Meet Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data
Natural Language Processing, or NLP, is one of the most fascinating fields in the ever-growing world of artificial intelligence and machine learning. Recent technological breakthroughs in the field of NLP have given rise to numerous impressive models employed in chat services, virtual assistants, language translators, etc., across multiple sectors. The most notable example of this is OpenAI’s conversational dialogue agent, ChatGPT, which has recently taken the world by storm. The OpenAI chatbot gained over a million users within five days of its inception because of its astonishing ability to generate insightful and versatile human-like responses to user questions originating from a variety of fields. However, there are certain shortcomings when it comes to fully accessing such kind of exceptional models. Most of these models can only be accessed via various APIs, which are frequently constrained in terms of cost, usage restrictions, and other technological limitations. This often prevents researchers and developers from realizing their full potential and slows down research and advancement in the NLP sector. Furthermore, refining and improving such models calls for large, high-quality chat corpora, which are frequently limited in number and not often publicly accessible.
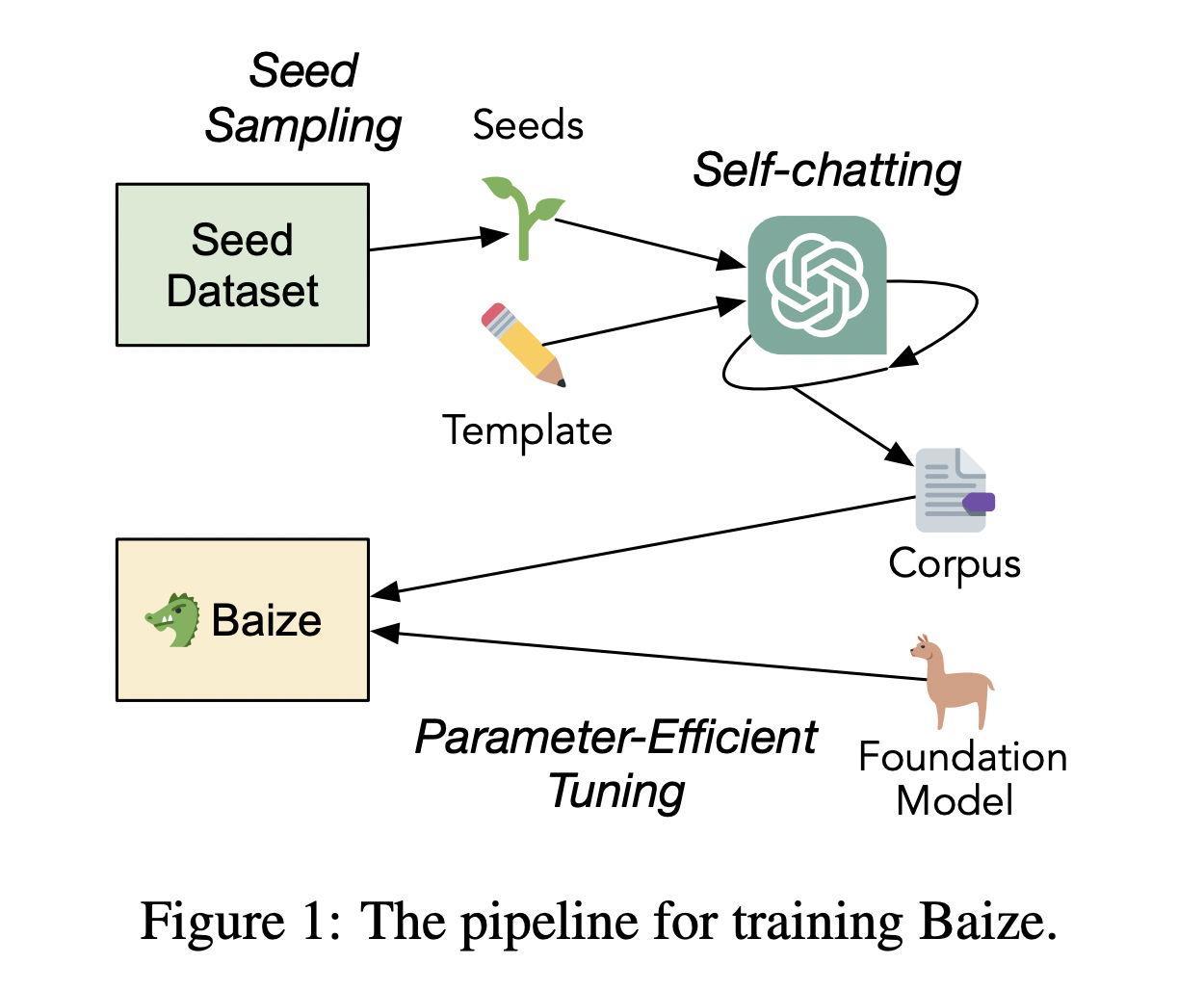
In response to this problem statement, a team of researchers from the University of California, San Diego, and Sun Yat-sen University, China, in collaboration with Microsoft Research, have developed a novel pipeline architecture that uses ChatGPT to engage in a conversation with itself in order to automatically generate a high-quality multi-turn chat corpus. Moreover, the team’s research also focuses on employing a parameter-efficient tuning strategy to optimize large language models with constrained computational resources. Using their generated chat corpus, the group of researchers fine-tuned Meta’s open-source large language model, LLaMA, resulting in a new model called Baize. This open-source chat model has exceptional performance and can function with just one GPU, making it a practical choice for many researchers with computational limitations.
In order to formulate the data collection pipeline for generating a multi-turn chat corpus, the researchers leveraged ChatGPT, which internally uses the GPT-3.5-Turbo model. The researchers used a technique known as self-chatting by enabling ChatGPT to engage in a conversation with itself to simulate both human and AI responses. On this front, the researchers used a template for the discussion format and requirements, thus, enabling the API to generate transcripts for both sides continuously. The template consists of a “seed,” which