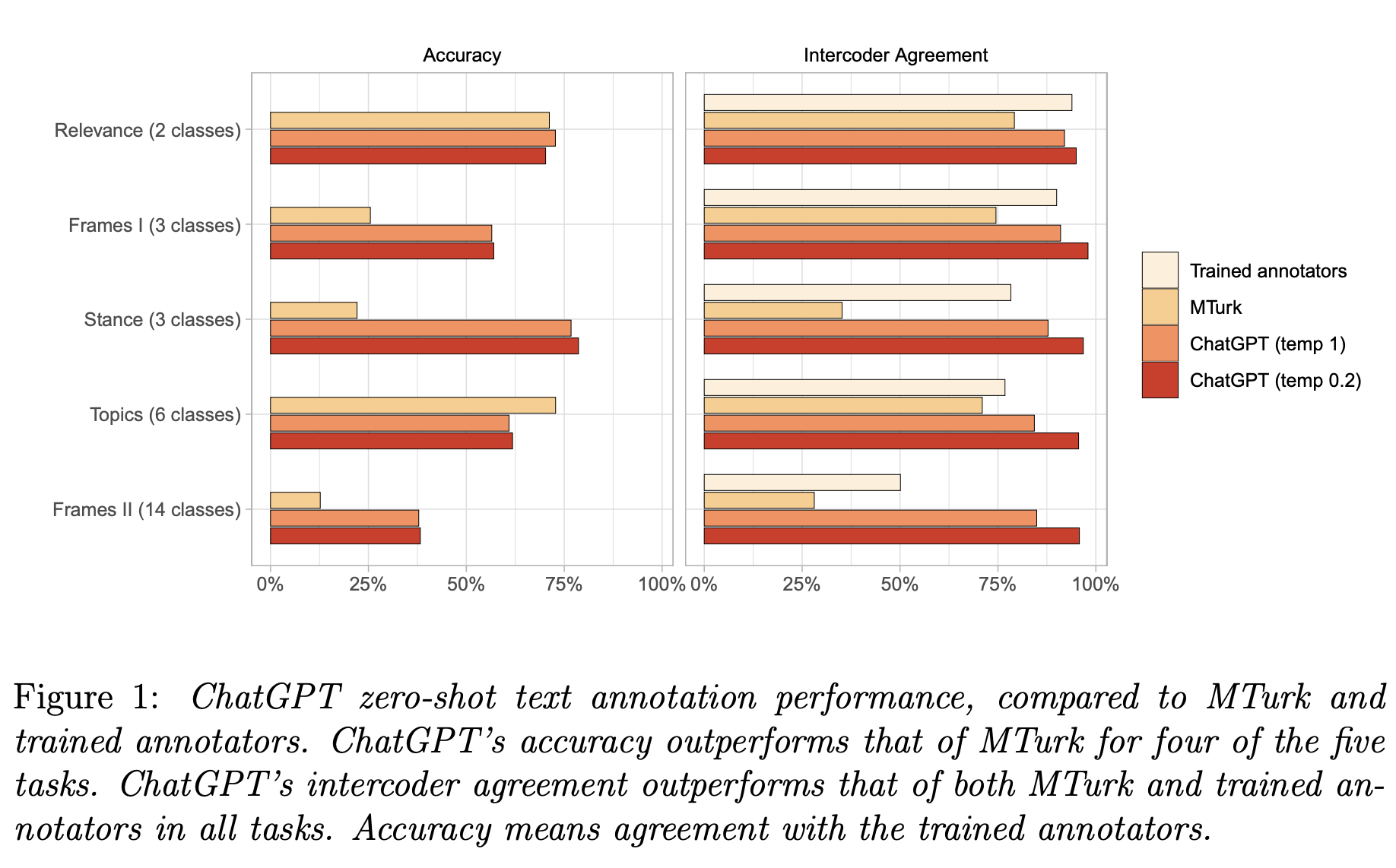
LLMs have worked very well for various tasks, including categorizing legislative ideas, ideological scaling, resolving cognitive psychology problems, and emulating human samples for survey research. Although a few investigations showed that ChatGPT would be capable of carrying out the kind of text annotation tasks they specified, to their knowledge, a thorough evaluation has yet to be carried out. A sample of 2,382 tweets that they gathered for prior research is what they used for their analysis. For that project, the tweets were annotated for five separate tasks: relevance, posture, subjects, and two types of frame identification by trained annotators (research assistants).
They distributed the jobs to MTurk’s crowd-workers and ChatGPT’s zero-shot classifications, using the identical codebooks they created to train their research assistants. After that, they assessed ChatGPT’s performance against two benchmarks: (i) its accuracy in comparison to crowd workers; and (ii) its intercoder agreement in comparison to both crowd workers and their trained annotators. They discover that ChatGPT’s zero-shot accuracy is greater than MTurk’s for four tasks. ChatGPT outperforms MTurk and trained annotators for all functions regarding the intercoder agreement.
Also, ChatGPT is far more affordable than MTurk: the five categorization jobs on ChatGPT cost roughly $68 (25,264 annotations), while the same tasks on MTurk cost $657 (12,632 annotations). Hence, ChatGPT costs only $0.003, or a third of a penny, making it roughly twenty times more affordable than MTurk while providing superior quality. It is possible to annotate whole samples at this cost or to build sizable training sets for supervised learning.
They tested 100,000 annotations and found that it would cost roughly $300. These findings show how ChatGPT and other LLMs can change how researchers conduct data annotations and upend some aspects of the business models of platforms like MTurk. However, more research is required to fully understand how ChatGPT and other LLMs perform in wider contexts.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.