is essentially a question or a phrase that dictates the topic of the conversation. The researchers went on to explain that seeds from domain-specific datasets can be utilized to enhance a conversation-based model on a particular topic. Baize leverages over 111k dialogues generated from ChaptGPT and an additional 47k dialogue exchanges based in the healthcare domain. This pipeline was essential in providing the groundwork for producing corpora that can be used to fine-tune LLaMA for building Baize, thus improving the performance accuracy in multi-turn dialogues.
The next stage was to tune Baize using a parameter-effective tuning method. Previous studies have shown that conventional fine-tuning necessitates enormous computational resources and massive high-quality datasets. However, not all researchers have access to limitless computational resources, and the majority of these corpora are not publicly accessible. Parameter-efficient tuning is useful in this situation. With the help of such kind of fine-tuning, state-of-the-art language models can be modified to be used with minimal resources without affecting their performance. The researchers employed the Low-Rank Adaption (LoRA) approach to all layers of the LLaMA model in order to enhance its performance by increasing the number of tunable parameters and adaption capabilities.
The researchers initially considered utilizing OpenAI’s GPT-4 model to assess their model. Initial research, however, showed that the GPT-4 model prefers lengthy responses even when they are uninformative, rendering it unsuitable for evaluation. As a result, researchers are currently looking into the possibility of human assessment. The results from the human evaluation will also be included in the forthcoming revisions of their research paper. Currently, the Baize model is available in 7B, 13B, and 30B parameters, and the 60B model version will also be released soon. An online demo of the model can also be accessed here. The researchers also added that the Baize model and data are to be used for research purposes only. Its commercial use is strictly prohibited as its parent model, LLaMA, has a non-commercial license. To further improve the performance of their models, the researchers are considering how to incorporate reinforcement learning into their work in the future.
The team’s reproducible pipeline for automatically generating a multi-turn chat corpus and remarkable open-source chat model called Baize can be used to summarize their significant contributions. The group strongly hopes that their work encourages the community to progress further research and tap into previously unexplored territories when it comes to NLP research.
Check out the Paper, Repo and Demo. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.